Osa 3

- Kurssikoe tiistaina 16.12. klo 13.00-15.30 A111 ja CHE A110. Ohje kokeeseen
- Miniprojektin lopputoimenpiteet
- Laskarien muuttuminen kurssipisteiksi selviää täältä
Sisällysluettelo
Tässä osassa tutustumme ohjelmistojen laadunhallintaan ja erityisesti ketterien menetelmien suosimiin testauksen ja laadunhallinnan menetelmiin.
Typoja materiaalissa
Tee korjausehdotus editoimalla tätä tiedostoa GitHubissa.
Kurssipalaute
Kurssilla on käytössä normaalin lopussa kerättävän palautteen lisäksi ns. jatkuva palaute: voit antaa milloin vain kurssihenkilökunnalle anonyymiä palautetta osoitteessa https://norppa.helsinki.fi/targets/95023982/feedback
Laadunhallinnan peruskysymykset: verifiointi ja validointi
Ohjelmiston laadunhallintaan liittyy oleellisena asiana verifiointi ja validointi.
Verifioinnissa pyritään varmistamaan, että ohjelmisto toteuttaa vaatimusmäärittelyn aikana sille asetetut vaatimukset. Yleensä tämä tapahtuu testaamalla, että ohjelma toteuttaa vaatimusmäärittelyyn kirjatut toiminnalliset ja ei-toiminnalliset vaatimukset. Verifiointi siis pyrkii vastaamaan kysymykseen are we building the product right.
Validointi taas pyrkii varmistamaan, että ohjelmisto täyttää käyttäjän odotukset ja tarpeet. Vaatimusmäärittelyn aikana kirjatut ohjelmiston vaatimukset eivät ole aina se mitä käyttäjä todella tarvitsee. Validointiin liittyvä oleellinen kysymys onkin are we building the right product, eli ollaanko ylipäätään tekemässä oikeaa järjestelmää kulloiseenkin käyttötarkoitukseen.
Verifioinnin ja validoinnin tavoitteena on varmistaa, että ohjelma on riittävän hyvä siihen käyttötarkoitukseen, mihin ohjelma on tarkoitettu. Hyvyys on suhteellista ja riippuu ohjelman käyttötarkoituksesta. Ohjelman ei tarvitse yleensä olla täysin virheetön ollakseen kuitenkin riittävän hyvä käyttötarkoitukseensa.
Verifioinnin ja validoinnin suorittamista käytetään yleisesti nimitystä laadunhallinta (engl. quality assurance, QA). Jos laadunhallinta on erillisen tiimin vastuulla, käytetään tästä usein nimitystä QA-tiimi.
Laadunhallinnan tekniikat
Perinteisesti laadunhallinnassa on käytetty kahta erihenkistä tekniikkaa, katselmointeja/tarkastuksia sekä testausta.
Katselmoinnissa (engl. review) käydään läpi ohjelmiston tuotantoprosessin aikana syntyneitä dokumentteja sekä ohjelmakoodia, ja etsitään näistä erilaisia ongelmia.
Tarkastukset (engl. inspection) taas ovat katselmoinnin muodollisempi versio. Tarkastus suoritetaan järjestämällä formaali kokous, jolla on tarkkaan määritelty agenda ja kokouksen osallistujilla ennalta määritellyt roolit. Tarkastukset kuuluvat vesiputousmallin maailmaan, eikä niitä nykyään juuri suosita lukuun ottamatta turvallisuuskriittisten järjestelmien kehitystä.
Katselmointi on staattinen tekniikka, suorituskelpoista ohjelmakoodia ei välttämättä tarvita. Jos kohteena on ohjelmakoodi, ohjelmaa ei yleensä suoriteta katselmoinnin yhteydessä.
Testaus taas on dynaaminen tekniikka, joka edellyttää aina ohjelmakoodin suorittamista. Testauksessa tarkkaillaan, miten ohjelma reagoi annettuihin testisyötteisiin.
Vaatimusten validointi
Validointi siis vastaa kysymykseen, ollaanko tekemässä asiakkaan tarpeiden kannalta oikeanlaista järjestelmää.
Ohjelmistolle määritellyt vaatimukset onkin validoitava, eli on varmistettava, että määrittelydokumentti kuvaa sellaisen ohjelmiston, joka vastaa asiakkaan tarpeita.
Vesiputousmallissa määrittelydokumenttiin kirjattujen vaatimusten validointi suoritetaan nimenomaan katselmoimalla. Vaatimusmäärittely päättyy siihen, että asiakas katselmoi määrittelydokumentin ja varmistaa, että kirjatut vaatimukset vastaavat asiakkaan mielikuvaa tilattavasta järjestelmästä. Vesiputousmallia sovellettaessa määrittelydokumentti jäädytetään katselmoinnin jälkeen ja sen muuttaminen vaatii yleensä monimutkaista prosessia, ja saattaa edellyttää uutta sopimusta asiakkaan ja sovelluksen toimittajan kesken.
Ketterässä ohjelmistotuotannossa vaatimusten validointi tapahtuu iteraation päättävien demonstraatioiden (Scrumissa sprint reviewin) yhteydessä.
Asiakkaalle näytetään toimivaa versiota ohjelmistosta ja asiakas voi itse verrata vastaako lopputulos sitä mitä asiakas lopulta haluaa. Asiakkaan tarvitsema toiminnallisuushan voi poiketa ennen iteraatiota määritellystä toiminnallisuudesta ja/tai ohjelmistokehittäjät saattavat tulkita väärin user storyjen kuvaamia vaatimuksia.
Jos asiakas havaitsee, että sovellus ei ole etenemässä haluttuun suuntaan, eli kirjatut vaatimukset eivät vastanneet todellista tarvetta, tarve on muuttunut tai vaatimuksia on tulkittu väärin, on seuraavassa iteraatiossa mahdollista ottaa korjausliike.
On ilmeistä, että ketterän mallin käyttämä vaatimusten validointitapa toimii paremmin tuotekehitystä muistuttavissa tilanteissa, joissa ollaan tekemässä tuotetta, joka on vaikea määritellä tarkkaan etukäteen.
Koodin katselmointi
Koodin katselmointi eli koodin lukeminen jonkun muun kuin ohjelmoijan toimesta on havaittu erittäin tehokkaaksi keinoksi koodin laadun parantamisessa. Katselmoinnin avulla voidaan havaita koodista ongelmia, joita on vaikea havaita testaamalla, esim. noudattaako koodi sovittua tyyliä ja onko se ylläpidettävää.
Koodin katselmoinnissa on perinteisesti käyty koodia läpi varmistaen, ettei siitä löydy erilaisissa checklisteissä lueteltuja riskialttiita piirteitä. Esimerkiksi eräs c-kielisten ohjelmien katselmoinnin checklist löytyy täältä. Joissakin kielissä, esim. Javassa, kääntäjän tekemät tarkastukset tekevät osan linkin takana olevan listan tarkistuksista turhaksi.
Nykyään on useita paljon katselmointia automatisoivia staattista analyysiä tekeviä työkaluja, esimerkiksi JavaScript-ekosysteemissä ESlint ja Pythonin Pylint, johon tutustuttiin jo viikon 2 laskareissa.
Staattinen analyysi pilvessä
Pilvipalvelut ovat helpottaneet sovelluskehittäjien työtä monissa asioissa, esim. GitHubin ansiosta omaa versionhallintapalvelinta ei ole tarvinnut ylläpitää vuosiin.
Pilveen on viime aikoina ilmestynyt myös koodille staattista analyysiä tekeviä palveluita, esimerkiksi Qlty, joka analysoi koodista mm. seuraavia asioita:
- koodissa oleva turha monimutkaisuus
- koodissa olevat tietoturvariskit
- copy paste -koodi
- testaamaton koodi
Minkä tahansa GitHubissa olevan projektin saa konfiguroitua Qltyn tarkastettavaksi nappia painamalla. Qlty suorittaa tarkastukset koodille aina kun uutta koodia pushataan GitHubiin.
Helsingin yliopistossa oppimisanalytiikkaan käytettävän Oodikone-sovelluksen yleisraportti näyttää seuraavalta:
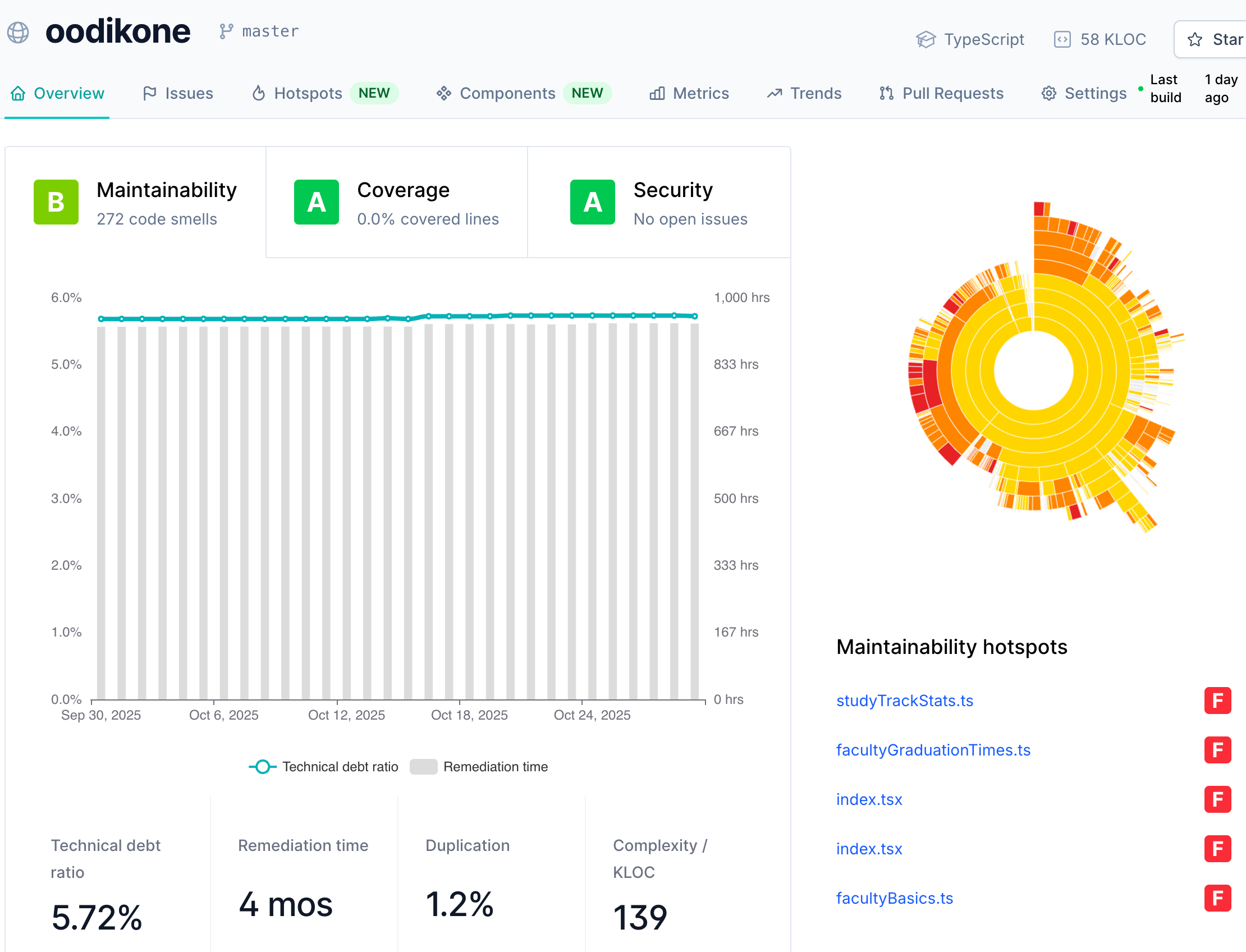
Sovelluksen ylläpidettävyyden arvosana on B, eli toisiksi korkein, tietoturvaan liittyviä ongelmia ei ole havaittu. Qlty arvioi sovelluksessa olevan teknisen velan takaisinmaksuajaksi vajaat 1000 tuntia. Oikealla oleva diagrammi näyttää sovelluksen koodin ylläpidettävyyden hotspotit, eli sovelluksen osat, jotka kaipaisivat eniten koodin huoltotoimia.
Qlty tarjoaa paljon erilaisia näkymiä. Koodin ylläpidettävyyttä voidaan tarkastella monella tasolla. Seuraava paljastaa, että hakemistoissa faculty ja studyProgramme oleva koodi kaipaa kenties parantelua:
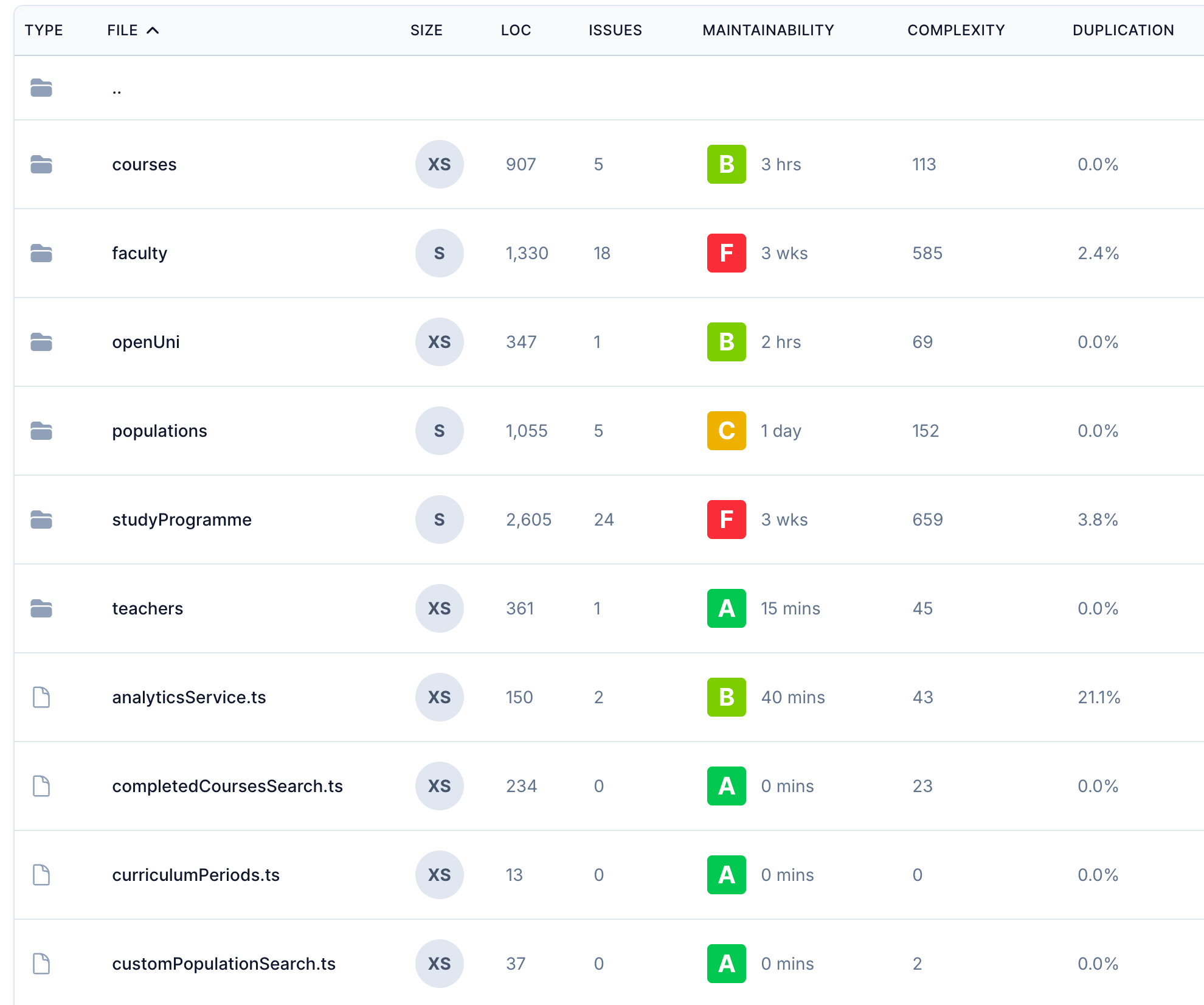
Vastaavia palveluita on olemassa useita, mm. SonarQube ja Codacy. Staattisen analyysin työkalut mainostavat yhä enenevissä määrin olevansa AI:lla tehostettuja. Esim. Qlty tarjoaa mahdollisuuden AI:n generoimiin korjausehdotuksiin.
Koodin katselmointi: GitHub ja pull requestit
Yhä enenevä määrä ohjelmistokehitysprojekteista tallettaa sovelluksen lähdekoodin GitHubiin. GitHubin pull requestit tarjoavatkin hyvän ja paljon käytetyn työkalun koodikatselmointien tekoon.
Pull requesteja käytettäessä työn kulku on seuraava:
- Sovelluskehittäjä forkkaa repositorion itselleen, tekee muutokset omaan repositorioon ja tekee pull requestin projektia hallinnoivalle taholle.
- Hallinnoija, esimerkiksi tiimin senior developer, open source -projektin vastaava tai joku muu sovelluskehittäjä tekee katselmoinnin pull requestille.
- Jos koodi ei ole vielä siinä kunnossa, että tehdyt muutokset voidaan liittää repositorioon, hallinnoija kirjoittaa pull requestin tekijälle joukon parannusehdotuksia.
- Muutosten ollessa hyväksyttävästi tehtyjä, pull request mergetään eli yhdistetään päärepositorioon.
Seuraavassa esimerkki TMC-projektiin tehdystä pull requestista ja siihen liittyvistä kommenteista:
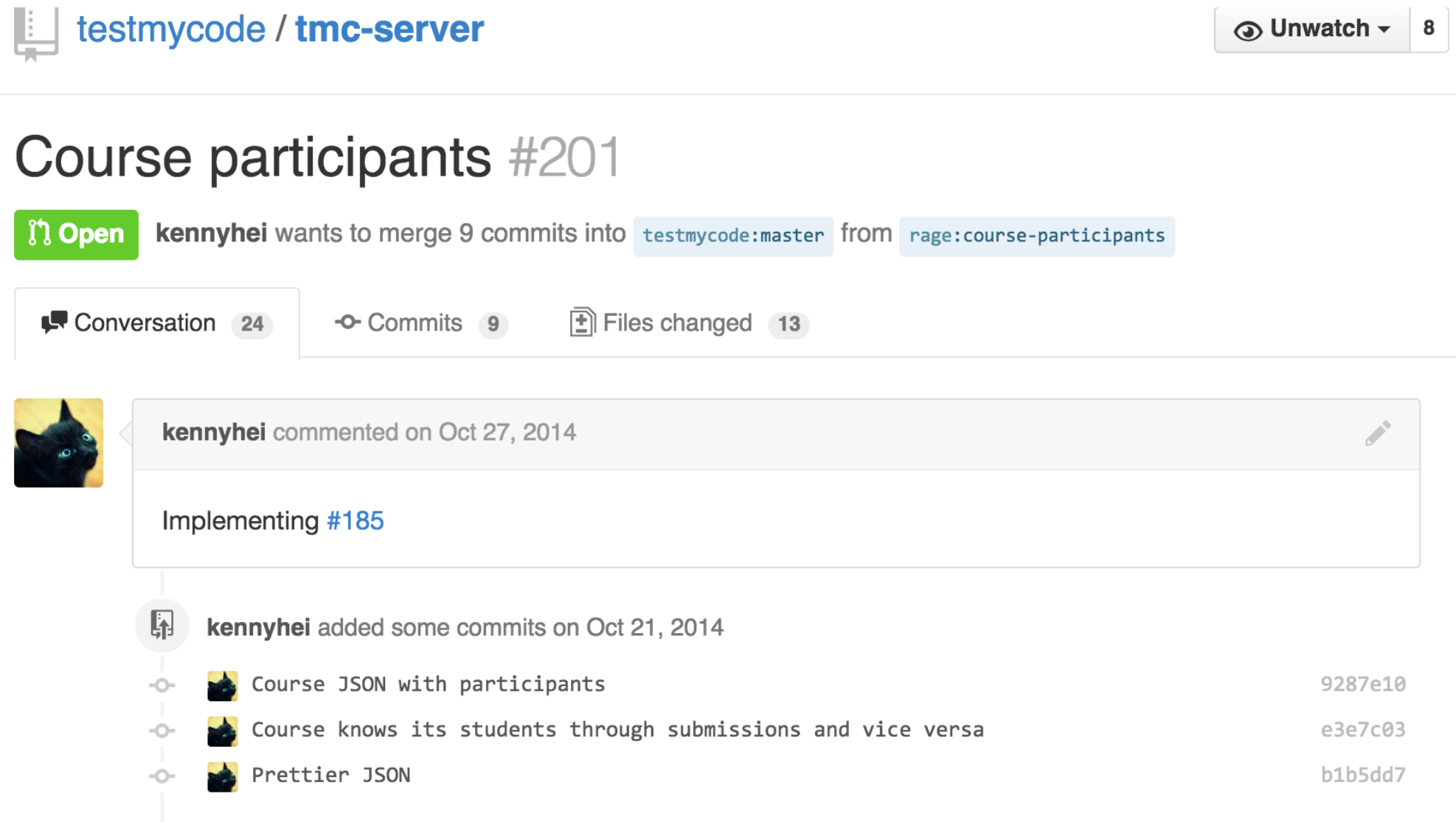
Pull requestin kommentissa sovelluskehittäjä toteaa, että pull requestin sisältämät commitit toteuttavat tämän GitHub-issuen kuvaaman toiminnallisuuden.
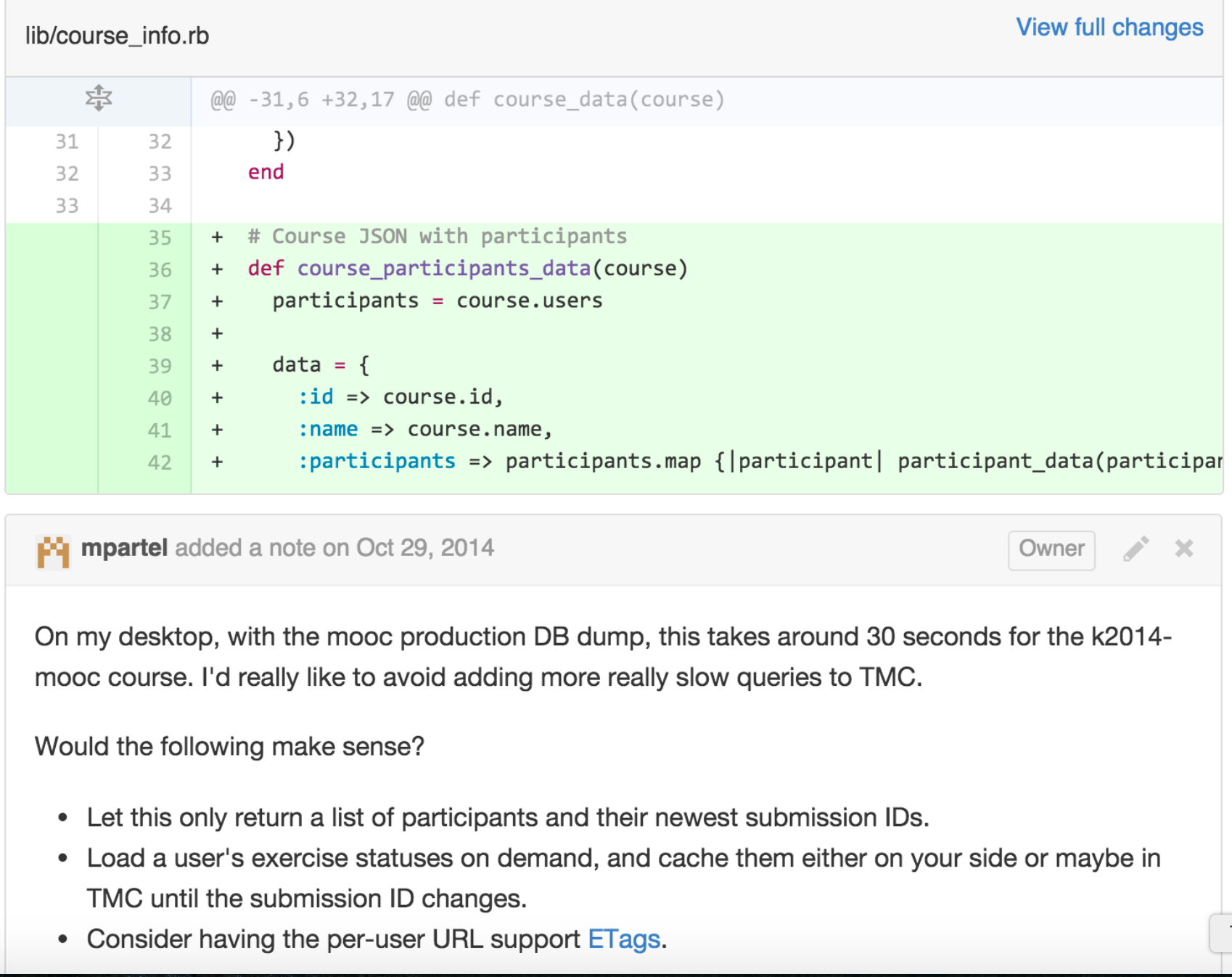
TMC:n silloinen pääkehittäjä ei kuitenkaan hyväksy muutoksia vielä mergettäväksi, vaan antaa muutaman parannusehdotuksen sovelluskehittäjälle.
Nykyään moni ohjelmistokehitystiimi käyttää säännöllisesti pull requesteja ja on jopa kirjannut definition of doneen, että yksi valmiin kriteereistä on, että joku muu kuin toteuttaja on katselmoinut koodin. Katselmoija voi olla joko toinen sovelluskehittäjä, tai aloittelevien koodareiden tapauksessa joku hieman seniorimpi tiimin jäsen.
AI:n hyödyntäminen koodin katselmoinnissa
GitHubissa on mahdollista pyytää Copilotia tekemään koodikatselmointi pull requesteille. Vibe-koodasin ohtuvarastoon interaktiivisen käyttöliittymän, ja tein lisäyksestä pull requestin, jonka pyysin Copilotin katselmoimaan. Katselmoinnin yleiskatsaus näyttää seuraavalta

Copilot antaa myös detaljoidumpia kommentteja sekä parannusehdotuksia
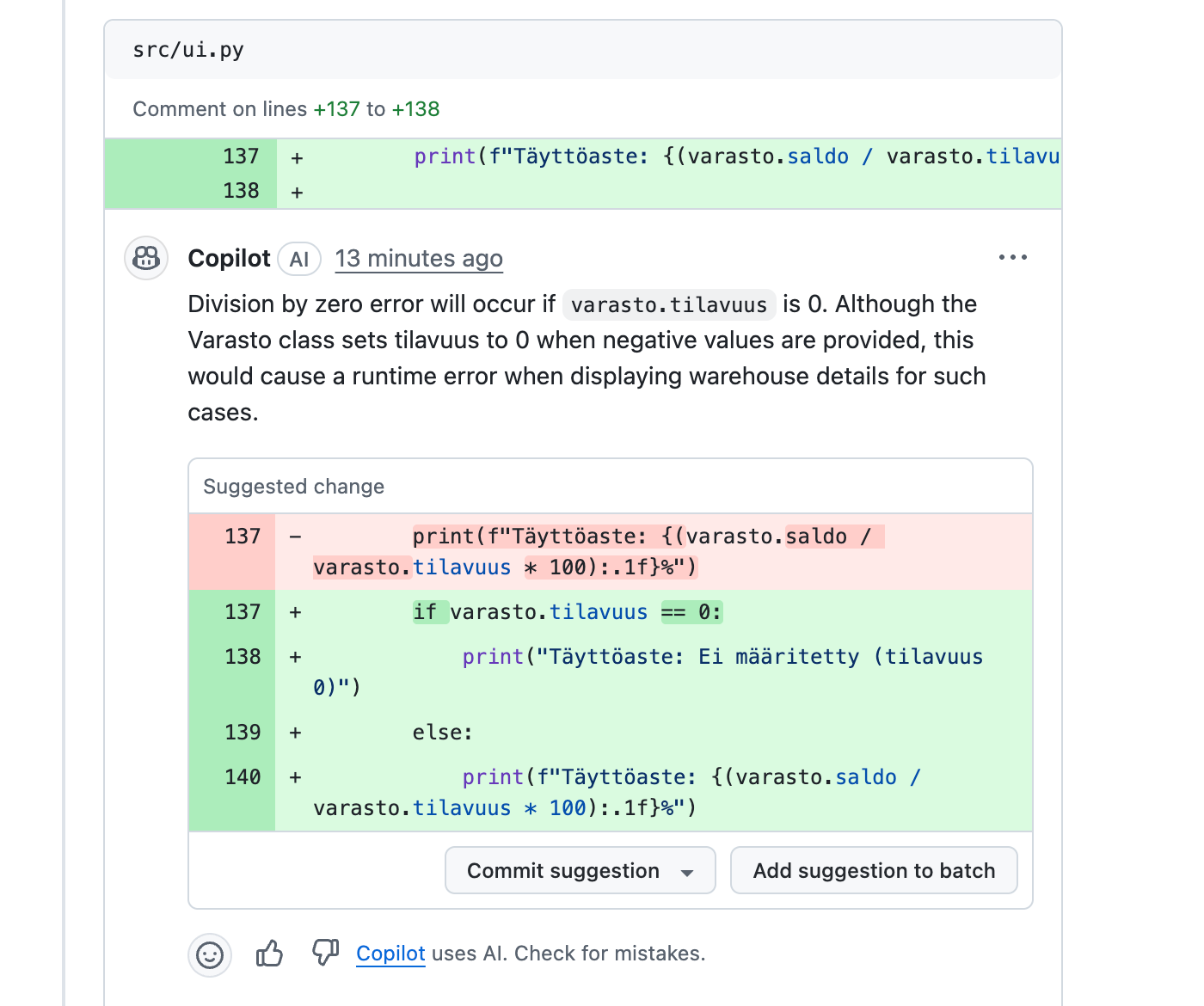
Kommentti sekä korjausehdotus näyttävät tällä kerttaa asialliselta. Korjausehdotuksen voi halutessaan commitoida, jolloin commit lisätään pull requestiin.
Extreme programmingin katselmoinnin menetelmiä
Toisin kuin Scrum, eXtreme Programming eli XP, joka oli erityisen suosittu 2000-luvun alkuvuosina, määrittelee useita ohjelmiston kehittäjän työskentelyyn kantaa ottavia käytänteitä.
Suurin osa XP:n käytänteistä on jo vuosikymmeniä hyvin tunnettuja parhaita käytänteitä (engl. best practices), mutta usein vietynä äärimmäiseen (extreme) muotoon. Osa XP:n käytänteistä tähtää ohjelmiston laadun maksimoimiseen ja muutama palvelee samaa funktiota kuin koodikatselmointi.
Pariohjelmoinnissa (engl. pair programming) kaksi ohjelmoijaa työskentelee yhdessä käyttäen ainoastaan yhtä konetta. Koodia kirjoittava osapuoli toimii ohjaajana (engl. driver) ja toinen navigoijana (engl. navigator), roolia vaihdetaan sopivin väliajoin. Navigoija tekee koodiin jatkuvaa katselmointia.
Pariohjelmointi parantaa ohjelmoijien kuria ja keskittymistä työhön sekä on erinomainen oppimisen väline: parit oppivat toisiltaan, erityisesti noviisit kokeneemmilta. Jos pariohjelmointia sovelletaan systemaattisesti, ei koodiin jää osa-alueita, jotka ainoastaan yksi ohjelmoija tuntee.
Pariohjelmointia on tutkittu suhteellisen paljon. Tutkimuksissa sen on todettu vähentävän bugien määrää jossain määrin, mutta kokonaisuudessa resurssien kulutus kuitenkin nousee hieman. Tutkimukset korostavat pelkkien koodin tasolla näkyvien hyötyjen lisäksi myös pariohjelmoinnin myönteistä vaikutusta tiimidynamiikkaan ja jopa työtyytyväisyyteen.
Vaikka pariohjelmointi tai jopa useamman ihmisen versio siitä, mob-programming on melko suosittua, ei kovin monissa paikoissa kuitenkaan harrasteta systemaattisesti määritelmän mukaista pariohjelmointia ainakaan joka päivä. Hyvin yleistä on, että kehittäjät työskentelevät suurimman osan aikaa yksin, mutta tekevät tarpeen mukaan spontaaneja pari- tai mob-ohjelmointisessioita, erityisesti kohdatessaan teknisiä haasteita.
Koodin laatuun katselmoinnin kaltaisesti vaikuttavat myös XP:n periaatteet: yhteisomistajuus ja ohjelmointistandardit.
Koodin yhteisomistajuus (engl. collective code ownership) tarkoittaa periaatetta, jossa kukaan yksittäinen ohjelmoija ei hallitse yksin mitään kohtaa koodista, eli kaikilla on lupa tehdä muutoksia ja laajennuksia mihin tahansa kohtaan koodia. Pariohjelmointi tukee yhteisomistajuutta.
Yhteisomistajuudessa on omat riskinsä: joku koodia kunnolla tuntematon voi saada huolimattomilla muutoksilla pahaa jälkeä aikaan. XP pyrkii eliminoimaan tästä aiheutuvia riskejä testaukseen liittyvillä käytänteillä, käytännössä automatisoiduilla regressiotesteillä.
Ohjelmointistandardi (engl. coding standards) tarkoittaa, että tiimi määrittelee koodityylin, johon kaikki ohjelmoijat sitoutuvat. Tyylillä tarkoitetaan nimeämiskäytäntöä, koodin muotoilua ja tiettyjä ohjelman rakenteeseen liittyviä seikkoja. Ohjelmointistandardin noudattamista voidaan kontrolloida osittain automaattisesti staattisen analyysin työkaluilla, esimerkiksi Pythonin Pylint, sekä JavaScript-maailman Eslint ja Prettier ovat työkaluja, joiden avulla voidaan seurata, että koodi seuraa määriteltyä ohjelmointistandardia. Eräs esimerkki suosituksi nousseesta ohjelmointistandardista on Airbnb:n tyyliopas.
Testaus
Ohjelmistojen osoittaminen täysin virheettömiksi on käytännössä mahdotonta, sillä ohjelmiston mahdollisten käyttöskenaarioiden ja syötteiden kombinaatio on yksinkertaisesti liian suuri. Testauksen tarkoituksena onkin vakuuttaa asiakaat ja järjestelmän kehitystiimi siitä, että ohjelmisto on riittävän hyvä käytettäväksi.
Testauksella on kaksi hieman toisistaan poikkeavaa tavoitetta. Ensinnäkin tulee osoittaa, että ohjelmisto täyttää sille asetetut vaatimukset. Käytännössä tämä tarkoittaa vaatimusmäärittelyssä kirjattujen asioiden toteutumisen demonstroimista toteutetusta ohjelmistosta. Toinen tavoite on löytää ohjelmistosta virheitä eli testatessa yritetään rikkoa ohjelma tai saattaa se jollain tavalla epäyhtenäiseen tilaan. Näin havaitut viat pyritään korjaamaan ennen kuin todelliset käyttäjät törmäävät samoihin ongelmiin.
Molemmat tavoitteet tähtäävät ensisijaisesti ohjelman ulkoisen laadun (engl. external quality) eli käyttäjän kokeman laadun varmistamiseen. Ulkoisella laadulla tarkoitetaan sitä, onko ohjelmisto sopiva käyttötarkoitukseensa, eli pystyykö käyttäjä tekemään ohjelmistolla haluamansa asiat.
Testauksen tasot
Testaus jakaantuu eri tasoihin sen mukaan, mikä testauksen ensisijaisena kohteena on. Ohjelmiston elinkaarta vesiputousmaisesti kuvaava testauksen V-malli havainnollistaa testauksen eri tasoja.
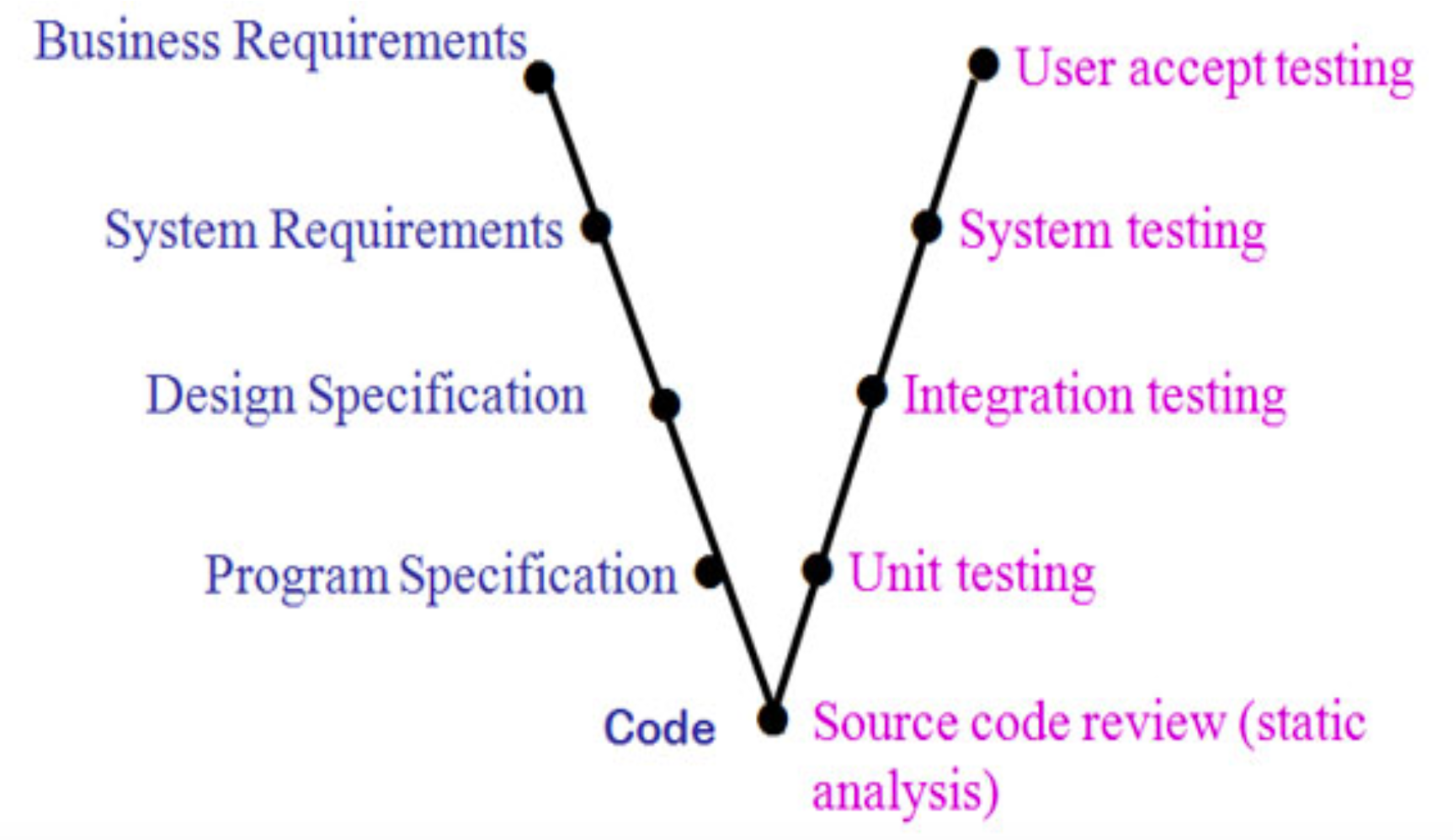
Alimmalla tasolla on yksikkötestaus (engl. unit testing), jossa tarkastellaan yksittäisten luokkien, metodien ja moduulien toimintaa, yleensä erillään muusta kokonaisuudesta. Yksikkötestauksen hoitavat sovelluskehittäjät.
Integraatiotestaus (engl. integration testing) taas sisältää yksittäisistä komponenteista koostettujen kokonaisuuksien toiminnallisuuden testaamisen. Myös integraatiotestauksesta huolehtivat sovelluskehittäjät.
Järjestelmätestauksessa (engl. system testing) varmistetaan, että ohjelmisto kokonaisuudessaan toimii vaatimuksiin kirjatulla tavalla. Ohjelmistoa testataan saman rajapinnan käyttäen, kuin loppukäyttäjät sitä käyttävät. Järjestelmätestauksesta on useimmiten vastuussa ohjelmiston kehittäjäorganisaation laadunhallinnasta vastaavat ihmiset.
Ohjelmiston tilaaja- tai käyttäjäorganisaation tekemää testausta kutsutaan käyttäjän hyväksymistestaukseksi (engl. user acceptance testing), ja sen on tarkoitus varmistaa, että kehitetty ohjelmisto on varmasti odotusten mukainen ja toimii oikeassa käytössä. Hyväksymistestaus tapahtuu monesti normaalissa tuotantokäytössä ohjelmiston tilanneen organisaation tai loppukäyttäjien toimesta, esim. betatestaamalla sovellusta pienen käyttäjäjoukon avulla. Hyväksymistestaus ei siis keskity siihen, toimiiko ohjelmisto juuri niin kuin vaatimusmääritelmässä sanotaan, vaatimusmääritelmähän ei välttämättä kuvaa täsmälleen käyttäjän todellista tarvetta.
Järjestelmätestaus
Järjestelmätestauksen tarkoitus on siis varmistaa, että ohjelmisto toimii vaatimusmäärittelyssä kirjatulla tavalla. Sovellusta testataan useimmiten saman rajapinnan kautta, jonka kautta sitä käytetään, eli testaus voi tapahtua esimerkiksi graafisen käyttöliittymän kautta.
Järjestelmätestaus tapahtuu ilman tietoa järjestelmän sisäisestä rakenteesta, tälläista testauksen tapaa nimitetään black box -testaukseksi.
Järjestelmätesteille on tyypillistä, että ne tarkastelevat sovelluksen toiminnallisuutta sen kaikilla tasoilla käyttöliittymästä sovelluslogiikkaan ja tietokantaan. Tämän takia järjestelmätestejä kutsutaan usein end to end -testeiksi.
Yleensä järjestelmätestaus perustuu sovelluksen potentiaalisiin käyttöskenaarioihin. Jos vaatimukset on ilmaistu user storyina, on storyjen hyväksymiskriteereistä melko helppo muotoilla testejä, joiden avulla voidaan varmistaa, että ohjelmistolla on storyjen kuvaamat vaatimukset sekä tyypilliset virheskenaariot.
Sovelluksen toiminnallisuutta kartoittavan järjestelmätestauksen (jota joskus kutsutaan funktionaaliseksi testaamiseksi) lisäksi on olemassa paljon muitakin järjestelmätestauksen muotoja, mm.
- käytettävyystestaus
- suorituskykytestaus
- tietoturvan testaus
- saavutettavuustestaus
Järjestelmätestaus tapahtuu pääosin kehittäjäorganisaation toimesta. Joissain tapauksissa esim. tietoturvan tai suorituskyvyn testaaminen saatetaan antaa niihin erikoistuneiden tahojen vastuulle.
Testitapausten valinta
Täysin kattava testaaminen on mahdotonta ja testaus on joka tapauksessa työlästä. Onkin tärkeää löytää kohtuullisen kokoinen testitapausten joukko, jonka avulla on kuitenkin mahdollista löytää mahdollisimman suuri määrä virheitä.
Yksittäinen testitapaus (engl. test case) testaa järjestelmän toiminnallisuutta yhdellä syötearvolla tai arvojen yhdistelmällä, mikäli toiminnallisuus vaatii useita syötteitä. Useat syötteet ovat järjestelmän toiminnan kannalta samanlaisia. Esimerkiksi, jos henkilötietoja käsittelevä järjestelmä tallettaa henkilön iän, on todennäköistä, että järjestelmän toiminta ei poikkea ollenkaan sen suhteen, onko ikä 20 tai 30, mutta jos ikä taas on 17, saattaa järjestelmän toiminnallisuus olla erilainen kuin iän ollessa vähintään 18.
Testeissä kannattaakin pyrkiä jakamaan syötteet ekvivalenssiluokkiin, eli ryhmiin joihin kuuluvien syötteiden suhteen ohjelma toimii oleellisesti samalla tavalla. Testitapauksia kannattaa tehdä useimmiten ainoastaan yksi tai kaksi kutakin ekvivalenssiluokkaa tai syötteiden ekvivalenssiluokkien kombinaatiota kohti. Ekvivalenssiluokkien edustajiksi kannattaa erityisesti valita näiden raja-arvoja, koodissa olevat bugit nimittäin liittyvät erittäin usein toisto- ja ehtolauseiden ehtojen äärimmäisiin arvoihin.
Esimerkiksi henkilötietoja käsittelevässä järjestelmässä iän suhteen ekvivalenssiluokkia olisivat ehkä alaikäinen 0-17 vuotta, työikäinen 18-65 vuotta ja eläkeläinen 66- vuotta. Ekvivalenssiluokkien raja-arvojen järkevä määrittely edellyttää tietoa järjestelmän toiminnallisuudesta. Todennäköisesti työikäisten ja eläkeläisten suhteen ei olisi mahdollista tehdä selkeää jakoa iän perusteella. Jos oletetaan, että edelliset ekvivalenssiluokat olisivat järkeviä, sopivat iän raja-arvot testitapauksia varten olisivat 17, 18, 65 ja 66 vuotta, eli näitä kaikkia kohti voitaisiin tehdä oma testitapauksensa.
Tarkastellaan toisena esimerkkinä teksti-tv:n selainversiota.
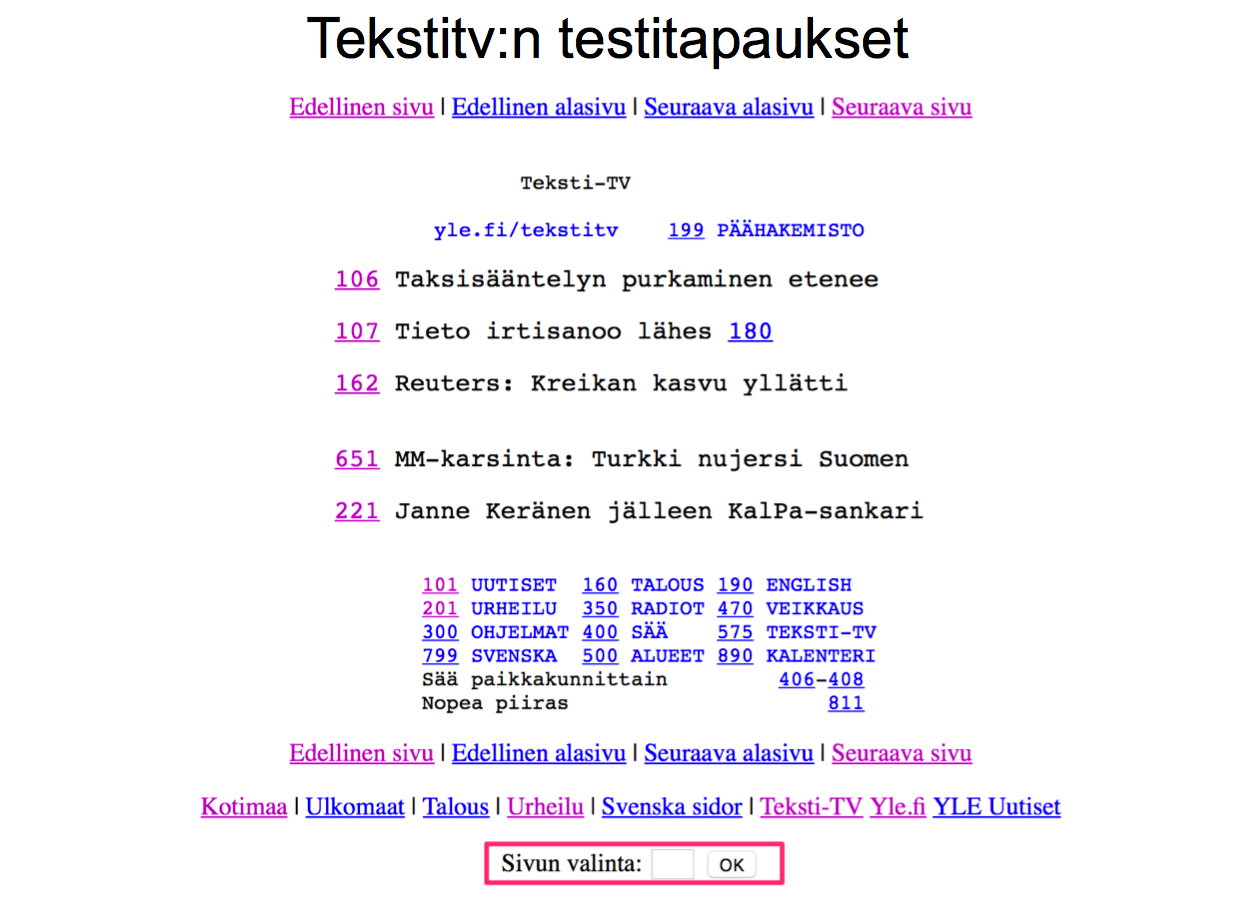
Mitä testitapauksia kannattaisi valita tekstitv:n sivun valintaikkunan toimivuuden testaamisessa?
Tekstitv:n sivu vastaa lukua väliltä 100-899. Osaa välin luvuista vastaavaa sivua ei kuitenkaan ole olemassa.
Syötteen ekvivalenssiluokkia olisivat ainakin seuraavat:
- olemassa olevaa sivua vastaavat luvut
- validit luvut, jotka eivät vastaa mitään sivua
- liian pienet ja liian suuret luvut
- syötteet, jotka sisältävät kiellettyjä merkkejä (esimerkiksi aakkosia)
- tyhjä syöte
Jos testeistä halutaan kattavat, olisi jokaisesta ekvivalenssiluokasta hyvä valita ainakin yksi testattava syötearvo.
Olemassa olevaa sivua vastaavan ekvivalenssiluokan rajatapaukset, eli luvut 100 ja 899 kannattaisi ehkä valita testisyötteiksi, samoin luvut 99 ja 900, jotka ovat oman ekvivalenssiluokkansa rajatapauksia.
Yksikkötestaus
Yksikkötestauksen kohteena ovat yksittäiset metodit ja luokat. Yksikkötestauksen hoitavat ohjelmoijat. Usein oletetaan, että uuteen koodiin tehdään yksikkötestit jo samalla kuin koodi kirjoitetaan. Ohjelmoijien vastuulla olevasta testauksesta, eli yksikkö- ja integraatiotestauksesta käytetään usein nimitystä developer testing.
Yksikkötestejä laadittaessa saatetaan ottaa huomioon testattavan koodin rakenne, esimerkiksi minkälaisia ehtolauseita koodissa on käytetty. Jos testeissä huomioidaan testattavan järjestelmän sisäinen rakenne, puhutaan usein lasilaatikkotestauksesta (engl. white box testing).
Yksikkötestauksella ei testata suoranaisesti sitä, täyttääkö ohjelmisto käyttäjän sille asettamat vaatimukset, pikemminkin tavoitteena on ohjelman sisäisen laadun (engl. internal quality) kontrollointi. Sisäinen laatu viittaa koodin sisäisen rakenteen hyvyyteen: onko koodia helppo jatkokehittää, onko virheiden jäljittäminen ja korjaaminen helppoa, ja pystytäänkö koodin toiminnallisuuden oikeellisuus varmistamaan muutoksia tehtäessä.
Sisäinen laatu kiinnostaa ensisijaisesti ohjelmistokehittäjiä: jos koodi on sisäiseltä laadultaan heikkoa, on sen parissa työskenteleminen ikävää ja hidasta. Jos koodin sisäinen laatu alkaa rapistua, sovelluksen kehitystahti hidastuu, ja ohjelmistoon alkaa todennäköisesti kertymään enenevissä määrin bugeja jotka näkyvät myös loppukäyttäjälle.
Pelkkä sisäisen laadun kontrollimekanismi yksikkötestaus ei siis ole. Kattavilla yksikkötesteillä saadaan parannettua myös ohjelman ulkoista, eli asiakkaan kokemaa laatua. Yksikkötestit voivat eliminoida joitain asiakkaalle näkyviä virheitä, joita järjestelmätestauksen testitapaukset eivät löydä.
Tiedetään, että bugit on taloudellisesti edullista paikallistaa mahdollisimman aikaisessa vaiheessa, eli yksikkötestauksessa löydetty virhe on halvempi ja nopeampi korjata kuin integraatio- tai järjestelmätestauksessa löytyvä, tai vasta todellisessa käytössä ilmenevä virhe.
Koska yksikkötestejä joudutaan suorittamaan moneen kertaan, tulee niiden suorittaminen ja testien tulosten raportointi automatisoida, ja nykyinen hyvä työkalutuki tekeekin automatisoinnin helpoksi. Java-maailmasta tuttu JUnit on edelleen yksi suosituimpia testikirjastoja, uudempia tulokkaita ovat mm. RSpec (Ruby), Mocha ja Jest (JavaScript). Pythonin suosituin yksikkötestauskirjasto on ensimmäisistä laskareista tuttu unittest.
Kurssilla Ohjelmistotekniikka tehdyt testit ovat useimmiten juurikin yksikkötestejä.
Mitä ja miten paljon tulee testata?
Mitä kaikkea ohjelmistosta tulisi testata yksikkötesteillä? Vastaus ei ole helppo. JUnitin alkuperäinen kehittäjä Kent Beck vastaa kysymykseen seuraavasti:
“Do I have to write a test for everything?” “No, just test everything that could reasonably break”
Jos pyritään kattavaan yksikkötestaukseen, tulisi ainakin testata kaikkien metodien (ja loogisten metodikombinaatioiden) toiminta parametrien hyväksyttävillä arvoilla ja virheellisillä parametrien arvoilla.
Parametrien mahdolliset arvot kannattaa jakaa ekvivalenssiluokkiin ja jokaisesta luokasta kannattaa valita ainakin yksi arvo testisyötteeksi. Erityisesti ekvivalenssiluokkien raja-arvot kannattaa valita mukaan testattaviin arvoihin.
Koska yksikkötestejä tehtäessä ohjelmakoodi on nähtävillä, on testien parametrien ekvivalenssiluokat ja raja-arvot useimmiten pääteltävissä koodista.
Tarkastellaan esimerkkinä ensimmäisen viikon laskareista tutun Ohtuvaraston metodia ota_varastosta. Mitä testitapauksia tulisi generoida, jotta testit olisivat kattavat?
class Varasto:
def __init__(self, tilavuus, alku_saldo = 0):
self.tilavuus = max(tilavuus, 10)
self.saldo = min(tilavuus, max(alku_saldo, 0))
def ota_varastosta(self, maara):
if maara < 0:
return 0.0
if maara > self.saldo:
kaikki_mita_voidaan = self.saldo
self.saldo = 0.0
return kaikki_mita_voidaan
self.saldo = self.saldo - maara
return maara
Metodia ota_varastosta testatessa testitapauksessa on huomioitava parametrin maara lisäksi varaston tilanne. Varaston tilanteella on kolme “ekvivalenssiluokkaa”:
- tyhjä (esim. saldo 0, tilavuus 10)
- ei tyhjä eikä täysi (esim. saldo 5, tilavuus 10)
- täysi (saldo 10, tilavuus 10).
Näitä kutakin kohti on metodin parametrilla maara omat ekvivalenssiluokkansa. Jos varasto on “puolitäysi”, eli saldo on 5, muuttujan maara arvoiksi voitaisiin valita -1, 0, 5, 6. Jos varasto on täysi, muuttujan maara arvoiksi sopisivat -1, 0, 10, 11. Jos varasto on tyhjä, muuttujan maara arvoiksi voidaan valita -1, 0, 1.
Nollan ja negatiivisen määrän ottamista tuskin kannattaa erikseen testata kaikkien varastotilanteiden suhteen. Tämä voi olla riski, jos varaston sisäinen toteutus muutettaisiin täysin.
Huomaamme siis, että jo naurettavan pienen luokan yhden metodin kattava testaaminen vaatii suuren määrän testitapauksia. Useimmissa tapauksissa ei kuitenkaan ole realistista olettaa, että testejä tehdään vastaavalla kattavuudella, aika/hyötysuhde on yksinkertaisesti liian huono. Useimmat ohjelmistossa olevat ikävät bugit jäävät joka tapauksessa yksikkötestauksen ulottumattomiin.
Testauskattavuus
Yksikkötestien (ja toki myös muunlaisten testien) hyvyyttä voidaan jossain määrin mitata testauskattavuuden (engl. test coverage) käsitteellä. Testauskattavuutta on muutamaa eri tyyppiä.
Rivikattavuudella (engl. line coverage) tarkoitetaan kuinka montaa prosenttia ohjelman koodiriveistä testitapausten suorittaminen käy läpi. Vaikka rivikattavuus olisi 100% ei tämä tietenkään tarkoita, että kaikki oleellinen toiminnallisuus olisi tutkittu.
Haarautumakattavuudella (engl. branch coverage) tarkoitetaan kuinka montaa prosenttia testattavan metodin/luokan sisältävistä ehtolauseiden haaroista testit ovat käyneet läpi.
Monet työkalut, esim. laskareissa käyttämämme Coverage mittaavat testien suorituksen yhteydessä testauskattavuuden. Muitakin kattavuuden tyyppejä on olemassa, mm. ehtokattavuus ja polkukattavuus, useat työkalut eivät niitä kuitenkaan tue.
Seuraavassa esimerkki Coveragella mitatusta rivi- ja haarautumakattavuudesta:
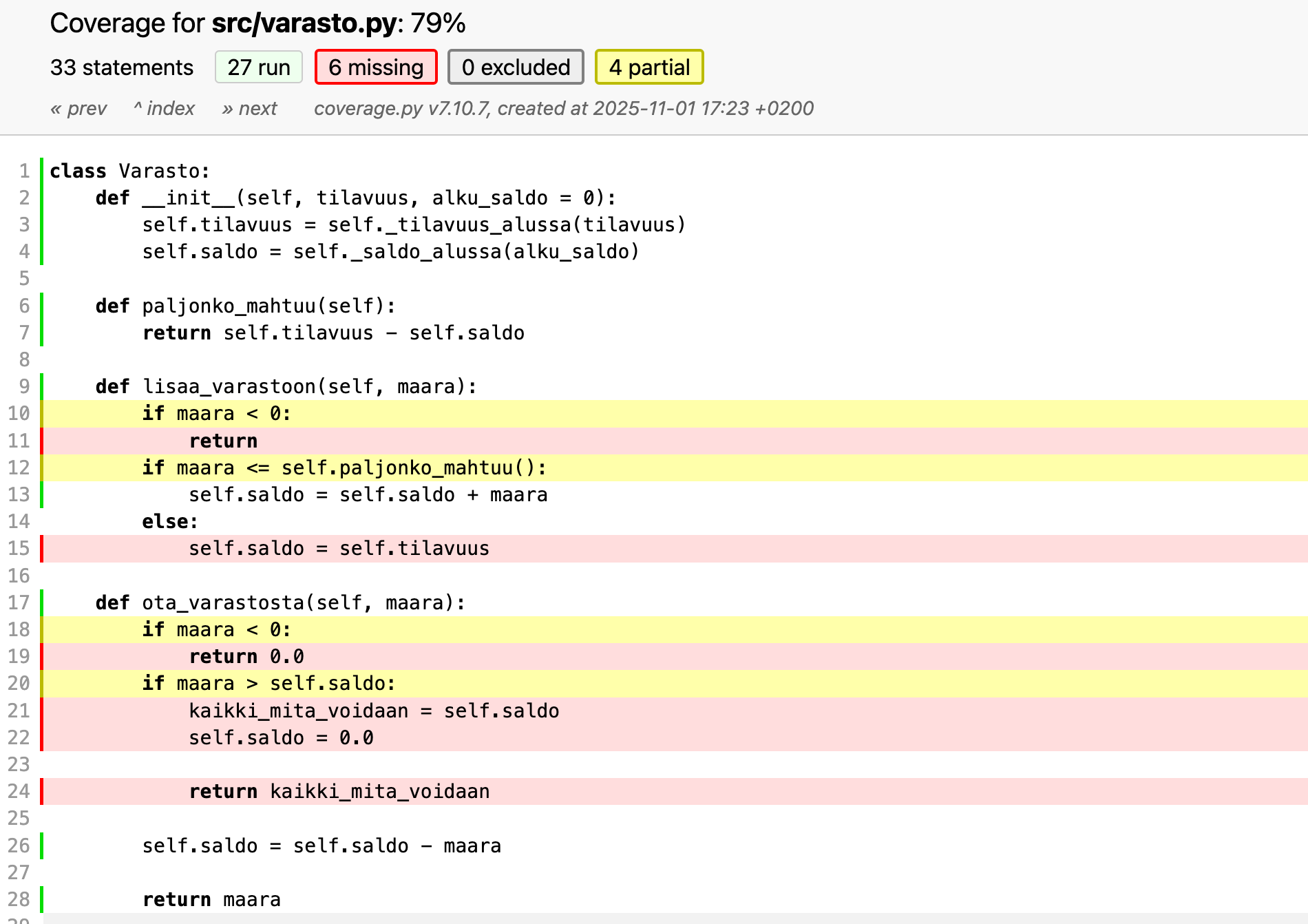
Coverage ilmoittaa haarautumakattavuuden (branches). Puutteellisesti testattu haarautumiskohta esim. if ilmaistaan keltaisella ja ne rivit mitä testit eivät kata ovat punaisia.
Testauskattavuus toimii siis hyvänä apuvälineenä sen arvioimisessa testataanko sovellusta riittävästi.
Mutaatiotestaus
Pelkkä testikattavuus ei vielä kerro oikeastaan mitään testien hyvyydestä. Hyvät testit ovat sellaisia, että jos ohjelmaan tulee bugi, huomaavat testit virheen. Testien hyvyys riippuu oleellisesti testien syötteiden lisäksi siitä, minkälaisia assert-lauseilla suoritettavia tarkistuksia testeissä on.
Mutaatiotestauksen (engl. mutation testing) idea on nimenomaan testata testitapausten hyvyyttä generoimalla koodiin systemaattisesti mutantteja eli pieniä “bugeja”, ja katsoa havaitsevatko testit koodiin tulleet bugit.
Erilaisia mutanttityyppejä, joita mutaatiotestauksessa generoidaan koodiin on paljon mm.
- manipuloidaan ehtolausetta: if ( x<0 ) muutetaan muotoon if (x <= 0) tai if ( True )
- vaihdetaan operaattoria: x += 1 muutetaan muotoon x -= 1
- kovakoodataan paluuarvo: return x muutetaan muotoon return True
- korvataan konstruktorikutsu: olio = Olio() muutetaan muotoon olio = None
Mutaatiotestauksen haasteena on mutaatioiden suuri määrä ja ns. ekvivalentit mutantit, joiden takia mutaatiotestauksen tulos vaatii aina ihmisen tulkintaa.
Ekvivalentti mutantti tarkoittaa sellaista koodiin tehtyä muutosta, joka ei kuitenkaan muuta ohjelman toiminnallisuutta. Tällaisen mutantin lisäämistä koodiin ei voi mikään testi havaita. Mutantin toteaminen ekvivalentiksi algoritmisesti on mahdotonta.
Lisätietoa mutaatiotestauksesta esim. Wikipediassa.
Integraatiotestaus
Järjestelmän yksittäiset, erillään yksikkötestatut luokat tulee integroida toimivaksi kokonaisuudeksi. Integroinnin yhteydessä tai sen jälkeen suoritetaan integraatiotestaus, missä painopiste on ohjelman komponenttien välisten rajapintojen toimivuuden tutkimisessa sekä komponenttien yhdessä tuottaman toiminnallisuuden oikeellisuuden varmistamisessa.
Järjestelmän integrointi voi edetä joko järjestelmän rakenteeseen perustuen tai järjestelmän toteuttamien ominaisuuksien mukaan.
Rakenteeseen perustuvassa integraatiossa keskitytään kerrallaan sovelluksen yksittäisten rakenteellisten komponenttien integrointiin. Esimerkiksi verkkokaupan toteutuksessa integroitaisiin ensin arkkitehtuurilliset komponentit tai kerrokset, eli sovelluslogiikan luokat, käyttöliittymän toteutus ja tietokantarajapinta omina kokonaisuuksinaan. Tämän jälkeen kerrokset integroitaisiin kokonaiseksi sovellukseksi.
Ominaisuuksiin perustuvassa integroinnissa taas liitetään yhteen alikomponentit, jotka toteuttavat järjestelmän loogisen toiminnallisuuden. Verkkokaupassa voitaisiin esimerkiksi integroida kerrallaan kaikki toiminnallisuuteen lisää tuote ostoskoriin liittyvä koodi ja edetä toiminnallisuus kerralla kunnes koko sovellus on valmis.
Vesiputousmallin kulta-aikoina vanhan liiton ohjelmistotuotannossa toimintatapa oli se, että kaikki ohjelman yksittäiset komponentit ohjelmoitiin ja yksikkötestattiin erikseen. Lopuksi komponentit integroitiin (yleensä rakenteeseen perustuen) kerralla yhteen.
Tällainen vesiputousmallin maailmassa yleinen, nimellä big bang -integraatio kulkeva tekniikka on osoittautunut todella riskialttiiksi (siitä on seurauksena usein ns. integraatiohelvetti) ja sitä ei enää kukaan täysijärkinen suosittele käytettäväksi.
Moderni ohjelmistotuotanto suosii jatkuvaa integraatiota (engl. continuous integration), joka on hyvin tiheässä tahdissa tapahtuvaa ominaisuuksiin perustuvaa integrointia. Palaamme aiheeseen tarkemmin pian.
Itse asiassa koko termi integraatiotestaus on käsitteenä melko häilyvä, ja joskus on vaikea tehdä selkeää rajanvetoa yksikkö- ja integraatiotestauksen välillä. Useimmiten ajatellaan, että yksikkötestien kohteena on yksittäinen metodi, luokka tai ohjelmamoduuli. Entä jos testauksen alla oleva luokka/moduuli pitää sisällään rajapinnan takana useita muitakin luokkia, onko kyseessä enää yksikkötesti vai onko kyseessä jo suurempaa kokonaisuutta kartoittava integraatiotesti?
Integraatiotestaukseksi luokiteltavia testejä ovat ainakin seuraavanlaiset, selkeästi isompia osakokonaisuuksia testaavat testit
- sovelluslogiikan ja tietokannan yhteistoiminnallisuuden varmistaminen
- sovelluksen palvelimen eli backendin tarjoaman HTTP-rajapinnan oikean toiminnallisuuden varmistaminen
Yksikkötestauksen tapaan koodin integroinnin ja usein myös integraatiotestauksen katsotaan nykyään olevan sovelluskehittäjien vastuulla, eli integraatiotestaus kuuluu käsitteen developer testing alle.
Regressiotestaus
Iteratiivisessa ja ketterässä ohjelmistotuotannossa jokainen iteraatio tuottaa ohjelmistoon uusia ominaisuuksia. Samalla on varmistettava, etteivät lisäykset riko ohjelman jo toimivia osia.
Testit on siis suoritettava uudelleen aina kun ohjelmistoon tehdään muutoksia. Tätä käytäntöä kutsutaan regressiotestaukseksi. Jotta varmuus ohjelmiston virheettömänä pysymisestä olisi mahdollisimman suuri, on regressiotestien joukon hyvä koostua sekä yksikkö-, integraatio- että järjestelmätesteistä.
Regressiotesteinä käytetään useimmiten kaikkia sovelluskehityksen aikana tehtyjä testejä. On myös tilanteita, joissa tämä ei ole mielekästä esimerkiksi testien suorituksen viemän ajan takia, ja sopiva osajoukko kaikista testeistä voi taata riittävän luottamuksen sovelluksen virheettömänä säilymisestä.
Testaaminen on erittäin työlästä ja regressiotestauksen tarve tekee siitä entistä työläämpää. Tämän takia on erittäin tärkeää pyrkiä automatisoimaan testit mahdollisimman suurissa määrin.
Automatisoitu yksikkötestaus on osalle jo aiemmilta kursseilta tuttu aihe. Käsittelemme muutamia järjestelmätestauksen automatisoinnin menetelmiä seuraavissa luvuissa.
Ketterien menetelmien testauskäytänteitä
Testauksen rooli ketterissä menetelmissä poikkeaa huomattavasti vesiputousmallisesta ohjelmistotuotannosta. Iteraation/sprintin aikana toteutettavat ominaisuudet integroidaan muuhun koodiin ja testataan yksikkö-, integraatio- sekä järjestelmätasolla. Sykli ominaisuuden määrittelystä siihen, että se on valmis ja testattu on erittäin lyhyt, viikosta kuukauteen.
Testausta tehdäänkin sprintin “ensimmäisestä päivästä” lähtien ja testaus on integroitu suunnitteluun ja toteutukseen, eikä ole ketterän näkemyksen mukaan enää oma erillinen vaiheensa.
Ketterän kehityksen luonne vaatiikin, että testejä voidaan suorittaa usein ja mahdollisimman vähällä vaivalla, siispä automatisoitu regressiotestaus on avainasemassa.
Kuten Scrumin käsittelyn yhteydessä mainittiin, ketterien sovelluskehitystiimien tulisi olla cross functional, eli sisältää kaikki tietotaito, minkä järjestelmän kehittäminen ja tuotantokäyttöön valmiiksi saattaminen edellyttää. Tästä syystä testaajat sijoitetaan ihannetilanteessa kehittäjätiimeihin erillisen laatua valvovan QA-tiimin sijaan. Myös ohjelmoijat osallistuvat testien kirjoittamiseen.
Testaajan rooli muuttuu virheiden etsijästä virheiden estäjään: testaaja auttaa tiimiä kirjoittamaan automatisoituja testejä, jotka pyrkivät estämään bugien pääsyn koodiin. Eräänä kantavana teemana ketterässä laadunhallinnassa onkin “sisäänrakentaa laatu tuotteisiin”, eli Lean-maailmasta tuttu periaate build quality in. Tämä tarkoittaa sitä, että laadunhallintaan ei suhtauduta erillisen organisaation (esim. QA-tiimin) vastuulla olevana asiana, vaan sovelluskehityksessä on jo lähtökohtana se, että bugeja ei pääse syntymään ja jos pääsee, ne tulee havaita mieluiten jo ohjelmointivaiheessa.
Käymme tässä luvussa läpi joukon ketterien menetelmien suosimia testauskäytäntöjä.
Test driven development eli TDD on kehitysmenetelmä, jossa testit tehdään jo ennen koodin kirjoittamista. Nimestään huolimatta kyseessä tosin on enemmän suunnittelu- ja toteutustason tekniikka jonka sivutuotteena syntyy kattava joukko automaattisesti suoritettavia testejä.
User storyjen tasolla tapahtuva automatisoitu testaus, joka kulkee nimillä acceptance test driven development ja behavior driven development.
Continuous Integration eli jatkuva integraatio ja continuous delivery eli jatkuva toimitusvalmius ovat perinteisen integraatio- ja integraatiotestausvaiheen korvaava työskentelytapa, jossa pyrkimyksenä on integroida ja jopa viedä tuotantoympäristöön jokainen sovellukseen tehty muutos.
Kaikista edellisistä käytänteistä seurauksena on suuri joukko eritasoisia (eli yksikkö-, integraatio-, järjestelmä-) automatisoituja testejä, joiden avulla tehty regressiotestaus mahdollistaa sen, että ohjelmiston jatkokehityksen aikana voidaan olla turvallisin mielin siitä, että jo toimivia asioita ei pääse hajoamaan.
Tehdään testaus miten kattavasti tahansa, on kuitenkin hyvin tyypillistä, että tiettyjä ongelmia ilmenee vasta todellisessa käytössä. Nousevana trendinä on suorittaa uusien ominaisuuksien laadunhallintaa myös siinä vaiheessa kun osa oikeista käyttäjistä on jo ottanut ne käyttöönsä. Tuotantokäytössä tapahtuva testaus on suurta kurinalaisuutta vaativa menetelmä, joka vaatii pitkälle kehittynyttä automatisointia ja ohjelmiston sofistikoitunutta monitorointia.
Voimakkaasta automatisointitrendistä huolimatta myös manuaalisesti tehtävällä testauksella on edelleen paikkansa. Tutkiva testaus (engl. exploratory testing) on pääosin manuaalinen järjestelmätestauksen tekniikka, jossa testaaminen tapahtuu ilman tarkkaa etukäteen tehtävää testaussuunnitelmaa. Testaaja luo lennossa uusia testejä edellisten testien antaman palautteen perusteella. Tutkivaa testausta käytetään usein kokonaan uusien ohjelmiston ominaisuuksien testaamiseen.
Test driven development
Test driven development eli TDD (suomeksi testivetoinen kehitys) on yksi eXtreme Programmingin käytänteistä, jossa testit on tarkoitus kirjoittaa ennen varsinaisen koodin kirjoittamista.
Alan auktoriteettien, kuten Kent Beckin ja Uncle Bob Martinin, määritelmän mukainen TDD etenee seuraavasti
- Kirjoitetaan testiä sen verran että testi ei mene läpi. Testejä ei siis luoda heti kaikkia tarvittavia, vaan edetään yksi testi kerrallaan.
- Kirjoitetaan koodia sen verran, että testi saadaan menemään läpi. Ei myöskään yritetä heti kirjoittaa lopullista koodia.
- Jos koodin rakenteen havaitaan menneen huonoksi (koodissa on esimerkiksi paljon toisteisuutta tai liian pitkiä funktioita) refaktoroidaan koodin rakenne paremmaksi, ja huolehditaan jatkuvasti siitä, että testit menevät edelleen läpi. Refaktoroinnilla tarkoitetaan koodin sisäisen rakenteen muuttamista siten, että sen rajapinta ja toiminnallisuus säilyy muuttumattomana.
- Jatketaan askeleesta 1.
TDD:n etenemisestä käytetään usein nimitystä red-green-refactor, eli tehdään testi joka on punaisella, kirjoitetaan koodia siten että testit menevät taas vihreäksi ja jos tarvetta, niin refaktoroidaan. Seuraava kuva havainnollistaa syklin etenemistä:
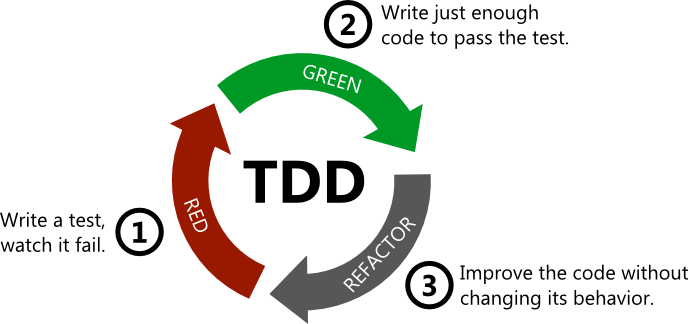
TDD:ssä toteutettavaa komponenttia ei yleensä ole tapana suunnitella tyhjentävästi etukäteen. Testit kirjoitetaan ensisijaisesti ajatellen komponentin käyttöä, eli huomio on komponentin rajapinnassa ja rajapinnan helppokäyttöisyydessä, ei niinkään komponentin sisäisessä toteutuksessa. Komponentin sisäinen rakenne muotoutuu refaktorointien kautta.
TDD:ssä perinteisen suunnittelu-toteutus-testaus-syklin voi ajatella kääntyneen täysin päinvastaiseen järjestykseen, komponentin tarkka suunnittelu tapahtuu vasta refaktorointien yhteydessä.
TDD:n hyviä puolia
TDD:tä sovellettaessa korostetaan yleensä lopputuloksen yksinkertaisuutta. Tarkoituksena on toteuttaa toiminnallisuutta vain sen verran, mitä testien läpimeno edellyttää. Ei siis toteuteta “varalta” ekstratoiminnallisuutta, sillä sitä ei todennäköisesti tarvita. Tästä yksinkertaisiin ratkaisuihin pyrkivästä käytännöstä käytetään usein nimitystä “You ain’t gonna need it”, YAGNI. Sama periaate on kirjattuna ketterään manifestiin muodossa Simplicity – the art of maximizing the amount of work not done – is essential.
Koodista on vaikea tehdä helposti testattavaa, jos se ei koostu modulaarisista ja löyhästi kytketyistä komponenteista, joilla on selkeät rajapinnat. Määritelmän mukaisella TDD:llä ohjelmoitaessa taas koodista tulee useimmiten jo lähtökohtaisesti modulaarista ja vähäistä turhilta riippuvuuksiltaan. Tällaisen koodin uskotaan olevan laadukasta ylläpidettävyyden ja laajennettavuuden kannalta. Eli eräs argumentti TDD:n puolesta on juuri ollut sen tuottama laajennettavuuden ja jatkokehitettävyyden kannalta edullinen koodin laatu.
Muina TDD:n hyvinä puolina mainitaan, että se rohkaisee ottamaan pieniä askelia kerrallaan ja näin toimimaan fokusoidusti, ja että hyvin kirjoitetut testit toimivat toteutetun komponentin rajapinnan dokumentaationa.
TDD:tä on tutkittu akateemisesti kohtuullisen paljon. Kovin suurta evidenssiä sen hyödyistä ei ole havaittu, tosin tutkimusasetelmat eivät ole olleet kovin vakuuttavia ja realistisia käyttötilanteita vastaavia. Niissä ei ole juurikaan otettu kantaa mahdollisiin pitkän aikavälin hyötyihin, joita ylläpidettävyydeltään laadukas koodi mahdollisesti tuottaa.
TDD:llä on myös ikävät puolensa
Käytettäessä TDD:tä testikoodia syntyy paljon, usein suunnilleen saman verran kuin varsinaista koodia. Jos ja kun sovellus muuttuu, tulee testejä myös ylläpitää, sillä monet suuremmat rakenteelliset muutokset rikkovat usein osan testeistä.
TDD:n soveltaminen on haastavaa esimerkiksi käyttöliittymä-, tietokantayhteyksistä tai verkon yli kommunikoinnista huolehtivaa koodia tehtäessä, mutta se ei kuitenkaan ole mahdotonta. Jo olemassa olevan koodin laajentaminen TDD:llä voi olla erittäin haastavaa, erityisesti jos laajennettava koodi on rakenteeltaan vanhan liiton spagettikoodia.
Riippuvuuksien hallinta testeissä
Testatessa on ratkaistava kysymys, siitä miten suhtaudutaan testattavien luokkien riippuvuuksiin, eli komponentteihin, joita testattava koodi käyttää.
Laskareista tuttu riippuvuuksien injektio -suunnittelumalli parantaa koodin testattavuutta, sillä se mahdollistaa riippuvuuksien asettamisen koodille testistä käsin.
Yksi mahdollisuus on tehdä testejä varten riippuvuudet korvaavia tynkäkomponentteja, eli stubeja, näin tehtiin mm. viikon 1 tehtävässä 16. Stubeihin voidaan esim. kovakoodata metodikutsujen tulokset valmiiksi. Testit voivat myös kysellä stubilta millä arvoilla testattava metodi sitä kutsui ja näin varmistaa, että testattava koodi on kommunikoinut riippuvuuksiensa kanssa oletetulla tavalla.
Tynkäkomponentteja kutsutaan niiden ominaisuuksista riippuen joko stubeiksi tai mock-olioiksi, Martin Fowlerin artikkeli selventää asiaa ja terminologiaa. Yleensä stubeksi kutsutaan sellaisia tynkäkomponentteja, jotka ainoastaan palauttavat kovakoodattuja metodikutsujen paluuarvoja. Mock-olioissa taas on enemmän älyä ja ne osaavat mm. tarkkailla onko niiden määrittelemiä metodeja kutsuttu oikeilla parametreilla ja halutun monta kertaa.
On olemassa useita kirjastoja mock-olioiden luomisen helpottamiseksi, tutustumme laskareissa unittest-mock-kirjastoon.
Tarkastellaan hieman unittest-mockin toimintalogiikkaa viikon 4 laskareiden verkkokauppatehtävää esimerkkinä käyttäen. Luokan Kauppa oliolla on riippuvuutenaan Pankki- ja Viitegeneraattori-oliot.
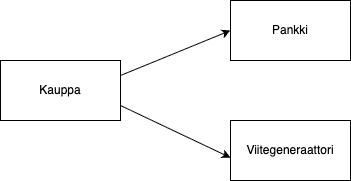
Ostotapahtuman yhteydessä verkkokaupan tulisi veloittaa asiakkaan tililtä ostosten hinta kutsumalla pankin metodia veloita_tilia. Ostostapahtuman koodi näyttää seuraavalta:
my_net_bank = Pankki()
viitteet = Viitegeneraattori()
kauppa = Kauppa(my_net_bank, viitteet)
# ostetaan kaupasta tuotteet joiden id on 5 ja 7
kauppa.aloita_ostokset()
kauppa.lisaa_ostos(5)
kauppa.lisaa_ostos(7)
# maksetaan ostokset
kauppa.maksa("FI1111-2222")
Tästä koodista pitäisi siis testata, että metodikutsu kauppa.maksa("FI1111-2222") tekee ostosten summaa vastaavan tilisiirron pankkitililtä “FI1111-2222” kaupan tilille.
Miten varmistamme, että tilisiirron suorittavaa luokan Pankki olion metodia on kutsuttu oikeilla parametreilla?
unittest-mock-kirjastoa käyttäen tämä onnistuu seuraavasti. Luodaan testissä kaupan riippuvuuksista mock-oliot:
def test_kutsutaan_pankkia_oikealla_tilinumerolla_ja_summalla(self):
# luodaan mock-oliot
pankki_mock = Mock()
viitegeneraattori_mock = Mock(wraps=Viitegeneraattori())
# injektoidaan mockit kaupalle
kauppa = Kauppa(pankki_mock, viitegeneraattori_mock)
kauppa.aloita_ostokset()
kauppa.lisaa_ostos(5)
kauppa.lisaa_ostos(5)
kauppa.maksa("FI1111-2222")
# katsotaan, että ensimmäisen ja toisen parametrin arvo on oikea
pankki_mock.veloita_tilia.assert_called_with("FI1111-2222", 55, ANY)
# oletetaan että tuotteiden 5 ja 7 yhteenlaskettu hinta on 55 euroa
Pankkia edustavalle mock-oliolle on asetettu metodikutsulla assert_called_with vaatimus, joka varmistaa että pankin metodia veloita_tilia on kutsuttu testin aikana sopivilla parametreilla. Jos tämä vaatimus ei täyty, testi ei mene läpi.
Pääset harjoittelemaan mock-kirjastojen käyttöä viikon 4 laskareissa.
User storyjen testaaminen
User storyn määritelmän yhteydessä mainittiin, että user storyn käsite pitää sisällään hyväksymiskriteerit, Mike Cohnin sanoin:
tests that convey and document details and that will be used to determine that the story is complete
Esimerkiksi user storyn asiakas voi lisätä tuotteen ostoskoriin hyväksymiskriteerejä voisivat olla
- ollessaan tuotelistauksessa ja valitessaan tuotteen, jota on varastossa, menee tuote ostoskoriin ja ostoskorin hinta sekä korissa olevien tuotteiden määrä päivittyy oikein
- ollessaan tuotelistauksessa ja valitessaan tuotteen, jota ei ole varastossa, pysyy ostoskorin tilanne muuttumattomana
Optimaalisessa tilanteessa user storyjen hyväksymiskriteereistä saadaan muodostettua suurin osa ohjelmiston järjestelmätason, eli käyttäjän näkökulmasta sovelluksen toiminnallisuuden varmistavista toiminnallisista testeistä.
Storyn hyväksymiskriteerit on tarkoituksenmukaista kirjoittaa heti storyn toteuttavan sprintin alussa, mielellään yhteistyössä kehitystiimin ja product ownerin tai jonkun muun asiakkaan edustajan kesken. Usein käytäntönä on ilmaista hyväksymiskriteerit user storyjen tapaan asiakkaan kielellä, käyttämättä teknistä jargonia. Hyväksymiskriteerien kirjoitusprosessi lisääkin parhaassa tapauksessa asiakkaan ja tiimin välistä kommunikaatiota.
Järjestelmätestauksen automatisointi, ATDD ja BDD
Ideaalitilanteessa storyjen hyväksymiskriteereistä tehdään automaattisesti suoritettavia.
Automaattiseen hyväksymistestaukseen on olemassa monia työkaluja. Eräs suosituimmista on suomalainen Python-pohjainen Robot framework.
Automatisoidusta hyväksymistestauksesta käytetään joskus nimitystä Acceptance Test Driven Development (ATDD) tai Behavior Driven Development (BDD), erityisesti jos testit toteutetaan jo iteraation alkupuolella, ennen kun storyn toteuttava koodi on valmiina.
ATDD:ssä ja BDD:ssä on kyse lähes samasta asiasta pienin painotuseroin. BDD kiinnittää tarkemmin huomiota käytettävään terminologiaan, BDD ei esimerkiksi puhu ollenkaan testeistä vaan sen sijaan kuvailee hyväksymiskriteerit esimerkkikäyttäytymisten (example behavior) avulla.
Käsite ATDD pitää sisällään aina ainoastaan hyväksymistason testauksen. BDD:llä voidaan tehdä myös muita, kuin hyväksymistason testejä. Rubylle alun perin kehitetty RSpec sanoo olevansa BDD-kirjasto, RSpec sopii hyväksymistestien lisäksi hyvin myös yksikkötestaamiseen. Muille kielille on tehty paljon RSpecin tapaan toimivia BDD-henkisiä kirjastoja, kuten JavaScript-maailman Mocha ja Jest.
Robot Framework
Kuten useimmissa hyväksymistason testauksen työkaluissa, myös Robot Frameworkia käytettäessä testit kirjoitetaan asiakkaan kielellä.
Tarkastellaan esimerkkinä käyttäjätunnuksen luomisen ja sisäänkirjautumisen tarjoamaa palvelua.
Palvelun vaatimuksen määrittelevät user storyt
- a new user account can be created if a proper unused username and a proper password are given
- user can log in with a valid username/password-combination
User storyn user can log in with a valid username/password-combination hyväksymäkriteerit ilmaistaisiin Robotissa seuraavasti:
Login With Correct Credentials
Setup Application
Set Username kalle
Set Password kalle123
Submit Credentials
Login Should Succeed
Login With Incorrect Password
Setup Application
Set Username kalle
Set Password kalle456
Submit Credentials
Login Should Fail With Message Invalid username or password
Login With Nonexistent Username
Setup Application
Set Username palle
Set Password kalle456
Submit Credentials
Login Should Fail With Message Invalid username or password
Testitapausten askeleet koostuvat avainsanoista (engl. keyword) sekä niille annettavista parametreistä.
Termi avainsana on sikäli hieman harhaanjohtava, että Robot Frameworkissa avainsanan nimet ovat usein moniosaisia, eli esim. Submit Credentials on yksittäinen avainsana (vaikka se koostuukin useasta englannin kielen sanasta).
Esimerkissä avainsanoja ovat muun muassa Setup Application, Set Username, Submit Credentials, ja Login Should Succeed. Avainsanojen merkitys tulee määritellä, joko yksinkertaisempien avainsanojen avulla tai koodina.
Avainsanojen määrittelyt näyttävät seuraavilta
Setup Application
Reset Application
Create User kalle kalle123
Go To ${LOGIN URL}
Set Username
[Arguments] ${username}
Input Text username ${username}
Submit Credentials
Click Button Login
Login Should Fail With Message
[Arguments] ${message}
Title Should Be Login
Page Should Contain ${message}
Melkein kaikki määrittelyssä esiintyvistä avainsanoista, kuten Input Text, Click Button ja Page Should Contain, ovat Robot Frameworkin käyttämän Web-sovellusten testaamiseen tarkoitetun Selenium-kirjaston valmiiksi määriteltyjä avainsanoja. Ne toimivat sellaisenaan ilman lisämäärittelyn tarvetta.
Avainsanojen Reset Application ja Create User toteuttamiseen tarvitaan hieman koodia. Määrittelyt on kirjoitettu luokkaan AppLibrary:
class AppLibrary:
def __init__(self):
self._base_url = "http://localhost:5001"
# resetoidaan sovelluksen tietokanta tekemällä HTTP-pyynto
def reset_application(self):
requests.post(f"{self._base_url}/tests/reset")
# luodaan tietokantaan käyttäjä HTTP-pyynnön avulla
def create_user(self, username, password):
data = {
"username": username,
"password": password,
"password_confirmation": password
}
requests.post(f"{self._base_url}/register", data=data)
Robot Frameworkiin tutustutaan tarkemmin viikon 3 laskareissa ja miniprojektissa.
Ohjelmiston integraatio
Vesiputousmallissa, eli lineaarisesti etenevässä ohjelmistokehitysprosessissa, toteutusvaihe päättyy integraatiovaiheeseen. Tässä vaiheessa erikseen testatut komponentit yhdistetään toimivaksi kokonaisuudeksi. Samalla suoritetaan integraatiotestaus, jonka tarkoituksena on varmistaa, että komponentit toimivat saumattomasti yhdessä.
Perinteisesti juuri integraatiovaihe on tuonut esiin suuren joukon ongelmia. Tarkasta etukäteissuunnittelusta huolimatta erillisten tiimien toteuttamat komponentit ovat kuitenkin saattaneet olla rajapinnoiltaan tai toiminnallisuuksiltaan epäyhteensopivia.
Suurten projektien integraatiovaihe on kestänyt ennakoimattoman kauan, ja integraation aikana havaitut ongelmat ovat saattaneet aiheuttaa suuriakin suunnitteluun tai jopa vaatimusmäärittelyyn tarvittavia muutoksia.
Integraatio on ollut perinteisesti niin ikävä ja hankala vaihe, että sitä kuvaamaan on lanseerattu termi integraatiohelvetti.
Daily build ja smoke test
90-luvulla alettiin huomaamaan, että riskien minimoimiseksi integraatio kannattaa tehdä useammin kuin vain projektin lopussa. Parhaaksi käytänteeksi alkoi muodostua päivittäin tehtävä koko projektin koodin kääntäminen eli daily build ja samassa yhteydessä suoritettava smoke test. Nämä käytänteet alkoivat nousta suurempaan tietoisuuteen 90-luvun puolivälissä erityisesti Microsoftin Excel- ja Windows 95 -tiimien menestysten ansiosta.
Smoke testillä tarkoitetaan kohtuullisen yksinkertaista järjestelmätason testiä, joka kuitenkin testaa järjestelmän kaikkia arkkitehtuurillisia tasoja (käyttöliittymää, sovelluslogiikkaa, tietokantaa), ja havaitsee jos jotain on pahasti pielessä. Smoke test ei siis kata kovin paljoa sovelluksen toiminnallisuudesta, mutta kuitenkin riittävästi havaitakseen jos sovellus hajoaa perustavanlaatuisella tavalla, esimerkiksi jos sovelluslogiikan ja tietokannan välille syntyy epäyhteensopivuus, joka estää kokonaan tietokantayhteyksien muodostamisen.
Daily buildia ja smoke testiä käytettäessä järjestelmän integraatio tehdään ainakin jollain tarkkuustasolla joka päivä. Komponenttien yhteensopivuusongelmat huomataan nopeasti ja niiden korjaaminen helpottuu. Tiimin moraali myös paranee, kun ohjelmistosta on olemassa päivittäin kasvava ainakin jossain määrin toimiva versio.
Jatkuva integraatio
Kerran päivässä tapahtuva integraatiovaihe todettiin hyväksi käytännöksi. Extreme programming -yhteisö kehitti 90-luvun loppupuolella ideaa vielä pidemmälle ja päätyi edelleen tihentämään integraatiosykliä. Näin syntyi jatkuva integraatio eli continuous integration (CI).
Jatkuvaa integraatiota noudatettaessa ohjelmakoodi, ohjelman käyttämien kirjastojen konfiguraatiot, automatisoidut testit sekä ohjelmiston kääntämisestä ja testaamisesta huolehtivat määrittelyt (kuten pyproject.toml-tiedosto) pidetään keskitetyssä versionhallintarepositoriossa.
Yksittäinen palvelin, joka vastaa mahdollisimman läheisesti tuotantopalvelinta konfiguraatioltaan, varataan CI-palvelimeksi. Kun keskitetyssä repositoriossa olevaan koodiin tulee muutoksia, CI-palvelin hakee ohjelmiston koodin, kääntää sen sekä suorittaa sille testit. Jos koodi ei käänny tai testit eivät mene läpi, CI-palvelin kertoo ongelmista kehittäjätiimille, ja ongelmiin on tarkoitus puuttua välittömästi.
Sovelluskehittäjän työskentely jatkuvaa integraatiota käytettäessä etenee seuraavasti.
Aloittaessaan uuden ominaisuuden toteuttamisen, kehittäjä hakee versionhallinnasta koodin ajantasaisen version. Kehittäjä toteuttaa työn alla olevan ominaisuuden, tekee sille automatisoidut testit ja integroi sen muuhun koodiin. Kun kaikki on valmiina, ja testit menevät läpi paikallisesti, pushaa kehittäjä koodin versionhallintaan.
CI-palvelin huomaa tehdyt muutokset, hakee koodit ja suorittaa testit. Näin minimoidaan riski, että lisätty koodi toimii vain kehittäjän omalla koneella esimerkiksi konfiguraatioerojen vuoksi.
Jatkuvan integraation tarkoituksena on siis se, että jokainen kehittäjä integroi työnsä muuhun koodiin mahdollisimman usein, vähintään kerran päivässä. CI siis rohkaisee jakamaan työn pieniin osiin, sellaisiin jotka saadaan testeineen “valmiiksi” yhden työpäivän aikana. Jatkuvan integraation soveltaminen vaatiikin suurta kurinalaisuutta.
Täydellisenä kontrastina vesiputousmaailman integraatiohelvettiin, jatkuvan integraation pyrkimyksenä on tehdä ohjelmiston integraatiosta mahdollisimman vaivaton operaatio, joka takaa sen että ohjelmistosta on koko ajan saatavilla ajantasainen, kokonaisuudessaan integroitu ja testattu versio.
Jotta CI-prosessi toimisi riittävän jouhevasti, tulee testien suorittamisen tapahtua suhteellisen nopeasti. Maagisena rajana pidetään usein kymmentä minuuttia. Erityisesti käyttöliittymän läpi suoritettavat end to end -testit voivat kuitenkin olla yllättävän aikaa vieviä. Jos testien suoritusaika alkaa kasvaa liikaa, voidaan testit konfiguroida suoritettavaksi kahdessa vaiheessa. Testien ensimmäisen vaiheen, usein nimeltään commit buildin läpimeno antaa kehittäjälle riittävän varmuuden pushata uusi koodi versionhallintaan. CI-palvelimella suoritetaan sitten myös hitaammat testit sisältävä secondary build.
Monimutkaisemmissa tilanteissa testaus voidaan jakaa vieläkin useampaan vaiheeseen. Sovellukselle saatetaan tehdä esim. suuren kuormituksen sietoa mittaavia testejä, joiden suorituksessa kestää useita tunteja. Tällaisia testejä ei ole missään nimessä tarkoituksenmukaista suorittaa jokaisen versionhallintaan tapahtuvan koodin muutoksen (eli commitin) yhteydessä, vaan esimerkiksi kerran vuorokaudessa.
Ensimmäisen viikon laskareissa käytetty GitHub Actions on tällä hetkellä suosituin SaaS-palveluna eli pilvipohjainen CI-ratkaisu. Hieman vanhempia, mutta edelleen käyttökelpoisia vaihtoehtoja ovat CircleCI ja Travis. Eräs SaaS-palveluina toimivien CI-ratkaisujen suurista eduista on se, että tarvetta oman CI-palvelimen asentamiselle ja ylläpitämiselle ei ole.
GitHub Actionsia, CircleCI:tä ja Travisia vanhempi Jenkins on todennäköisesti yhä maailman käytetyin CI-palvelinohjelmisto. Tällä hetkellä ei kuitenkaan ole yhtään ilmaista internetissä palveluna toimivaa Jenkins-palvelua. Jenkinsin käyttö siis edellyttää sen asentamista omalle palvelimelle.
Jatkuvan integraation määritelmä
Palataan vielä siihen mitä jatkuva integraatio menetelmän pioneerien mukaan oikeastaan tarkoittaa. Jatkuvan integraation tekemiseen ei riitä että joku on konfiguroinut tiimille CI-palvelimen. Jotta tiimin voidaan sanoa tekevän jatkuvaa integraatiota, tulee sovelluskehittäjien todellakin synkronoida tekemänsä koodi mahdollisimman usein (vähintään päivittäin) yhteisen keskitetyn repositorion koodin kanssa. Tämä taas tarkoittaa sitä, että esimerkiksi jokaisen aamun alussa kaikilla sovelluskehittäjillä tulisi olla päivän työnsä lähtökohtana sama koodi. Kuten jokainen tiimissä sovelluskehitystä tehnyt tietää, koodin päivittäinen synkronointi ei aina ole helppoa, vaan vaatii systemaattista ja kurinalaista työskentelyä
Nykyään monin paikoin käytössä oleva tapa käyttää useiden päivien tai jopa viikkojen ikäisiä feature branchejä, eli jokaiselle uudelle toiminnallisuudelle tarkoitettuja omia versionhallinnan haaroja tarkoittaa oikeastaan jo lähtökohtaisesti sitä, että tiimi ei harjoita jatkuvaa integraatiota. Palaamme asiaan myöhemmin tässä osassa.
Jatkuva toimittaminen ja toimitusvalmius
Viime aikoina yleistyneen trendin myötä jatkuvaa integraatiota on alettu kehittää entistä pidemmälle. Integraatioprosessiin lisätään yhä useammin myös automaattinen “deployaus”, jossa käännetty ja testattu koodi siirretään automatisoidusti suoritettavaksi niin sanotulle staging- eli testipalvelimelle.
Staging-palvelin on ympäristö, joka on konfiguraatioiden sekä sovelluksessa käsiteltävän datan (käytännössä siis tietokannan sisällön) osalta mahdollisimman lähellä varsinaista tuotantoympäristöä. Kun ohjelmiston uusi versio on viety staging-palvelimelle, suoritetaan sille hyväksymistestaus. Nämä testit ovat lähinnä järjestelmätason testejä, jotka varmistavat, että sovellus toimii käyttäjän haluamalla tavalla mahdollisimman tuotannon kaltaisessa ympäristössä.
Hyväksymistestauksen jälkeen uusi versio voidaan siirtää tuotantopalvelimelle, eli loppukäyttäjien käyttöön. Parhaassa tapauksessa myös staging-ympäristössä tehtävät hyväksymistestit ovat automatisoituja. Tällöin ohjelmisto kulkee koko deployment pipelinen läpi automaattisesti: ensin sovelluskehittäjän koneelta CI-palvelimelle, sieltä staging-ympäristöön ja lopulta tuotantoon. Termillä deployment pipeline tarkoitetaan niitä ohjelman käännöksen, testauksen ja muun laadunhallinnan vaiheita, joiden läpikäymistä edellytetään, että ohjelma saadaan siirrettyä tuotantoympäristöön loppukäyttäjien käyttöön.
Jokainen sovelluskehittäjän commit kulkee deployment pipelinen eli käsitteellisen “liukuhihnan” läpi
- CI-palvelin suorittaa commitille staattisen analyysin (esim. Pylintiä hyödyntäen) ja joukon testejä
- seuraavassa vaiheessa commitin aikaansaama sovelluksen uusi versio siirtyy staging-ympäristöön
- staging-ympäristössä sovelluksen uudelle versiolle suoritetaan lisää testejä
- lopulta commit siirtyy tuotantoympäristöön
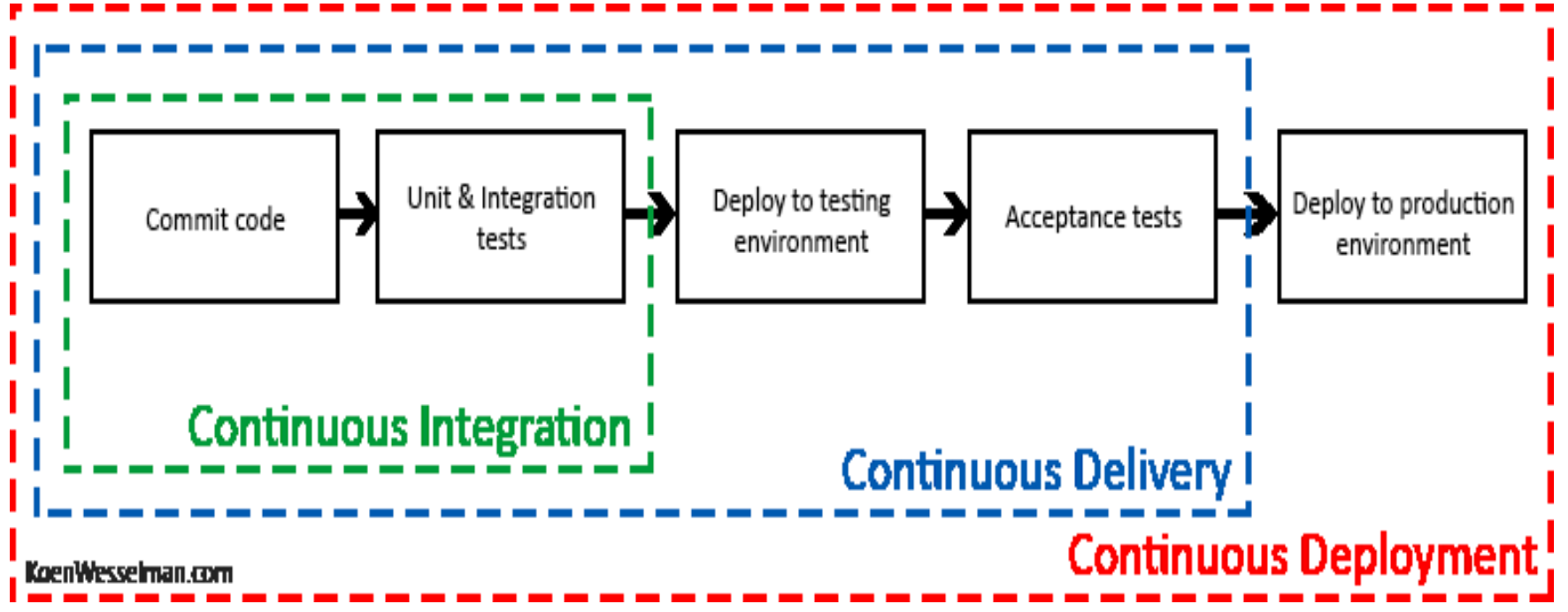
Käytännöstä, jossa jokainen CI:n läpäisevä ohjelmiston commit, eli versionhallintaan pushattu versio viedään automatisoidusti staging-palvelimelle ja siellä tapahtuvan automatisoidun hyväksymistestauksen jälkeen tuotantoon, nimitetään jatkuvaksi toimittamiseksi (engl. continuous deployment).
On olemassa tilanteita, jossa jokaista commitia ei haluta viedä automaattisesti tuotantoon. Jos viimeinen vaihe, eli tuotantoon vieminen tapahtuukin ainoastaan ihmisen toimesta nappia painamalla tai skripti suorittamalla, puhutaan jatkuvasta toimitusvalmiudesta, (engl. continuous delivery).
Viime vuosina on erityisesti suuren kokoluokan web-palveluissa (esim. Google, Amazon, Netflix, Facebook) ruvettu suosimaan tyyliä, jossa ohjelmistosta julkaistaan uusi versio tuotantoon jopa kymmeniä tai satoja kertoja päivässä. Suomessa tätä käytäntöä harjoittaa mm. monia TKT:n opiskelijoitakin työllistävä Smartly.
Tutkiva testaaminen
Jotta järjestelmä saadaan niin virheettömäksi, että se voidaan laittaa tuotantoon, on testaus suoritettava erittäin perusteellisesti. Perinteinen tapa järjestelmätestauksen suorittamiseen on perustunut ennen testausta laadittuun perinpohjaiseen testaussuunnitelmaan. Jokaisesta testistä on kirjattu testisyötteet ja odotettu tulos. Testauksen tuloksen kontrolloiminen on suoritettu vertaamalla järjestelmän toimintaa testitapaukseen kirjattuun odotettuun tulokseen.
Automatisoitujen hyväksymistestien luonne on täsmälleen samanlainen, jokaisen testin syötteet sekä odotetut tulokset ovat tarkkaan etukäteen kiinnitettyjä. Jos testaus tapahtuu pelkästään etukäteen mietittyjen testien avulla, ovat ne kuinka tahansa tarkkaan harkittuja, ei kaikkia yllättäviä tilanteita osata ennakoida.
Hyvät testaajat ovat kautta aikojen tehneet “virallisen” dokumentoidun testauksen lisäksi epävirallista “ad hoc”-testausta. Viime vuosina “ad hoc”-testaus on saanut virallisen aseman ja sen strukturoitua muotoa on ruvettu kutsumaan nimellä tutkiva testaaminen (engl. exploratory testing).
Käsitteen kehittäjä Cam Kaner määrittelee termin seuraavasti
exploratory testing is simultaneous learning, test design and test execution
Ideana on, että testaaja ohjaa toimintaansa suorittamiensa testien ohjelmistossa aiheuttaman reaktion perusteella. Testitapauksia ei suunnitella kattavasti etukäteen, sen sijaan testaaja pyrkii kokemuksensa ja suorittamiensa testien sekä kokeilujen perusteella löytämään järjestelmästä virheitä.
Tutkiva testaus ei kuitenkaan etene täysin sattumanvaraisesti, kullekin testisessiolle asetetaan jonkinlainen tavoite, eli mitä osaa tai toiminnallisuuksia sovelluksesta on tarkoitus tutkia ja minkälaisia virheitä tarkoitus etsiä.
Ketterässä ohjelmistotuotannossa tavoite voi hyvin jäsentyä yhden tai useamman user storyn määrittelemän toiminnallisuuden ympärille. Esimerkiksi verkkokaupassa voitaisiin testata ostosten lisäystä ja poistoa ostoskorista.
Tutkivassa testauksessa keskeistä on kaikkien testattavassa ohjelmistossa tapahtuvien seikkojen havainnointi. Normaaleissa etukäteen määritellyissä testeissähän havainnoidaan ainoastaan reagoiko järjestelmä odotetulla, ennakkoon määritellyllä tavalla. Tutkivassa testaamisessa kiinnitetään huomio myös varsinaisen testattavan toiminnallisuuden ulkopuolisiin asioihin.
Esimerkiksi jos huomattaisiin selaimen osoiterivillä URL https://www.verkkokauppa.com/ostoskori?id=10 voitaisiin yrittää muuttaa käsin ostoskorin id:tä ja yrittää saada järjestelmä epästabiiliin tilaan.
Tutkivan testaamisen avulla löydettyjen virheiden toistuminen jatkossa kannattaa eliminoida lisäämällä ohjelmalle sopivat automaattiset regressiotestit. Tutkivaa testaamista ei siis kannata käyttää regressiotestauksen menetelmänä, vaan sen avulla kannattaa ensisijaisesti testata uusia ominaisuuksia, jotka on toteutettu sprintin aikana.
Tutkiva testaaminen siis ei missään tapauksessa ole vaihtoehto normaaleille tarkkaan etukäteen määritellyille ja automatisoiduille testeille, vaan niitä täydentävä testauksen muoto.
Tuotannossa tapahtuva testaaminen ja laadunhallinta
Perinteisesti on ajateltu, että ohjelmiston laadunhallintaan liittyvä testaus tulisi suorittaa ennen kuin ohjelmisto tai sen uudet toiminnallisuudet otetaan käyttöön eli viedään tuotantoympäristöön. Viime aikoina erityisesti web-sovellusten kehityksessä on noussut esiin suuntaus, missä osa laadunhallinnasta tapahtuu monitoroimalla tuotannossa olevaa ohjelmistoa.
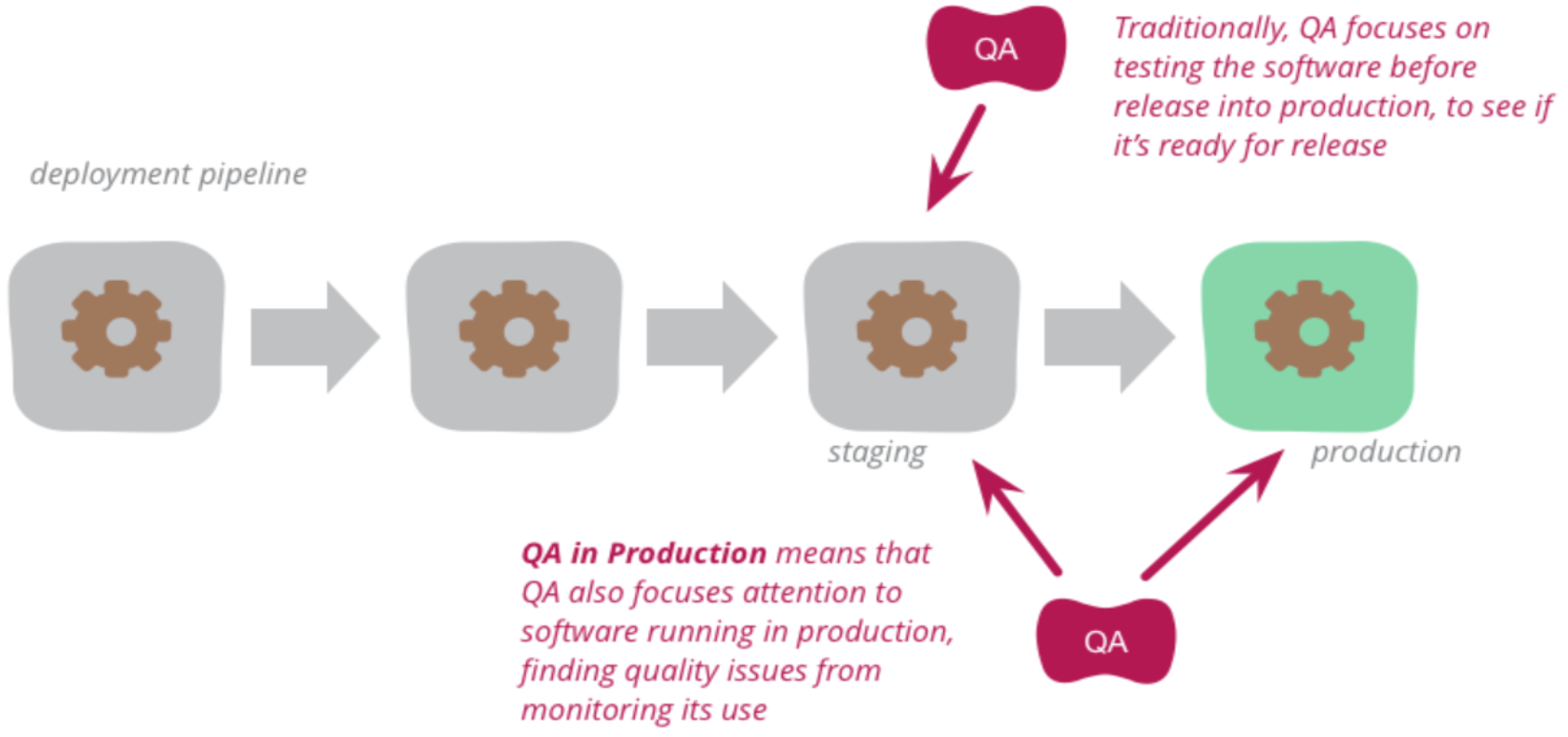
Blue-green-deployment
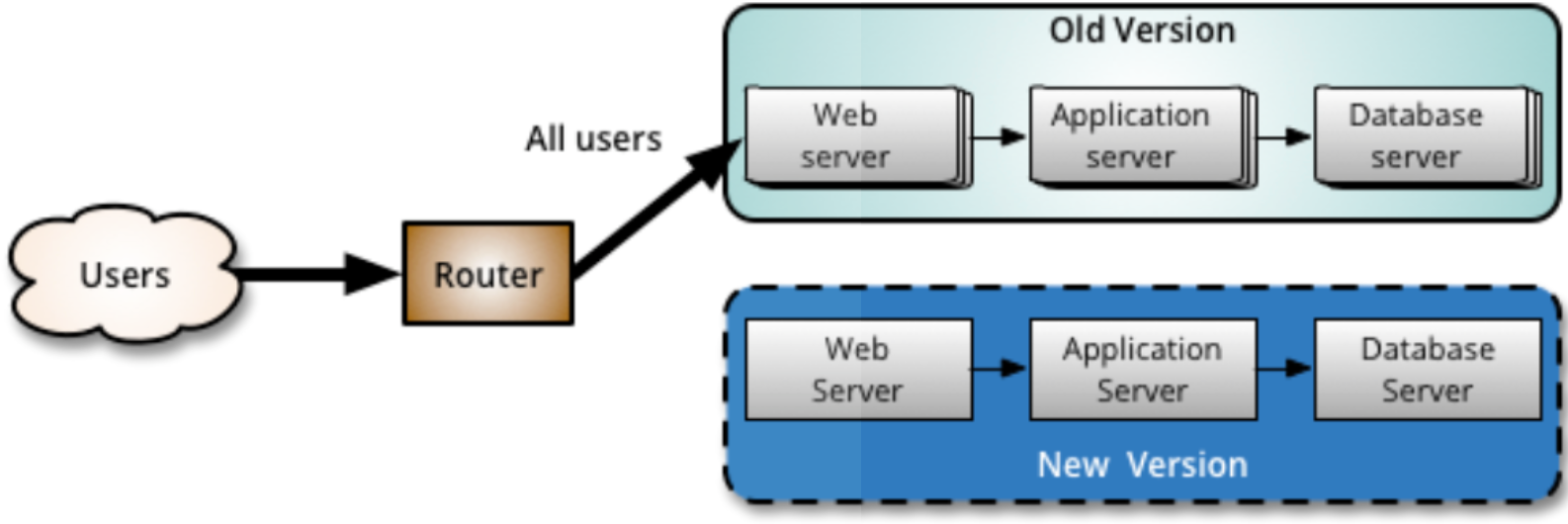
Eräs tuotannossa tapahtuvan testaamisen tekniikka on blue-green-deployment, missä periaatteena on ylläpitää rinnakkain kahta tuotantoympäristöä (tai palvelinta), joista käytetään usein nimiä blue ja green.
Tuotantoympäristöistä vain toinen on ohjelmiston käyttäjien aktiivisessa käytössä. Käyttäjien ja tuotantopalvelinten välissä oleva komponentti, esimerkiksi ns. reverse proxyna toimiva web-palvelin (kuvassa router) ohjaa käyttäjien liikenteen aktiivisena olevaan ympäristöön.
Kun järjestelmään toteutetaan uusi ominaisuus, viedään se ensin passiivisena olevaan ympäristöön.
Passiiviselle, uuden ominaisuuden sisältämälle ympäristölle voidaan sitten tehdä erilaisia testejä, esim. osa käyttäjien liikenteestä voidaan ohjata aktiivisen lisäksi passiiviseen ympäristöön ja varmistaa, että se toimii odotetulla tavalla.
Kun uuden ominaisuuden sisältävän passiivinen ympäristön todetaan toimivan ongelmattomasti, voidaan palvelinten rooli vaihtaa ja uuden ominaisuuden sisältämästä palvelimesta tulee uusi aktiivinen tuotantoympäristö. Aktiivisen tuotantoympäristön vaihto tapahtuu määrittelemällä reverse proxyna toimiva web-palvelin ohjaamaan liikenne uudelle palvelimelle.
Jos uuden ominaisuuden sisältävässä versiossa havaitaan aktivoinnin jälkeen jotain ongelmia, on mahdollista suorittaa erittäin nopeasti rollback-operaatio, eli vaihtaa vanha versio jälleen aktiiviseksi.
On tarkoituksenmukaista, että kaikki blue-green-deploymentiin liittyvät testit, niiden tulosten varmistaminen, tuotantoympäristön vaihto ja mahdollinen rollback tapahtuvat automatisoidusti.
Canary release
Blue-green-deploymentin hieman pidemmälle viedyssä versiossa canary-releasessa uuden ominaisuuden sisältävään ympäristöön ohjataan osa, esim. 5% järjestelmän käyttäjistä:
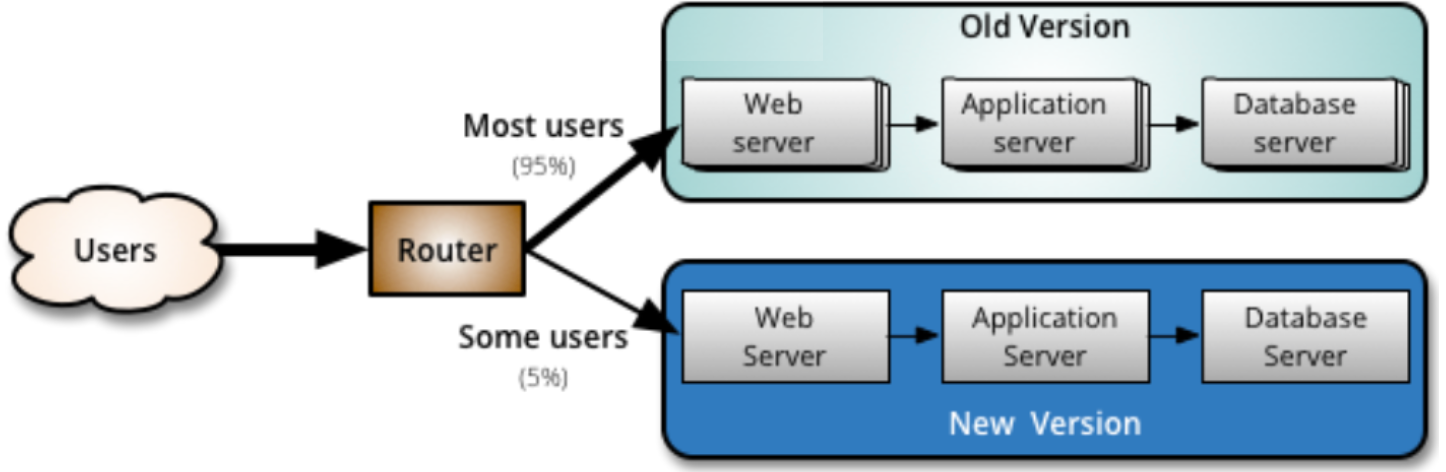
Uuden ominaisuuden sisältämää versiota monitoroidaan aktiivisesti ja jos ongelmia ei ilmene, vähitellen kaikki liikenne ohjataan uuteen versioon. Kuten blue-green-deploymentin tapauksessa, ongelmatilanteissa palautetaan käyttäjät aiempaan, toimivaksi todettuun versioon.
Uuden version toimivaksi varmistaminen siis perustuu järjestelmän monitorointiin. Jos kyseessä olisi esim. sosiaalisen median palvelu, monitoroinnissa voitaisiin tarkastella esim.:
- palvelun muistin ja prosessoriajan kulutusta sekä verkkoliikenteen määrää
- sovelluksen eri sivujen vasteaikoja eli latautumiseen menevää aikaa
- kirjautuneiden käyttäjien määrää
- luettujen ja lähetettyjen viestien määriä per käyttäjä
- kirjautuneen käyttäjän sovelluksessa viettämää aikaa
Monitoroinnissa tulee palvelimen yleisen toimivuuden lisäksi seurata käyttäjätason metriikoita (engl. business level metrics). Jos niissä huomataan eroavuuksia aiempaan, esim. kirjautuneet käyttäjät eivät lähetä keskimäärin samaa määrää viestejä kuin aiemmin, voidaan olettaa, että sovelluksen uudessa versiossa saattaa olla joku ongelma. Tälläisessä tilanteessa saatetaan tehdä rollback vanhaan versioon ja analysoida vikaa tarkemmin.
Myös canary releasejen yhteydessä testauksen ja kaiken tuotantoon vientiin liittyvän on syytä tapahtua automatisoidusti.
Nimi canary release periytyy kaivostyöläisten tavasta käyttää kanarialintuja tutkimaan sitä onko kaivoksessa myrkyllisiä kaasuja: jos kaivokseen viety lintu ei kuole, ilma on turvallista.
Tuotannossa testaaminen ja tietokanta
Edellisissä kuvissa oli merkitty järjestelmän vanhalle ja uudelle versiolle erillinen tietokantapalvelin (database server).
Tilanne ei yleensä ole tämä ja erityisesti canary releasejen yhteydessä järjestelmän molemmat versiot käyttävät yleensä samaa tietokantaa:
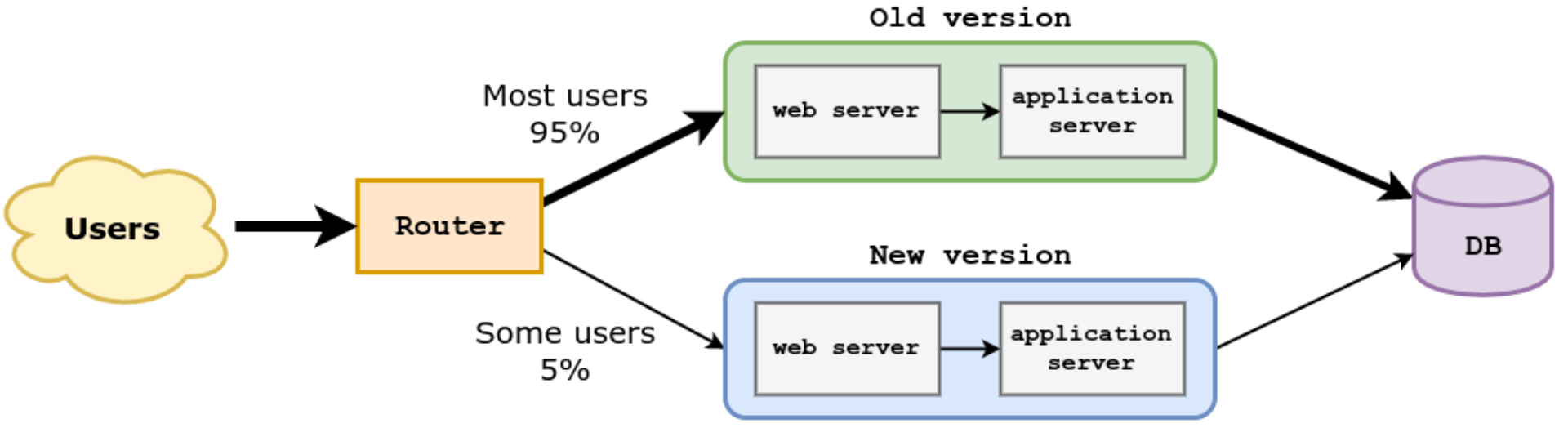
Tämä taas asettaa haasteita, jos järjestelmään toteutetut uudet ominaisuudet edellyttävät muutoksia tietokannan skeemaan, sillä canary releasejen yhteydessä tarvitaan usein yhtä aikaa sekä tietokannan uutta että vanhaa versiota.
Jos järjestelmän uusi ja vanha versio joutuvat jostain syystä käyttämään eri tietokantaa, täytyy kantojen tila synkronoida, jotta järjestelmien vaihtaminen onnistuu saumattomasti. Yhteen kantaan sovelluksen tekemät päivitykset on siis tavalla tai toisella tehtävä myös toiseen, kenties skeemaltaan jo muuttuneeseen kantaan.
Feature toggle
Canary releasea havainnollistavassa kuvassa järjestelmän uusi ja vanha versio näytettiin erillisinä palvelimina. Sama voidaan toteuttaa myös käyttäen yksittäistä palvelinta ns. feature toggleja hyödyntämällä. Sama asia kulkee myös nimillä feature flag, conditional feature ja config flag. Nimi feature toggle alkaa kuitenkin vakiintua.
Feature togglejen periaate on erittäin yksinkertainen. Koodiin laitetaan ehtolauseita, joiden avulla osa liikenteestä ohjataan vanhan toteutuksen sijaan uuteen laadunhallinnan alla olevaan toteutukseen.
Esimerkiksi sosiaalisen median palvelussa voitaisiin käyttäjälle näytettävien uutisten listaan asettaa feature toggle, jonka avulla tietyin perustein valituille käyttäjille näytettäisiinkin uuden algoritmin perusteella generoitu lista uutisia:
def recommended_news_generator(user):
if is_in_canary_release(user):
return experimental_recommendation_algorithm(user)
else:
return recommendation_algoritm(user)
Osassa 2 Lean-startup-menetelmän yhteydessä mainittu A/B-testaus toteutetaan yleensä feature togglejen avulla.
Canary releaset ja A/B-testaus eivät ole feature togglejen ainoa sovellus, niitä käytetään yleisesti myös eliminoimaan tarve pitkäikäisille feature brancheille. Eli sen sijaan, että uusia ominaisuuksia toteutetaan erilliseen versionhallinnan haaraan, joka ominaisuuksien valmistumisen yhteydessä mergetään pääkehityshaaraan, uudet ominaisuudet tehdään suoraan pääkehityshaaraan, mutta ne piilotetaan käyttäjiltä feature toggleilla.
Käytännössä feature toggle siis palauttaa aina vanhan version normaaleille käyttäjille. Sovelluskehittäjien ja testaajien taas on mahdollista valita, kumman version feature toggle palauttaa. Kun ominaisuus on valmis testattavaksi laajemmalla joukolla, se on mahdollista julkaista feature togglen avulla, esim. kehittäjäyrityksen omaan käyttöön ja tämän jälkeen osalle käyttäjistä canary releasena. Lopulta feature toggle ja vanha toteutus voidaan poistaa koodista.
Suuret internetpalvelut kuten Facebook, Netflix, Google ja Flickr soveltavat laajalti canary releaseihin ja feature toggleihin perustuvaa kehitysmallia.
Feature branchit ja merge hell
Edellisessä luvussa mainittiin feature branchit. Kyseessä on siis käytäntö, jossa uudet ominaisuudet, esimerkiksi user storyn vaatima toiminnallisuus toteutetaan ensin omaan versionhallinnan haaraansa (branch) ja ominaisuuden valmistuttua haara mergetään pääkehityshaaraan (esim. masteriin).
Monet pitävät feature brancheja versionhallinnan käytön best practicena. Viime aikoina on kuitenkin monissa piireissä ruvettu pitämään feature branchaystä ikävänä käytänteenä, sillä se johtaa helposti pahoihin merge-konflikteihin, erityisesti jos branchit ovat pitkäikäisiä.
Seurauksena pienimuotoinen integraatiohelvetti, merge hell ja kehitystiimin normipäivä erityisesti sprintin lopussa alkaa muistuttaa seuraavaa

Viime aikaisena suuntauksena on noussut esiin trunk based development, jossa pitkäikäisiä feature brancheja ei käytetä ollenkaan.
Kaikki muutokset tehdään suoraan pääkehityshaaraan, josta käytetään nimitystä trunk. Pääkehityshaara voi olla main tai jokin muu erillinen branch käytännöistä riippuen. Ohjelmiston kustakin julkaistusta versiosta saatetaan tarvittaessa tehdä oma release branch.
Trunk-pohjainen kehitys pakottaa sovelluskehittäjät tekemään pieniä, nopeasti päähaaraan mergettäviä muutoksia. Trunk-pohjainen kehitys yhdistetään usein feature toggleihin. Näin puolivalmiina olevia ominaisuuksia voidaan helposti ohjelmoida suoraan päähaaraan ja viedä tuotantoympäristöön ilman sovelluksen olemassa olevan toiminnallisuuden sotkemista.
Trunk-pohjainen kehitysmalli edellyttää sovelluskehittäjiltä erityistä kuria ja systemaattisuutta. Feature brancheihin perustuva työskentely onkin aloittelijoiden tai vähemmän kurinalaisten kehittäjien kanssa turvallisempi toimintatapa kaikista ongelmistaan huolimatta. Feature togglejen holtiton käyttö voi johtaa feature toggle -helvettiin, joten suunnittelua ja systemaattisuutta todellakin tarvitaan.
Trunk-pohjaista kehitysmallia noudattavat monet maailman suurimmista internetpalveluista, esim. Google, Facebook ja Netflix.
DevOps
Jatkuvan toimitusvalmiuden (Continuous delivery), jatkuvan toimittamisen (Continuous deployment) ja tuotannossa testaamisen soveltaminen ei useimmiten ole ollenkaan suoraviivaista.
Perinteisesti yrityksissä on ollut tarkka erottelu sovelluskehittäjien (developers, dev) ja palvelinympäristöistä vastaavien järjestelmäylläpitäjien (operations, ops) välillä. On erittäin tavallista, että sovelluskehittäjät eivät pääse edes kirjautumaan tuotantopalvelimille ja sovellusten tuotantoon vieminen sekä esim. tuotantotietokantaan tehtävät skeeman päivitykset tapahtuvat ainoastaan ylläpitäjien toimesta.
Tällaisessa ympäristössä esim. continuous deploymentin harjoittaminen on lähes mahdotonta, tilanne ajautuu helposti siihen, että uusia versioita voidaan viedä tuotantopalvelimelle vain harvoin, esimerkiksi ainoastaan 4 kertaa vuodessa.
Joustavammat toimintamallit uusien ominaisuuksien tuotantoon viemisessä vaativatkin täysin erilaista kulttuuria, sellaista, missä kehittäjät (dev) ja ylläpito (ops) työskentelevät tiiviissä yhteistyössä. Esim. sovelluskehittäjille tulee antaa tarvittava pääsy tuotantopalvelimelle tai Scrum-tiimiin tulee sijoittaa palvelinten ylläpidosta ja operoinnista huolehtivia ihmisiä. Toimintamallista, jossa kehittäjät ja ylläpitäjät, eli dev- ja ops-ihmiset, työskentelevät tiiviisti yhdessä käytetään nimitystä DevOps.
DevOps on termi, joka on nykyään laajalti esillä. Esimerkiksi työpaikkailmoituksissa voidaan arvostaa DevOps-taitoja tai etsiä ihmistä DevOps-tiimiin. On myös myynnissä mitä erilaisimpia DevOps-työkaluja. On kuitenkin jossain määrin epäselvää mitä kukin tarkoittaa termillä DevOps.
Suurin osa (järkevistä) määritelmistä tarkoittaa DevOpsilla nimenomaan kehittäjien ja järjestelmäylläpidon yhteistä työnteon ja kommunikaation tapaa, jonka pyrkimyksenä on tehdä sovelluskehityksen aikaansaannosten käyttöönotto mahdollisimman sujuvaksi. Tämän takia onkin hyvä puhua DevOps-kulttuurista.
On olemassa joukko käsitteellisiä ja teknisiä työkaluja, jotka usein liitetään DevOps-tyyliseen työskentelyyn, esim.
- automatisoitu testaus
- continuous deployment
- laskenta- ja tallennuskapasiteetin virtualisointi
- kontainerisointi (docker)
- infrastructure as code
- pilvipalveluna toimivat palvelimet ja sovellusympäristöt (PaaS, IaaS, SaaS)
Monet edellisistä ovat kehittyneet vasta viimeisen 10 vuoden aikana ja täten mahdollistaneet DevOps:in helpomman soveltamisen.
Eräs tärkeimmistä DevOps:ia mahdollistavista asioista on ollut siirtyminen yhä enenevissä määrin käyttämään fyysisten palvelinten sijaan virtuaalisia ja pilvessä toimivia palvelimia. Pikkuhiljaa myös “palvelinrautaa” on ruvettu määrittelemään koodin avulla käsiteltävien konfiguraatiotiedostojen kautta. Englanniksi tästä ilmiöstä käytetään nimitystä infrastructure as code.
Palvelinten, tallennuskapasiteetin ja verkon konfiguraatioiden automatisoitu ohjelmallisesti tapahtuva hallinnointi on siis yleistynyt koko ajan. Palvelinten konfiguraatioita voidaan tallettaa versionhallintaan ja jopa testata. Sovelluskehitys ja ylläpito ovat alkaneet muistuttaa enemmän toisiaan kuin vanhoina (huonoina) aikoina. Tämä suuntaus on johtanut siihen, että sovelluskehittäjiltä on ruvettu pikkuhiljaa vaatimaan sellaisia taitoja, jotka olivat aiemmin selkeästi järjestelmäylläpitäjien vastuulla.
Työkalujen käyttöönotto ei kuitenkaan riitä, DevOps:in soveltaminen lähtee pohjimmiltaan kulttuurisista tekijöistä, tiimirakenteista sekä asioiden sallimisesta.
Scrumin ja ketterien menetelmien eräs tärkeimmistä periaatteista on tehdä kehitystiimeistä cross functional, eli sellaisia, että ne sisältävät kaiken tietotaidon, joka tarvitaan saamaan user storyt valmiiksi definition of donen määrittelemällä laatutasolla. DevOps onkin eräs keino viedä ketteryyttä vielä askel pitemmälle, mahdollistaa se, että ketterät tiimit ovat todella monitaitoisia ja pystyvät viemään vaivattomasti toteuttamansa uudet toiminnallisuudet tuotantoympäristöön asti sekä jopa testaamaan ja operoimaan niitä tuotannossa.
Eräs parhaista DevOpsin määritelmistä on Daniel Storin käsialaa:

Yhteenveto - ketterän testauksen nelikenttä
Ketterän testauksen kenttää voidaan jäsentää alunperin Brian Maricin käsialaa olevan Agile Testing Quadrants -kaavion avulla.
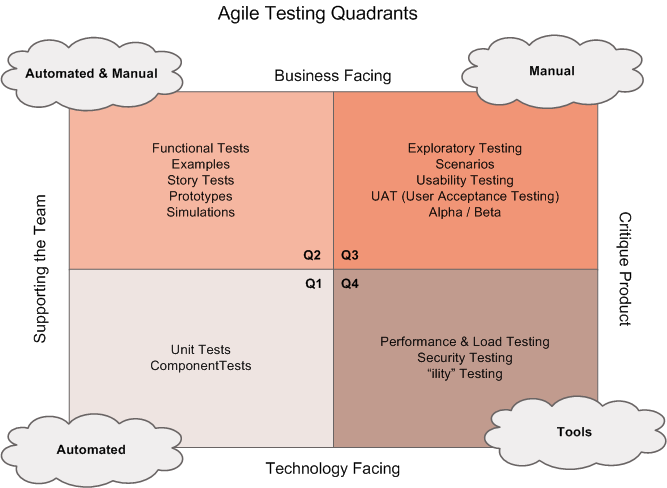
Ketterän testauksen menetelmät voidaan siis jakaa neljään luokkaan (Q1…Q4) seuraavien dimensioiden suhteen:
- business facing vs. technology facing, kohdistuuko testaus käyttäjän kokemaan toiminnallisuuteen vai enemmän ohjelmiston sisäisen toiminnallisuuden yksityiskohtiin
- supporting team vs. critique to the product, onko testien rooli toimia sovelluskehittäjien tukena vai varmistaa sovelluksen ulkoinen laatu
Testit ovat suurelta osin automatisoitavissa, mutta esim. tutkiva testaaminen (exploratory testing) ja käyttäjän hyväksymistestaus (user acceptance testing) ovat luonteeltaan manuaalista työtä edellyttäviä.
Kaikilla neljänneksillä on oma roolinsa ja paikkansa ketterässä ohjelmistokehityksessä, ja on pitkälti kontekstisidonnaista missä suhteessa testaukseen ja laadunhallintaan käytettävissä olevat resurssit kannattaa kuhunkin neljännekseen kohdentaa.
Kaavio on jo hieman vanha, alunperin vuodelta 2003 joten se ei tunne vielä käsitettä tuotannossa testaaminen.
Loppupäätelmiä testauksesta ja laadunhallinnasta
Tässä luvussa esitettävät asiat ovat osin omia, kokemuksen ja kirjallisuuden perusteella syntyneitä laadunhallintaan liittyviä mielipiteitä.
Ketterissä menetelmissä kantavana teemana on arvon tuottaminen asiakkaalle ja tätä kannattaa käyttää ohjenuorana myös arvioitaessa mitä ja miten paljon projektissa tulisi testata. Testauksella ei ole itseisarvoista merkitystä, mutta testaamattomuus alkaa pian heikentää tuotteen laatua ja hidastaa kehitysnopeutta radikaalisti. Joka tapauksessa testausta ja laadunhallintaa on tehtävä paljon ja toistuvasti, tämän takia testauksen automatisointi on yleensä pidemmällä tähtäimellä kannattavaa.
Testauksen automatisointi ei ole halpaa eikä helppoa. Väärin, väärään aikaan tai väärälle “tasolle” tehdyt automatisoidut testit voivat tuottaa enemmän harmia ja kustannuksia kuin hyötyä, erityisen suuri riski on käyttöliittymän kautta tehtävillä testeillä.
Jos ohjelmistossa on komponentteja, jotka tullaan ehkä poistamaan tai korvaamaan pian, on useimmiten järkevintä olla automatisoimatta niiden testejä. Esimerkiksi osassa 2 esitelty MVP eli Minimal Viable Product on karsittu toteutus, jonka avulla halutaan nopeasti selvittää, onko jokin ominaisuus ylipäätään käyttäjien kannalta arvokas. Jos MVP:n toteuttama ominaisuus osoittautuu tarpeettomaksi, se poistetaan järjestelmästä. MVP-periaatteella tehty ominaisuus on siis useimmiten viisasta tehdä ilman testien automatisointia.
Ongelmallista kuitenkin usein on, että kertakäyttöiseksi tarkoitettu komponentti voi jäädä järjestelmään pitkäksikin aikaa, joskus jopa pysyvästi koska sitä “ei ole aikaa” toteuttaa kunnolla.
Kokonaan uutta ohjelmistoa tai komponenttia kehitettäessä on yleensä järkevää antaa ohjelman rakenteen ensin stabiloitua ja tehdä kattavammat testit vasta myöhemmin. Komponenttien testattavuus kannattaa kuitenkin pitää koko ajan mielessä, vaikka niille ei heti testejä tehtäisikään.
Oppikirjamääritelmän mukaista TDD:tä sovelletaan melko harvoin. Välillä kuitenkin TDD on hyödyllinen väline, esim. kehitettäessä rajapintoja, joita käyttäviä komponentteja ei ole vielä olemassa. Testit voi tehdä samalla vaivalla kuin koodia käyttävän “pääohjelman”.
Kattavia yksikkötestejä ei kannata tehdä ohjelman kaikille luokille, usein vaihtoehto on tehdä integraatiotason testejä ohjelman isompien komponenttien rajapintoja vasten. Tällaiset testit pysyvät todennäköisemmin valideina komponenttien sisäisen rakenteen muuttuessa. Yksikkötestaus on hyödyllisimmillään kompleksia logiikkaa sisältävien luokkien testauksessa.
Vaikka käyttöliittymän läpi tehtävät järjestelmätason testit ovatkin riskialttiita käyttöliittymän mahdollisten muutosten takia, ovat ne usein hyödyllisin testien muoto, sillä toisin kuin esim. yksikkötestit, ne testaavat sovellusta kokonaisuudessaan (eli end to end).
Automaattisia testejä kannattaa kirjoittaa mahdollisimman paljon etenkin niiden järjestelmän komponenttien rajapintoihin, joita muokataan usein. Liian aikaisessa vaiheessa projektia tehtävät käyttöliittymän läpi suoritettavat testit saattavat aiheuttaa kohtuuttoman paljon ylläpitovaivaa, sillä testit hajoavat helposti pienistäkin käyttöliittymään tehtävistä muutoksista. Eli on syytä olla tarkkana sen suhteen missä vaiheessa käyttöliittymän läpi tapahtuva automatisoitu testaaminen kannattaa aloittaa.
Testitapausten kannattaa olla mahdollisimman paljon testattavan komponentin oikeiden käyttöskenaarioiden kaltaisia. Pelkkiä testauskattavuutta kasvattavia testejä on turha tehdä.
Testitapauksissa kannattaa käyttää mahdollisimman oikean kaltaista dataa, erityisesti järjestelmätason testeissä. Koodissa nimittäin lähes aina hajoaa jokin kun käytetään oikeaa dataa riippumatta siitä, miten hyvin testaus on suoritettu. Parasta onkin jos staging-ympäristössä on käytössä sama data kuin tuotantoympäristössä.
Oma näkemykseni testaukseen on hieman poikkeava ja jopa jossain määrin vastakkainen kuin niin sanottu testauspyramidi, eli Mike Cohenin ajatus, siitä että pääosan testeistä tulisi olla yksikkötestejä, sillä niitä on helppo tehdä, ja ne ovat nopeita suorittaa. Järjestelmää kokonaisuudessaan testaavat end to end -testit taas ovat hitaita, niitä on hankala tehdä ja ne ovat alttiita hajoamaan pienistä muutoksista, joten niiden määrän tulisi olla mahdollisimman vähäinen:
Cohenin pyramidi-idea on jo aika vanha, ja läheskään kaikki eivät ole siitä samaa mieltä. Mielipiteitä löytyy laidasta laitaan ja varmasti onkin niin, että yhtä totuutta asiasta ei ole. Kuten jo aiemminkin totesin, väärälle “tasolle” väärään aikaan tehdyt automatisoidut testit ovat suuri riski, ja koska järjestelmätason testien tekeminen on todella työlästä, piilee niissä aina hukkainvestoinnin vaara.
Ehdottomasti kaikkein tärkein asia sovelluksen laadunhallinnan kannalta on mahdollisimman usein tapahtuva tuotantoonvienti. Se taas edellyttää hyvin rakennettua deployment pipelineä, riittävän kattavaa testauksen automatisointia ja helpottuu oleellisesti, jos feature branchien sijaan käytetään trunk based development -periaatetta. Suosittelen lämpimästi että tuotantoonvienti tapahtuu niin usein kuin mahdollista, jopa useita kertoja päivässä. Tämä takaa yleensä sen, että pahoja integrointiongelmia ei synny, ja sovellukseen syntyvät regressiot havaitaan ja pystytään korjaamaan mahdollisimman nopeasti.
Tieteellinen evidenssi
Edellä esitellyistä jatkuvan toimittamisen ja laadunhallinnan käytenteiden toimivuudesta on runsaasti anekdotaalista evidenssiä ja monista osa-alueista on tehty myös akateemista tutkimusta. Myös se, että erinomaisesti menestyneet organisaatiot kuten Google, Netflix, Amazon ja Facebook luottavat näihin käytänteisiin, ja ovat jopa paikoin kehittäneet ne, puhuu niiden puolesta.
Toistaiseksi vakuuttavimman ja tieteellisesti vakaimmalla pohjalla olevan näkemyksen tarjoaa vuonna 2018 julkaistussa kirjassa Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations raportoitu vuosina 2013-2017 tehty laaja, yli 20000 vastaukseen perustuva kyselytutkimus.
Tutkimustulokset on myös julkaistu korkeatasoisilla vertaisarvioiduilla foorumeilla. Tämän osan kannalta oleellisia tuloksia käsittelee esimerkiksi Forsgren, Humble: The Role of Continuous Delivery in IT and Organizational Performance.
Tutkimuksen tuloksia summaa seuraava kaavio:
Tutkimuksen ytimessä on selvittää mitkä tekijät vaikuttavat edesauttavasti yrityksen tehokkaaseen toimintaan, kuvassa organizational performance. Kyselytutkimuksessa yrityksen tehokkuutta on mitattu seuraavilla kysymyksillä:
Select the number that best indicates degree of conformance to your organization’s goals over the past year. (1=Performed well below, 7 = Performed well above)
- Overall organizational performance
- Overall organizational profitability
- Relative market share for primary products
- Overall productivity of the delivery system Increased number of customers
- Time to market
- Quality and performance of applications
Kuvan vasemmassa reunassa taas on yrityksien harjoittamia käytänteitä: versionhallinta, testiautomaatio, jatkuva integraatio ja tuotantoonviennin automatisointi, siis “DevOps”-käytänteet, jotka muodostavat jatkuvan tuotantoonviennin (continuous delivery) ytimen. Myös näiden käyttöä vastaajaorganisaatioissa on mitattu kyselytutkimuksessa asteikolla 1-7.
Tutkimus löysi merkittävän yhteyden DevOps-käytänteiden käytön ja yrityksen tehokkaan toiminnan välillä. Mielenkiintoisena sivutuotteena käytänteiden intensiiviselle harjoittamiselle on myös korkeampi työtyytyväisyys ja vähäisempi määrä loppuunpalaneita työntekijöitä.
Ylläoleva kuva on vuonna 2016 ilmestyneestä artikkelista. Tässä vaiheessa Forsgrenin ja kumppaneiden tutkimus keskittyi siihen, miten tekniset DevOps-käytänteet vaikuttavat yrityksen tehokkuuteen.
Sittemmin tutkimuksen fokus on laajennettu myös firman johtamiskäytänteisiin, useimmat näistä liittyvät Lean-filosofiaan, joka on aiheenamme osassa 5.
On myös identifioitu lisää organisaatioiden tehokkuuteen liittyviä käytänteitä, mm. trunk based development ja tuotannossa olevan sovelluksen monitorointi.
Seuraavassa Accelerate-kirjasta lainattu kuva, joka visualisoi miten eri käytänteet edesauttavat yrityksen tehokkuutta: