Osa 2

- Kurssikoe tiistaina 16.12. klo 13.00-15.30 A111 ja CHE A110. Ohje kokeeseen
- Miniprojektin lopputoimenpiteet
- Laskarien muuttuminen kurssipisteiksi selviää täältä
Sisällysluettelo
Viikon aiheena on ohjelmistojen vaatimusmäärittely, erityisesti ketterien menetelmien näkökulma vaatimusmäärittelyyn. Käsittelemme myös hieman tuotteen hallintaa sekä koko projektin tasolla että sprintin aikana.
Typoja materiaalissa
Tee korjausehdotus editoimalla tätä tiedostoa GitHubissa.
Kurssipalaute
Kurssilla on käytössä normaalin lopussa kerättävän palautteen lisäksi ns. jatkuva palaute: voit antaa milloin vain kurssihenkilökunnalle anonyymiä palautetta osoitteessa https://norppa.helsinki.fi/targets/95023982/feedback
Vaatimusmäärittely
Ehkä keskeisin ongelma ohjelmistotuotantoprosessissa on määritellä asiakkaan vaatimukset (engl. requirements) rakennettavalle ohjelmistolle.
Ohjelmistojen vaatimusten ajatellaan jakaantuvan kahteen luokkaan. Toiminnallisilla vaatimuksilla (engl. functional requirements) tarkoitetaan kaikkia niitä asioita mitä ohjelmistolla voi tehdä, eli ohjelmiston tarjoamia toimintoja. Toinen luokka ovat ei-toiminnalliset vaatimukset (non-functional requirements), näitä ovat koko ohjelmistoa koskevat “laatuvaatimukset” (kuten käytettävyys ja tietoturva) ja ohjelmiston toimintaympäristön asettamat rajoitteet.
Vaatimusten selvittämistä, dokumentoimista ja hallinnointia kutsutaan vaatimusmäärittelyksi (engl. requirements engineering). Käytettävästä prosessimallista riippumatta vaatimusmäärittelyn tulee ainakin alkaa ennen ohjelmiston suunnittelua ja toteuttamista.
Lineaarisissa prosessimalleissa, eli vesiputousmallissa vaatimusmäärittely tehdään kokonaisuudessaan ennen ohjelmiston suunnittelua ja toteutusta. Iteratiivisessa ohjelmistokehityksessä vaatimusmäärittely tapahtuu vähän kerrallaan ohjelmiston toiminnallisuuden kasvaessa.
Vaatimusmäärittelyn vaiheet
Vaatimusmäärittelyn luonne vaihtelee paljon riippuen kehitettävästä ohjelmistosta, kehittäjäorganisaatiosta ja ohjelmistokehitykseen käytettävästä prosessimallista. Joka tapauksessa loppukäyttäjän, asiakkaan tai asiakkaan edustajan on oltava prosessissa aktiivisesti mukana.
Vaatimusmäärittely jaotellaan yleensä muutamaan työvaiheeseen:
- vaatimusten kartoitus (engl. elicitation)
- vaatimusten analyysi
- vaatimusten validointi
- vaatimusten dokumentointi
- vaatimusten hallinnointi
Useimmiten nämä työvaiheet limittyvät ja vaatimusmäärittely etenee spiraalimaisesti tarkentuen, eli ensin kartoitetaan, analysoidaan ja dokumentoidaan osa vaatimuksista. Prosessia jatketaan, kunnes haluttu määrä vaatimuksia on saatu dokumentoitua tarvittavalla tarkkuudella.
Vaatimusten kartoituksen menetelmiä
Vaatimusmäärittelyn aluksi on syytä selvittää järjestelmän sidosryhmät (engl. stakeholders) eli ne tahot, jotka ovat suoraan tai epäsuorasti tekemisissä järjestelmän kanssa. Tällaisia ovat luonnollisesti ohjelmiston aiotut loppukäyttäjät, tilaavan yrityksen päätösvaltaiset edustajat, sekä esim. tarpeen tullen niiden tahojen edustajat, jotka ovat vastuussa tietojärjestelmistä, joiden kanssa määriteltävä ohjelmisto integroituu.
Kun eri sidosryhmät on kartoitettu, käytetään “kaikki mahdolliset keinot” vaatimusten esiin kaivamiseen, esim.:
- haastatellaan sidosryhmien edustajia
- pidetään ideointisessioita asiakkaan ja sovelluskehitystiimin kesken
Alustavien keskustelujen jälkeen kehittäjätiimi voi yhdessä sidosryhmien edustajien kesken strukturoida vaatimusten kartoitusta. Usein mietitään, mitä erilaisia käyttäjärooleja sovelluksella on, ja keksitään eri käyttäjärooleille tyypillisiä sovelluksen käyttöskenaarioita.
Sovelluksesta kannattaa myös tehdä käyttöliittymäluonnoksia ja paperiprototyyppejä. Skenaarioita ja prototyyppejä tarkastelemalla ja läpikäymällä asiakas voi edelleen tarkentaa näkemystään vaatimuksista.
Jos kehitettävän sovelluksen on tarkoitus korvata olemassa oleva järjestelmä, vaatimuksia voidaan selvittää myös havainnoimalla loppukäyttäjän työskentelyä, tästä menetelmästä käytetään nimitystä etnografia.
Jos uuden sovelluksen on tarkoitus korvata olemassa oleva työskentelyprosessi, esimerkiksi tilanvarausjärjestelmä, on usein hyödyllistä tarkastella myös itse työskentelyprosessia ja koittaa miettiä sen suoraviivaistamista. Ei nimittäin ole useinkaan mielekästä toisintaa vanhaa, ehkä kankeaakin työskentelyprosessia sellaisenaan uuteen sovellukseen.
Vaatimusten analysointi, dokumentointi, validointi ja hallinnointi
Vaatimusten keräämisen lisäksi vaatimuksia täytyy analysoida. Onko vaatimuksissa keskinäisiä ristiriitoja ja ovatko ne riittävän kattavat, eli ottavatko ne huomioon kaikki mahdolliset käyttöskenaariot. On myös oleellista varmistaa, että vaatimusten toteutuminen on ylipäätään mahdollista ja taloudellisesti järkevää.
Usein on myös hyvä varmistaa, että vaatimus on todennettavissa, eli että valmiista järjestelmästä pystytään ylipäätään toteamaan noudattaako järjestelmä tätä vaatimusta. Esim. vaatimus järjestelmä on helppokäyttöinen ei ole sikäli hyvä, että helppokäyttöisyyden testaaminen on vaikeaa. Käytettävyyteenkin liittyviä vaatimuksia on mahdollista määritellä todennettavalla tavalla.
Kartoitetut vaatimukset on myös dokumentoitava muodossa tai toisessa. Ennen koodaamaan ryhtymistä sovelluskehittäjä tarvitsee “speksin”, eli kuvauksen siitä miten sovelluksen tai sen osan tulee toimia. Myös testaamista varten tarvitaan kuvaus sille, miten testattavan ohjelman halutaan toimivan.
Erityisesti vesiputousmallia käytettäessä vaatimusdokumentti toimii oleellisena osana asiakkaan ja ohjelmiston kehittäjien välistä sopimusta. Sovelluksen hinta perustuu vaatimusmäärittelyssä kuvattuun toiminnallisuuteen, ja jos asiakas muuttaakin mieltään, saattaa siitä tulla lisäkustannuksia.
Vaatimukset on myös oleellista validoida, eli tulee varmistaa, että kerätyt ja dokumentoidut vaatimukset todellakin vastaavat asiakkaan mielipidettä, ja että ne kuvaavat sellaisen järjestelmän, jonka asiakas kokee tarvitsevansa.
Vaatimuksia on myös tavalla tai toisella hallinnoitava, erityisesti jos vaatimukset muuttuvat kesken sovelluskehitysprosessin. Hallinnoinnilla siis tarkoitetaan esimerkiksi uusien asiakkaalle mieleen tulevien vaatimusten kirjaamista, jo kirjattujen vaatimusten muokkaamista, vaatimusten priorisointia ym…
Vaatimusmäärittelyprosessin luonne, eli miten vaatimukset kerätään, analysoidaan, dokumentoidaan, validoidaan ja miten niitä hallinnoidaan, vaihtelee siis paljon ohjelmistoprojektin luonteesta riippuen. Palaamme jatkossa vielä hieman tarkemmin eräisiin vaatimusmäärittelyn osa-alueisiin.
Toiminnalliset vaatimukset
Kuten mainittiin, vaatimukset jakaantuvat kahteen kategoriaan, toiminnallisiin ja ei-toiminnallisiin vaatimuksiin.
Toiminnalliset vaatimukset (engl. functional requirements) kuvaavat mitä järjestelmällä voi tehdä, eli mitä toimintoja se käyttäjän (tai muiden järjestelmien) näkökulmasta tarjoaa.
Esimerkiksi verkkokaupan toiminnallisia vaatimuksia voisivat olla seuraavat:
- asiakas voi rekisteröityä verkkokaupan käyttäjäksi
- rekisteröitynyt asiakas voi lisätä tuotteen ostoskoriin
- onnistuneen luottokorttimaksun yhteydessä asiakkaalle vahvistetaan ostotapahtuman onnistuminen sähköpostitse
- järjestelmään kirjautunut asiakas näkee oman ostoshistoriansa
- ylläpitäjä voi lisätä valikoimaan uusia tuotteita kaupan inventaarioon
- tavarantoimittaja voi päivittää järjestelmässä olevien tuotteiden hintatietoja
- päivän ostotapahtumat synkronoidaan analytiikkajärjestelmään
Toiminnallisten vaatimusten dokumentointi voi tapahtua esim. “feature-listoina” kuten kurssilla Ohjelmistotekniikka on viime aikoina tehty. Aikoinaan muodissa olivat UML-käyttötapaukset (engl. Use case), joita käytettiin kurssin myös Ohjelmistotekniikka historiallisissa versiossa. Ketterissä menetelmissä vaatimukset dokumentoidaan usein user storyina, joihin tutustumme kohta tarkemmin.
Riippumatta toiminnallisten vaatimusten dokumentointitavasta on melko yleistä, että vaatimukset ilmaistaan muodossa, jossa kerrotaan jonkin käyttäjäroolin yksittäinen järjestelmän käyttöskenaario.
Esim. tavarantoimittaja voi päivittää järjestelmässä olevien tuotteiden hintatietoja kertoo erään järjestelmän toiminnallisuuden roolin tavarantoimittaja omaaville käyttäjille.
Ei-toiminnalliset vaatimukset
Vaatimusten toinen luokka, ei-toiminnalliset vaatimukset (engl. non-functional requirements), jakautuu kahteen osa-alueeseen: laatuvaatimuksiin ja toimintaympäristön rajoitteisiin.
Laatuvaatimukset (engl. quality attributes) ovat koko järjestelmän toiminnallisuutta ohjaavia ja rajoittavia tekijöitä, esim.
- käytettävyys: minkälainen sovelluksen käyttökokemus on
- saavutettavuus: onko sovelluksen toiminnallisuus käyttökelpoista kaikille, esim. näkövammaisille tai fyysisiä rajoitteita omaaville ihmisille
- tietoturva: kenellä on pääsy järjestelmään ja siinä käsiteltävään dataan
- suorituskyky: miten nopeasti sovellus reagoi erilaisiin käyttäjän syötteisiin
- skaalautuvuus: pysyykö sovellus responsiivisena, eli riittävän nopeasti toimivana käyttäjäkuorman tai käsiteltävän datan määrän kasvaessa
- stabiilius: toipuuko järjestelmä erilaisista virhetilanteista
Kaikki laatuvaatimukset eivät ole suoraan järjestelmän käyttäjän havaittavissa, tällaisia ovat esimerkiksi
- laajennettavuus: onko sovelluksen toiminnallisuutta helppo kasvattaa jatkossa
- testattavuus: onko sovelluksen virheettömyys varmistettavissa helposti jatkokehityksen yhteydessä
On olemassa suuri määrä erilaisia kategorioita laatuvaatimuksille, esim. Wikipedia listaa niitä suuret määrät.
Toimintaympäristön rajoitteita (engl. constraints) ovat muun muassa
- toteutusteknologia: millä ohjelmointikielillä ja kirjastoilla sovellus toteutetaan, mitä tietokantoja käytetään
- käyttöympäristö: käytetäänkö sovellusta selaimella vai onko se desktop- tai mobiilisovellus
- integroituminen muihin järjestelmiin: käytetäänkö esim. jonkin ulkoisen palvelun käyttäjätunnusta kirjautumiseen tai jotain avoimien rajapintojen tarjoamaa dataa
- mukautuminen lakeihin ja standardeihin: eräs esimerkki tällaisesta on EU:n tietosuoja-asetus GDPR:n asettamat vaatimukset
Toisin kuin toiminnalliset vaatimukset, jotka kuvaavat usein järjestelmän “yksittäisiä featureita” (esim. tuotteen voi lisätä ostoskoriin), ei-toiminnalliset vaatimukset koskevat useimmiten koko järjestelmää, ja vaikuttavat siihen miten järjestelmän perusrakenne eli arkkitehtuuri tulee suunnitella. Esim. jos halutaan rakentaa verkkokauppa, joka skaalautuu miljoonille käyttäjille, tulee se perusteistaan asti rakentaa aivan erilaisella tavalla kuin verkkokauppa, jolla voi olla yhtä aikaa maksimissaan parikymmentä käyttäjää. Jos laatuvaatimukset muuttuvat ohjelmiston kehitystyön edetessä radikaalilla tavalla, muutosten tekeminen saattaa joskus olla vaikeaa ja vaatia isompaa remonttia koko sovelluksen rakennusperiaatteissa.
Vaatimusmäärittely vesiputousmallin valtakaudella
Vaatimusmäärittelyn luonne on vaihdellut suuresti aikojen saatossa.
Vesiputousmallin hengen mukaista oli, että vaatimusmäärittelyä pidettiin erillisenä tuotantoprosessin vaiheena, joka on tehtävä kokonaisuudessaan ennen suunnittelun aloittamista. Ideana oli että suunnittelun ei pidä vaikuttaa vaatimuksiin ja vastaavasti vaatimukset eivät saa rajoittaa tarpeettomasti suunnittelua.
Asiantuntijat korostivat, että vaatimusten dokumentaation on oltava kattava ja ristiriidaton. Pidettiin siis ehdottoman tärkeänä että heti alussa kerätään ja dokumentoidaan kaikki asiakkaan vaatimukset. Oli jopa suuntauksia, joissa vaatimukset haluttiin luonnollisen kielen sijaan ilmaista formaalilla kielellä eli matemaattisesti, jotta esim. ristiriidattomuuden osoittaminen olisi mahdollista.
On tunnettu tosiasia, että jos määrittelyvaiheessa tehdään virhe, joka huomataan vasta myöhemmin sovelluskehityksen aikana, esimerkiksi vasta sovellusta testatessa, on muutoksen tekeminen erittäin kallista. Tästä loogisena johtopäätöksenä oli tehdä vaatimusmäärittelystä erittäin järeä ja huolella tehty työvaihe. Ja koska vaatimusmäärittelyä ja sovelluskehitystä hoitivat eri ihmiset, tuli kaikki dokumentoida hyvin tarkalla tasolla.
Vesiputousmainen vaatimusmäärittely on hankalaa…
Kuten osassa 1 jo todettiin, ideaali jonka mukaan vaatimusmäärittely voidaan irrottaa kokonaan erilliseksi, huolellisesti tehtäväksi vaiheeksi, on osoittautunut utopiaksi.
On useita syitä, jotka johtavat siihen että vaatimusten muuttuminen on lähes väistämätöntä. Ohjelmistoja käyttävien organisaatioiden toimintaympäristö muuttuu nopeasti. Mikä on relevanttia tänään, ei ole välttämättä sitä enää 3 kuukauden päästä. Asiakkaiden on mahdotonta ilmaista tyhjentävästi tarpeitaan etukäteen, ja vaikka asiakas osaisikin määritellä kaiken etukäteen, tulee mielipide suurella todennäköisyydellä muuttumaan, kun asiakas näkee lopputuloksen.
Ongelmia aiheuttaa myös se, että huolimatta huolellisesta vaatimusmäärittelystä, ohjelmistokehittäjät eivät osaa tulkita kirjattuja vaatimuksia niin kuin vaatimukset kertonut asiakas tai loppukäyttäjä on tarkoittanut. Jos kehittäjien ja käyttäjien välillä ei ole suoraa kommunikaatiota, väärinymmärrysten syntyminen on erittäin todennäköistä.
Vaatimusmäärittelyä ei myöskään ole mahdollista tai järkevää irrottaa kokonaan suunnittelusta. Suunnittelu auttaa ymmärtämään ongelma-aluetta syvällisemmin ja se taas generoi usein muutoksia vaatimuksiin.
Ohjelmia tehdään enenevissä määrin valmiiden komponenttien, esim. open source -kirjastojen tai verkossa olevien SaaS (Software as a Service) -palveluiden varaan, ja tämäkin on oleellista ottaa huomioon vaatimusmäärittelyssä.
Jos suunnittelu ja toteutustason asiat otetaan huomioon vaatimusmäärittelyssä, on vaatimusten muotoilu ja priorisointikin helpompaa: näin on mahdollista edes jollain tavalla arvioida vaatimusten toteuttamisen hintaa.
Ilman suunnittelun ja toteutuksen huomioimista riskinä on, että asiakas haluaa vaatimuksen sellaisessa muodossa, joka moninkertaistaa toteutuksen hinnan verrattuna periaatteessa asiakkaan kannalta yhtä hyvään, mutta hieman eri tavalla muotoiltuun vaatimukseen.
Vaatimusmäärittely iteratiivisessa ja ketterässä ohjelmistokehityksessä
2000-luvun iteratiivisen ja ketterän ohjelmistokehityksen tapa on integroida kaikki ohjelmistotuotannon vaiheet yhteen. Ohjelmistoprojektit toki aloitetaan edelleenkin vaatimusmäärittelyllä, mutta alustava vaatimusmäärittely on vasta suuntaa antava ja sitä ei välttämättä ole tehty tarkalla tasolla kuin muutaman ensimmäisen iteraation tarpeiden verran.
Ketterän vaatimusmäärittelyn hengen mukaista on, että asiakas (Scrumia käytettäessä product owner) priorisoi vaatimukset siten, että kuhunkin iteraatioon valitaan toteutettavaksi ne vaatimukset, jotka tuovat asiakkaalle mahdollisimman paljon liiketoiminnallista arvoa. Ohjelmistokehittäjät arvioivat vaatimusten toteuttamiseen tarvittavaa työmäärää, ja päättävät sen kuinka paljon he voivat ottaa kuhunkin iteraatioon toteutettavia vaatimuksia.
Jokaisen iteraation aikana tehdään määrittelyä, suunnittelua, ohjelmointia ja testausta siinä määrin kuin tarve vaatii. Vaatimusmäärittelykin siis tarkentuu projektin kuluessa. Jokaisen iteraation on tarkoitus saada aikaan valmiita lisätoiminnallisuuksia kehitettävään sovellukseen. Jokaisen iteraation tuotos toimiikin syötteenä seuraavan iteraation vaatimusten määrittelyyn.
Ohjelmiston kasvaessa iteratiivisesti ja inkrementaalisesti pala palalta mahdollistaakin sen, että sovellus voidaan viedä tuotantokäyttöön eli todellisten käyttäjien käytettäväksi jo ennen sovelluksen valmistumista.
Tällä on monia etuja: sovellus voi ruveta tuottamaan rahallista arvoa jo ennen sovelluskehitysprojektin päättymistä, ja todellisilta käyttäjiltä saatavan palautteen avulla vaatimusmäärittelyn ja sovelluksen jatkokehityksen suuntaa on vielä mahdollista tarkentaa.
Kattavana teemana ketterässä ohjelmistotuotannossa ja siihen liittyvässä vaatimusmäärittelyssä onkin kaikin mahdollisin tavoin tuottaa asiakkaalle maksimaalisesti arvoa.
Uuden ajan vaatimusmäärittely: Lean startup
Eric Riesin vuonna 2011 julkaisema kirja The Lean startup kuvaa/formalisoi systemaattisen tavan kartoittaa vaatimuksia erityisen epävarmoissa konteksteissa, kuten startup-yrityksissä.
Malli perustuu kolmiosaisen build-measure-learn -syklin toistamiseen:
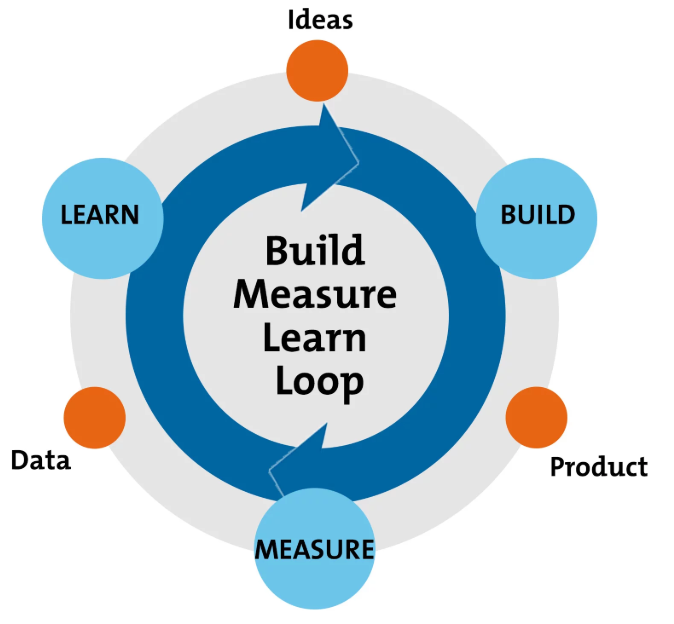
Esim. internetpalveluja tai mobiilisovelluksia rakennettaessa käyttäjien tarpeista, eli järjestelmän vaatimuksista ei ole minkäänlaista varmuutta, voidaan vain tehdä oletuksia siitä mitä ihmiset haluaisivat käyttää. Alkuvaiheessahan järjestelmällä ei edes ole vielä asiakkaita tai käyttäjiä, joiden mielipidettä voitaisiin kysyä.
Periaatteena on ottaa lähtökohdaksi jokin idea siitä, mitä käyttäjät haluavat ja tehdään hypoteesi miten asiakkaat käyttäytyisivät, jos kyseinen järjestelmä/toiminnallisuus/ominaisuusjoukko olisi toteutettu.
Tämän jälkeen rakennetaan nopeasti niin sanottu minimum viable product (MVP), joka toteuttaa ominaisuuden. Minimum viable productillä ei ole mitään yhtenäistä kaikkien hyväksymää määritelmää, mutta esim. Wikipedia sanoo seuraavasti
A minimum viable product (MVP) is a product with just enough features to satisfy early customers and provide feedback for future product development.
MVP on siis jonkinlainen minimalistinen toteutus ohjelmistosta tai jostain sen uudesta ominaisuudesta, jonka motivaationa on käyttäjäpalautteen kerääminen. MVP ei ole vielä kaikilta osin ohjelmistokehityksen parhaiden käytänteiden mukaan rakennettu ja se on usein ominaisuuksiltaan rajoitettu, sisältäen ainoastaan sen verran toiminnallisuutta kuin hypoteesin mittaamiseen minimissään tarvitaan.
MVP toteutetaan mahdollisimman nopeasti ja laitetaan tuotantokäyttöön oikeille käyttäjille. Tämän jälkeen mitataan miten käyttäjät toimivat MVP:n toteuttaman uuden toiminnallisuuden suhteen. Jos esimerkiksi kyseessä on internetpalvelu, voidaan mitata kuinka moni ihminen löytää palvelun etusivulle, rekisteröityy käyttäjäksi, kirjautuu järjestelmään, kirjautuu vielä viikon jälkeen rekisteröitymisestä ym.
Jos MVP koskee jotain järjestelmään toteutettua uutta ominaisuutta, käytetään usein A/B-testausta: uusi ominaisuus julkaistaan vain osalle käyttäjistä, loput jatkavat vanhan ominaisuuden käyttöä. MVP:n avulla testattava uusi ominaisuus voisi olla esim. verkkokaupan uudenlainen suosittelualgoritmi ja koejärjestelyllä voidaan helposti mitata tuottaako testattava ominaisuus suuremman määrän ostoksia kuin järjestelmän aiempi versio.
Käyttäjien oikeasta järjestelmästä mitattua käyttäytymistä verrataan siis alussa asetettuun hypoteesiin ja näin pystytään oppimaan, olivatko toteutetut vaatimukset järjestelmän käytön suhteen toivottavia, eli käytetäänkö ominaisuuksia, saako niiden avulla hankittua lisää maksavia asiakkaita, sitouttavatko ne käyttäjiä enemmän sovelluksen käyttöön, saavatko ne käyttäjän tuhlaamaan enemmän rahaa ym…
Testattavan idean osoittautuessa käyttökelpoiseksi, tehdään sovellukseen MVP:n sijaan robustimpi toteutus kyseisestä toiminnallisuudesta. Jos taas toteutettu idea ei osoittautunut hyväksi, voidaan palata järjestelmän edelliseen versioon ja jatkaa build-measure-learn -sykliä tekemällä hypoteesi jostain muusta ideasta.
Lean startup -menetelmällä on siis tarkoitus oppia systemaattisesti ja mahdollisimman nopeasti mitä asiakkaat haluavat, siispä menetelmän voidaan ajatella olevan eräänlainen vaatimusten analysointi- ja validointimentelmä.
Nimestään huolimatta Lean startup -menetelmää käytetään erityisen paljon suurissa internetpalveluita tuottavissa yhtiöissä, kuten Facebook, Google, Netflix ja Amazon. Myös pelialalla menetelmä on aktiivisessa käytössä, kun pelien koukuttavuutta yritetään maksimoida.
Vaatimusmäärittely ja projektisuunnittelu ketterässä prosessimallissa
Käydään seuraavaksi läpi yleinen tapa vaatimustenhallintaan ja projektisuunnitteluun ketterässä ohjelmistotuotantoprojektissa.
Tapa pohjautuu Scrumin ja eXtreme Programming:n eli XP:n eräiden käytänteiden soveltamiseen. Lähteenä on monia kirjoja ja blogikirjoituksia, mm. verkosta löytyvät Henrik Kniberg: Scrum and XP from the trenches, James Shore: Art of Agile development ja Jeff Sutherland ym.:A Scrum book sekä Mike Cohnin loistavat kirjat Agile Estimation and Planning ja User stories applied.
User story
Ketterän vaatimusmäärittelyn tärkein työväline on user story. Samasta asiasta käytetään joskus suomenkielistä termiä käyttäjätarina. Käännös ei kuitenkaan ole täysin vakiintunut, joten käytämme jatkossa englanninkielistä termiä.
Alan suurimman auktoriteetin Mike Cohnin mukaan:
A user story describes functionality that will be valuable to either user or purchaser of software. User stories are composed of three aspects:
- A written description of the story, used for planning and reminder
- Conversations about the story to serve to flesh the details of the story
- Tests that convey and document details and that will be used to determine that the story is complete
User storyt siis kuvaavat loppukäyttäjän kannalta arvokasta toiminnallisuuksia. Jotta näin olisi, kirjoitetaan storyt asiakkaan kannalta ymmärrettävällä kielellä.
Määritelmän alakohtien 1 ja 2 mukaan user story on karkean tason tekstuaalinen kuvaus ja lupaus/muistutus siitä, että toiminnallisuuden tarkka kuvaus on selvitettävä asiakkaan kanssa.
Seuraavat voisivat olla verkkokauppasovelluksen user storyjen kuvauksia (written description):
- asiakas voi lisätä tuotteen ostoskoriin
- asiakas voi poistaa ostoskorissa olevan tuotteen
- asiakas voi maksaa luottokortilla ostoskorissa olevat tuotteet
User story ei siis ole perinteinen vaatimusmääritelmä, joka ilmaisee tyhjentävästi toiminnallisuuksien vaatimukset; user story on pikemminkin “placeholder” vaatimukselle, eli muistilappu ja lupaus siitä, että toiminnallisuuden vaatimukset tullaan selvittämään riittävällä tasolla ennen kuin user story toteutetaan.
Määritelmän kolmas alikohta sanoo, että Storyyn kuuluu Tests that convey and document details and that will be used to determine that the story is complete. Storyyn siis pitäisi liittyä myös joukko testejä tai kriteereitä, joiden perusteella voidaan katsoa että story on toteutettu.
Se, miten user storyihin liittyvät hyväksymäkriteerit ilmaistaan, vaihtelee hyvin paljon. Parhaassa tapauksessa ne ovat automaattisesti suoritettavissa olevia testejä. Kyseessä voi myös olla lista toimintaskenaarioita, jotka on jollain tavalla kirjattu storyn yhteyteen. Melko tavallista on kuitenkin, että niitä ei kirjata mitenkään, vaan product owner, asiakkaan edustaja tai joku laadunhallinnasta vastaava taho hyväksyy storyn valmiiksi testaamalla manuaalisesti vastaavaa toiminnallisuutta järjestelmästä.
Mike Cohnin kolmiosaisen määritelmän kanssa täsmälleen samansisältöisen mutta hieman eri sanoin muotoillun määritelmän user storyille on antanut Ron Jeffries, jonka sanoin user story on card, conversation, confirmation (CCC), eli
- card: muistilappumainen usein jopa fyysinen pahvikortti, ei siis missään tapauksessa vesiputousmainen mappiin talletettava laaja vaatimusmäärittelydokumentti
- conversation: jotta storyn voi toteuttaa tarvitaan paljon keskustelua sovelluskehittäjien ja product ownerin, asiakkaiden, loppukäyttäjien ym. välillä, jotta saadaan selville mistä storysta todella on kysymys
- confirmation: kriteerit minkä perusteella voidaan todeta storyn olevan toteutettu valmiiksi
Esimerkki user storysta
Ennen kuin etätyöskentely yleistyi pandemian myötä oli tapana kirjoittaa user storyn kuvaus pienelle noin 10-15 cm pahvikortille tai postit-lapulle. Scott Amblerilta lainattu esimerkki

Kortin etupuolelle on kirjoitettu lyhyt kuvaus storyn sisällöstä, prioriteetti ja estimaatti. Estimaatilla tarkoitetaan kortin toiminnallisuuden toteuttamisen työmääräarviota. Palaamme estimointiin pian tarkemmin.
Kortin takapuolella suhteellisen informaalilla kielellä kirjoitettu joukko storyn hyväksymiskriteerejä.
Usein hyväksymiskriteerit kuvaavat joukon erilaisia ehtoja sille, miten storyn kuvaaman toiminnallisuuden tulee käyttäytyä eri tilanteissa. Esim. nyt storyn sisältö on As a student I want to purchase a parking pass, eli opiskelija voi ostaa parkkiluvan, hyväksymäkriteerit tarkentavat erilaisia ostamiseen liittyviä ehtoja:
- parkkiluvan ostajan on oltava ilmoittautunut läsnäolleeksi
- parkkilupa myönnetään kuukaudeksi kerrallaan
- on mahdollista ostaa vain yksi parkkilupa kuukaudessa
Hyväksymäkriteerit ovat tuloksena keskusteluista, joita storyn toiminnallisuuden rajaamisesta käydään product ownerin tai asiakkaan kanssa. Usein hyväksymäkriteerit nimenomaan rajaavat toiminnallisuutta. Esimerkkinä olevan storyn kriteerit jättävät vielä paljon yksityiskohtia auki vaikkapa maksamisen suhteen – miten se tapahtuu? Kriteerejä voisi täydentää seuraavasti
- parkkilupa maksetaan käteisellä tai verkkopankissa
- verkkomaksun tapauksessa on käytettävä opiskelijalle henkilökohtaisesti generoitua viitenumeroa
Nykyään etänä tai hybridisti työskentelevät tiimit käyttävät postit-lappujen ja pahvikorttien sijaan jotain elektronista järjestelmää, esim. Jiraa tai GitHub projectsia user storyjen kirjaamiseen.
Hyvän user storyn kriteerit
Edellinen esimerkki
As a student I want to purchase a parking pass so that I can drive to school
on formuloitu monin paikoin suositussa muodossa
As a type of user, I want functionality so that business value
Näin muotoilemalla on ajateltu, että user story kiinnittää huomion siihen, kenelle kuvattava järjestelmän toiminto tuottaa arvoa. Muoto ei oikein taivu suomenkielisiin kuvauksiin, joten sitä ei tällä kurssilla käytetä.
Tätä muotoa on myös ruvettu kritisoimaan muun muassa siksi, että kiinnittää liikaa huomioita siihen miten story kirjataan, itse asian eli mistä storyssa on kysymys sijaan. Formaatin suosio onkin laskusuunnassa:
Bill Wake luettelee artikkelissa INVEST in good User Stories kuusi user storyille toivottavaa ominaisuutta:
- Independent
- Negotiable
- Valuable
- Estimable
- Small
- Testable
Kriteerin Independent mukaan user storyjen pitäisi olla toisistaan mahdollisimman riippumattomia eli storyjen kuvaamia toiminnallisuuksia pitäisi pystyä toteuttamaan riippumatta toisten storyjen tilanteesta. Tämä taas antaa product ownerille enemmän vapausasteita storyjen priorisointiin, eli sen määrittelyyn missä järjestyksessä sovelluksen toiminnallisuudet valmistuvat.
On toki tilanteita, joissa storyjen keskinäistä riippuvuutta ei voi välttää, esimerkiksi verkkokaupan storyjen lisää tuote ostoskoriin ja poista tuote ostoskorista tapauksessa.
Hyvä user story on negotiable, eli se ei ole tyhjentävästi kirjoitettu vaatimusmäärittely vaan lupaus siitä että asiakas ja toteutustiimi sopivat tarvittavalla tarkkuudella storyn toiminnallisuuden sisällön ennen kuin story otetaan toteutettavaksi.
Valuable tarkoittaa, että storyn tulee kuvata käyttäjälle arvokkaita ominaisuuksia, jotka on muotoiltu käyttäen asiakkaan kieltä, ei teknistä jargonia.
Hyvänä käytäntönä pidetään että user story kuvaa järjestelmän kaikkia osia koskevaa (esim. käyttöliittymä, bisneslogiikka, tietokanta) eli “end to end”-toiminnallisuutta, eikä pelkästään yksittäistä järjestelmän teknistä kerrosta koskevaa, käyttäjän kannalta näkymätöntä teknistä ratkaisua.
Esimerkiksi lisää jokaisesta asiakkaasta rivi tietokantatauluun customers ei olisi suositeltava muotoilu user storylle, sillä se ei ole kirjattu käyttäjän kannalta ymmärrettävällä tavalla ja ottaa kantaa ainoastaan tietokantakerrokseen.
Estimable taas sanoo, että user storyn toteuttamisen vaatima työmäärä pitää olla arvioitavissa kohtuullisella tasolla.
Työmäärän arviointi onnistuu paremmin jos user storyt ovat riittävän pieniä, small. User story on ehdottomasti toiminnallisuudeltaan liian iso, jos se ei ole toteutettavissa yhdessä sprintissä. Juuri ja juuri yhdessä sprintissä toteutettavissa oleva story on myöskin huomattavan riskialtis, parempi koko storylle onkin lähempänä yhden päivän kuin vaikkapa viikon vaadittavaa työmäärää.
Liian suuret user storyt tulee jakaa osiin ennen kuin ne otetaan toteutettavaksi. Esimerkiksi verkkokaupassa voisi olla käyttötapaus kaupan ylläpitäjä voi kirjautua sivulle, lisätä ja päivittää tuotteiden tietoja sekä tarkastella asiakkaille tehtyjen toimitusten listaa tulisi ehdottomasti jakaa useaan osaan:
- ylläpitäjä voi kirjautua sovellukseen
- ylläpitäjä voi lisätä tuotteita valikoimaan
- ylläpitäjä voi päivittää tuotteiden tietoja
- ylläpitäjä voi tarkastella asiakkaille tehtyjen toimitusten listaa
Kuudes toivottu ominaisuus on testattavuus, testability, eli toteutettaviksi valittavien user storyjen tulisi olla sellaisia, että niille on mahdollista tehdä testit tai laatia kriteerit, joiden avulla on mahdollista yksikäsitteisesti todeta, onko story toteutettu hyväksyttävästi. Ei-toiminnalliset vaatimukset (esim. suorituskyky, käytettävyys) aiheuttavat usein haasteita testattavuudelle.
Esimerkiksi verkkokaupan user story kaupan tulee toimia tarpeeksi nopeasti kovassakin kuormituksessa on mahdollista muotoilla testattavaksi esimerkiksi seuraavasti: käyttäjän vasteaika saa olla korkeintaan 0.5 sekuntia 99% tapauksissa jos yhtäaikaisia käyttäjiä sivulla on maksimissaan 1000.
Kuten tulemme myöhemmin tässä osassa toteamaan, user storyjen ei kannata olla koko aikaa hyvän storyn INVEST-kriteerien mukaista. Kriteeristö koskeekin kokonaisuudessa oikeastaan vain korkean prioriteetin user storyjä eli sellaisia, jotka tullaan toteuttamaan lähitulevaisuudessa. Matalamman prioriteetin storyt voivat aivan hyvin olla vielä isompia ja testattavuudeltaan sekä työmääräarvioiltaan epämääräisempiä. Storyt tulee jakaa ja saattaa INVEST-kriteerien mukaiseksi viimeistään siinä vaiheessa kun story nousee lähemmäs prioriteettijärjestyksen huippua.
Product backlog
Edellisellä viikolla Scrumin yhteydessä puhuttiin product backlogista, joka on siis priorisoitu lista asiakkaan tuotteelle asettamista vaatimuksista eli toivotuista ominaisuuksista ja toiminnoista. Nykyään käytäntönä on, että product backlog koostuu nimenomaan user storyistä.
Backlog projektin alussa
Projektin aluksi kannattaa heti ruveta etsimään ja määrittelemään user storyja ja muodostaa näistä alustava product backlog. Scrumia sovellettaessa tämä tehdään useimmiten ennen ensimmäisen sprintin alkua. Joskus tästä vaiheesta käytetään nimitystä nollasprintti.
Alustavan product backlogin muodostamisessa ovat käytettävissä kaikki yleiset vaatimusten kartoitustekniikat:
- haastattelut
- brainstormaus
- workshopit
Alustavan user storyjen keräämisvaiheen ei ole tarkoituksenmukaista kestää kovin kauaa, maksimissaan muutaman päivän (tähän on toki poikkeuksia riippuen kehitettävän ohjelmiston koosta ja kehittäjäorganisaatiosta). User storyn luonne (muistilappu ja lupaus, että vaatimus tarkennetaan ennen toteutusta) tekee siitä hyvän työkalun projektin aloitukseen. Turhiin yksityiskohtiin ei ole tarkoitus puuttua ja ei edes kannata tavoitella täydellistä ja kattavaa listaa vaatimuksista, sillä storyjä tarkennetaan, muokataan ja luodaan lisää myöhemmin. User storyn määritelmän toinen kohtahan on conversations about the story to serve to flesh the details of the story, ja tämä tarkoittaa sitä että storyn sisältö saattaa elää ajan mittaan.
Kun alustava lista user storyistä on kerätty, ne priorisoidaan ja niiden vaatima työmäärä arvioidaan projektille tarkoituksenmukaisella tasolla. Näin muodostuu alustava product backlog, eli priorisoitu lista vaatimuksista.
Backlogin priorisointi
Product backlog on siis priorisoitu lista user storyjä.
Kuten Scrumin esittelyn yhteydessä todettiin, priorisoinnista vastaa product owner. Prioriteetti määrää järjestyksen, missä ohjelmistokehittäjät toteuttavat backlogilla olevia toiminnallisuuksia.
Priorisoinnin tavoitteena on maksimoida asiakkaan kehitettävästä ohjelmistosta saama hyöty ja arvo. Tärkeimmät asiat pyritään toteuttamaan mahdollisimman nopeasti, jotta tuotteesta saadaan alustava versio markkinoille mahdollisimman pian.
User storyjen priorisointiin vaikuttaa storyn kuvaaman toiminnallisuuden asiakkaalle tuovan arvon lisäksi ainakin storyn toteuttamiseen kuluva työmäärä sekä storyn kuvaamaan ominaisuuteen sisältyvä tekninen riski.
Ei ole siis kokonaistaloudellisesti edullista tehdä priorisointia välttämättä pelkästään perustuen asiakkaan user storyistä saamaan arvoon, joku story voi tuottaa paljon arvoa, mutta voi olla toteutukseltaan liian työläs. Parempi sijoitetun pääoman tuotto eli ROI voidaan saada jollain vaihtoehtoisella storylla, joka on toteutukseltaan vähemmän työläs.
Myös projektiin liittyvät tekniset riskit kannattaa ottaa priorisoinnissa huomioon. Tekninen riski voi olla esim. se, onko jokin ohjelmiston kannalta kriittinen ominaisuus ylipäätään mahdollista toteuttaa tehokkaasti ja taloudellisesti järkevin resurssein. Tällainen riskitekijä kannattaa selvittää mielummin heti kuin vasta siinä vaiheessa, kun projektiin on jo sijoitettu suuri määrä resursseja.
Estimointi eli työmäärän arviointi
User storyjen vaatiman työmäärän arvioimiseen on kaksi motivaatiota:
- auttaa asiakasta priorisoinnissa
- mahdollistaa koko projektin tai tiettyjä toiminnallisuuskokonaisuuksia sisältävien versioiden viemän ajan ja taloudellisen panostuksen summittainen arviointi
Työmäärän arvioimiseen on kehitetty vuosien varrella useita erilaisia menetelmiä. Kaikille yhteistä on se, että ne eivät toimi kunnolla, eli tarkkoja työmääräarvioita on mahdoton antaa. Joskus työmäärän arvioinnista käytetäänkin leikillisesti termiä guesstimation koska työmääräarviointi on lopulta useimmiten lähinnä arvailua.
Estimointiin liittyvää epävarmuutta kuvaa käsite cone of uncertainty:

Eli mitä kauempana tuotteen/ominaisuuden valmistuminen on, sitä epätarkempia työmääräarviot ovat. Tämä taas johtuu siitä, että tuntemattomien epävarmuustekijöiden määrä alussa on suuri, mutta kun tuotteen rakentamisessa ollaan pidemmällä, ymmärrys kasvaa ja työmäärienkin arviointi alkaa olla realistisempaa. Jos esim. mietitään user storya tuotteen voi poistaa ostoskorista, on järjestelmän alustavassa määrittelyvaiheessa todella vaikea antaa minkäänlaista työmääräarviota storylle. Kun sovelluskehitys etenee ja tiedetään miten ostoskori teknisesti toteutetaan, minkälainen sovelluksen käyttöliittymä on jne, muuttuu tuotteen ostoskorista poistamista koskevan storyn työmääräarvion tekeminen jo huomattavasti helpommaksi.
Suhteelliseen kokoon perustuva estimointi
Ketterät ohjelmistotuotantomenetelmät ottavat itsestäänselvyytenä sen, että estimointi on epävarmaa ja tarkentuu vasta projektin kuluessa. Koska näin on, pyritään vahvoja estimointiin perustuvia lupauksia ohjelmiston valmistumisaikatauluista välttämään.
On olemassa jonkin verran evidenssiä (ks Cohn: Agile estimation and planning, luku 8) siitä, että vaikka ominaisuuksien toteuttamiseen menevän tarkan ajan arvioiminen on vaikeaa, osaavat ohjelmistokehittäjät jossain määrin arvioida eri tehtävien vaatimaa työmäärää suhteessa toisiinsa.
Esimerkkejä tällaisestä suhteellisesta estimoinnista ovat
- user storyn tuotteen lisääminen ostoskoriin toteuttaminen vie yhtä kauan kuin user storyn tuotteen poistaminen ostoskorista toteuttaminen
- user storyn ostoskorissa olevien tuotteiden maksaminen luottokortilla toteuttaminen taas vie noin kolme kertaa kauemmin kun edelliset
Ketterissä menetelmissä käytetään usein (tai ainakin suositellaan käytettäväksi) suhteelliseen kokoon perustuvaa estimointia, joissa usein arvioinnin yksikkönä käytetään abstraktia aikamäärettä story point, joka ei välttämättä vastaa mitään todellista aikamäärettä.
Verkkokaupan tapauksessa voitaisiinkin määrittää, että user storyn tuotteen lisääminen ostoskoriin toteuttaminen työmääräarvio on yksi story point. Tällöin tuotteen poistaminen ostoskorista toteuttaminen olisi myös suhteelliselta estimaatiltaan yksi story point ja ostoskorissa olevien tuotteiden maksaminen luottokortilla kolme story pointia.
Estimoinnin suorittaminen
Estimointi tehdään yhteistyössä kehitystiimin ja product ownerin kanssa. Product ownerin roolina on tarkentaa estimoitaviin user storeihin liittyviä vaatimuksia siinä määrin että kehitystiimi ymmärtää tarkasti mistä on kyse. Varsinaisen estimoinnin eli työmääräarvion tekee kuitenkin aina ohjelmistokehitystiimi. Tämä on tärkeää, sillä ainoastaan sovelluskehittäjillä on edes jossain määrin realistisia edellytyksiä arvioiden tekemiseen.
Kuten edellisellä viikolla mainittiin, määritellään ketterissä projekteissa yleensä definition of done, eli se yleinen taso mitä valmiilla tarkoitetaan. Useimmiten valmiin määritellään sisältävän user storyn määrittelyn, suunnittelun, toteutuksen, automatisoitujen testien tekemisen, integroinnin muuhun sovellukseen, dokumentoinnin ja joskus jopa tuotantoonviemisen.
Estimoinnissa tuleekin arvioida user storyn viemä aika definition of donen tarkkuudella, eikä missään nimessä esim. ottaen huomioon pelkkä ohjelmointiin kuluva aika.
Usein estimointia auttaa user storyn pilkkominen teknisiin työvaiheisiin. Esimerkiksi story tuotteen lisääminen ostoskoriin voisi sisältää toteutuksen kannalta seuraavat tekniset tehtävät (task):
- tarvitaan sessio, joka muistaa asiakkaan
- oliot ja tietorakenteet ostoskorin ja ostoksen esittämiseen
- laajennus tietokantaskeemaan
- html-näkymää päivitettävä tarvittavilla painikkeilla
- kontrolleri painikkeiden käsittelyyn
- yksikkötestit kontrollerille ja domain-olioille
- hyväksymätestien automatisointi
Työvaiheisiin pilkkominen saattaa vaatia myös teknistä suunnittelua, esim. täytyy miettiä, miten ohjelman rakennetta on muokattava, jotta uusi toiminnallisuus saadaan järkevästi toteutettua.
Jos kyseessä on samantapainen toiminnallisuus kuin joku aiemmin toteutettu, voi estimointi tapahtua ilman user storyn vaatimien erillisten työvaiheiden miettimistä, suhteuttamalla estimoitava toiminnallisuus aiemmin toteutettuihin storyihin.
Koska estimointi on joka tapauksessa suhteellisen epätarkkaa, estimointiin ei kannata käyttää turhan paljoa aikaa, esim. korkeintaan 15 minuuttia yhtä user storya kohti. Jos tämä ei riitä, on todennäköistä, että storyn sisältöä, siihen sisältyviä oletuksia ja sen riippuvuutta muusta järjestelmästä ei tunneta vielä sillä tarkkuudella, että estimointi olisi mielekästä.
Voi myös olla, että vaikeasti estimoitava story muuttuu helpommaksi arvioida, jos se jaetaan useammaksi pienemmäksi ja rajatumman toiminnallisuuden kuvaamaksi storyksi.
User storyn estimointi ei ole kertaluontoinen toimenpide; estimaattia tarkennetaan projektin kuluessa sitä mukaa, kun kehittäjien näkemys eri asioiden toteuttamisperiaatteista alkaa selkiytyä.
Kuten äsken mainittiin, suhteellisessa estimoinnissa käytetty yksikkö story point ei useimmiten vastaa mitään aikamäärettä. Jotkut kuitenkin mitoittavat Story Pointin ainakin projektin alussa ideal working dayn eli työpäivän johon ei sisälly mitään häiriötekijöitä suuruiseksi. Eri tiimien käyttämät story point -yksiköt eivät kuitenkaan ole ollenkaan vertailukelpoisia keskenään.
Monet tahot suosittelevat olemaan sotkematta story pointeja tunteihin tai päiviin. Eräs argumenteista story pointin ja tarkkojen aikamääreiden sitomattomuuden puolesta on se, että jos tiimi määrittelisi story pointin olevan esimerkiksi 8 tuntia työtä, niin tiimin estimaatit saatettaisiin esim. yrityksen johdossa ajatella sitoumukseksi kunkin työvaiheen tarvitsemasta ajasta. Tämän taas ketterät menetelmät haluavat ehdottomasti välttää estimaattien perimmäisen epävarmuuden takia.
Estimoinnin menetelmiä
Eräs käyttökelpoinen tapa estimoinnille on kiinnittää muutama erikokoinen story referenssiksi ja verrata sitten muiden storyjen vaativuutta näihin:
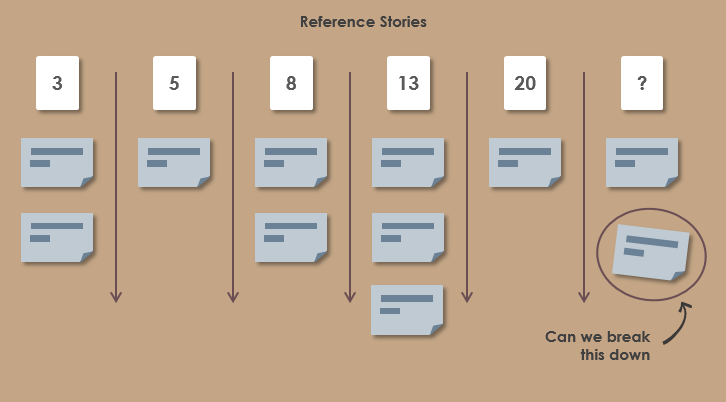
Koska estimointi on joka tapauksessa melko epätarkkaa, ei estimoinnissa ole tarkoituksenmukaista käyttää kovin tarkkaa skaalaa. Useimmiten käytetään yläpäästä harvenevaa skaalaa esim. 1, 2, 3, 5, 10, 20, 40, 100. Myös Fibonaccin lukujono 1, 2, 3, 5, 8, 13, 21, 34, 55 on suosiossa estimoinnin skaalana.
Motivaationa yläpäästä harvenevalle skaalalle on se, että koska isojen storyjen estimointiin liittyy erityisen suuri epävarmuus, ei kannata edes teeskennellä että skaala olisi isojen storyjen suhteen kovin tarkka.
Joskus estimoinnissa käytetään arvoa epic, jolla tarkoitetaan niin isoa tai huonosti ymmärrettyä user storyä, että sitä ei ole toistaiseksi mieltä estimoida. Itse asiassa alan ehkä suurin auktoriteetti Mike Cohn suosittelee käyttämään skaalaa 1, 2, 3, 5, 8 tai 1, 2, 4, 8 ja antamaan sitä suuremmille storyille estimaatti epic.
Jotta estimaatin epic saaneet storyt tulisivat estimoitua, ne tulee pilkkoa pienempiin, paremmin hallittaviin storyihin. Käsitteellä epic on eräs toinenkin merkitys user storyjen parissa, mihin palaamme hieman myöhemmin.
Hyvänä periaatteena pidetään että kaikki kehitystiimin jäsenet osallistuvat estimointiin. Näin tiimille syntyy yhtenäinen ymmärrys user storyn sisällöstä. Eräs suosittu tapa osallistaa koko tiimi estimointiin on planning poker.
Planning poker
Planning pokerissa käydään läpi backlogilla olevia user storyja yksi kerrallaan. Product owner esittelee user storyn sisällön ja selittää tarkemmin storyn luonnetta ja vaatimuksia.
Tiimi keskustelee storystä ja miettii kenties storyn jakautumista teknisiin työvaiheisiin. Kun kaikki kokevat olevansa valmiina arvioimaan, jokainen kertoo arvionsa (yksikkönä siis story point). Joskus tämä vaihe toteutetaan siten, että käytössä on pelikortteja, joilla on estimaattien arvoja, esim 1, 2, 5, 10, … ja kukin estimointiin osallistunut näyttää estimaattinsa yhtä aikaa.
Jos estimaatit ovat suunnilleen samaa tasoa, merkataan estimaatti user storylle ja siirrytään seuraavaan.
Jos ehdotetuissa estimaateissa on paljon eroavaisuuksia, keskustelee tiimi eroavaisuuksien syistä. Voi esimerkiksi olla, että osa tiimin jäsenistä ymmärtää user storyn vaatimukset aivan eri tavalla ja tämä aiheuttaa eroavaisuutta estimaatteihin.
Kun tiimi on keskustellut aikansa, tapahtuu uusi estimointikierros ja riittävä konsensus todennäköisesti saavutetaan pian.

Tiimin yhdessä tekemän estimoinnin sivutuotteena ymmärrys toteutettavana olevien user storyjen luonteesta leviää koko tiimin keskuuteen, ketterien menetelmien suuressa arvossa pitämä läpinäkyvyys (transparency) siis paranee estimoinnin sivutuotteena.
Hyvä product backlog on DEEP
Mike Cohn ja Roman Pichler ovat lanseeranneet lyhenteen DEEP kuvaamaan hyvän backlogin ominaisuuksia. Lyhenne tulee sanoista detailed appropriately, estimated, emergent ja prioritized.
Näistä ominaisuuksista estimated ja prioritized ovat meille tuttuja: storyillä on työmääräarviot ja storyt on priorisoitu eli asetettu tärkeysjärjestykseen.
Hyvä backlog on myös detailed appropriately eli sopivan yksityiskohtainen. Backlogin prioriteetiltaan korkeimpien eli lähiaikoina toteutettavaksi tulevien user storyjen tulee olla suhteellisen pieniä, niiden hyväksymiskriteerit tulee olla suunnilleen selvillä ja vaaditusta työmäärästä pitäisi olla kohtuullisen hyvä käsitys.
Alemman prioriteetin user storyt voivat vielä olla isompia ja karkeammin estimoituja. Itse asiassa alemman prioriteetin storyjä ei edes kannata määritellä kovin tarkasti, sillä kestää vielä kauan ennen kuin ne otetaan toteutettavaksi johonkin sprinttiin. Usein käy vieläpä niin, että alemman prioriteetin storyjä ei lopulta toteuteta koskaan, sillä niiden määrittelemä toiminnallisuus havaitaankin tarpeettomaksi. Alhaisen prioriteetin storyihin ei siis kannata investoida spekulatiivisesti liikaa aikaa.

Emergent kuvaa backlogin muuttuvaa luonnetta:
The product backlog has an organic quality. It evolves, and its contents change frequently. New items emerge based on customer and user feedback, and they are added to the product backlog. Existing items are modified, reprioritized, refined, or removed on an ongoing basis.
Backlog ei siis pysy muuttumattomana, vaan elää koko ajan. Uusia storyjä tulee, olemassa olevia storyjä tarkennetaan ja pilkotaan, tarpeettomia storyjä poistetaan. Työmääräarvioita ja prioriteetteja uudelleenmääritellään.
Tämä kaikki ei tietenkään tapahdu itsestään, backlogia tulee aktiivisesti hoitaa (engl. backlog grooming tai backlog refinement) projektin edetessä. Scrum guide mainitsee, että backlogin hienontamista tulee tapahtua läpi sprintin yhteistyössä product ownerin ja kehitystiimin kesken.
Product Backlog refinement is the act of breaking down and further defining Product Backlog items into smaller more precise items. This is an ongoing activity to add details, such as a description, order, and size.
Ideana on siis pitää backlog koko ajan DEEP-tilassa, joka taas helpottaa oleellisesti ennen jokaista uutta sprinttiä tehtävää sprintin suunnittelua. Jos backlog on huonossa kunnossa (prioriteetit miten sattuu, tärkeät storyt epämääräisessä tilassa, uusia tunnistettuja tarpeita vastaavia storyjä ei ole lisätty backlogille) sprintin suunnittelua tehtäessä, menee kaikkien aikaa hukkaan.
User story ja epiikki
Aiemmin mainittiin, että hyvä user story noudattaa INVEST-kriteeristöä, eli story on independent, negotiable, valuable, estimable, small, testable. Eräänä kriteerinä on siis storyn pienuus, user storyn tulee olla toteutettavissa yhdessä sprintissä. Backlogin DEEP-kriteeristö taas sanoo, että backlogin pitää olla sopivan yksityiskohtainen, erityisesti alhaisen prioriteetin storyja ei kannata tehdä liian tarkasti. INVEST-kriteeristö päteekin nimenomaan korkean prioriteetin storyihin, eli ennen kuin story voidaan ottaa toteutettavaksi, sen tulee olla tarpeeksi pieni, hyvin estimoitu ja testattavissa, eli storyn hyväksymiskriteerien tulee olla selkeitä.
Backlogin alaosissa olevat storyt voivat olla isoja, jopa sellaisia, että niitä ei missään nimessä lopulta pystytä edes toteuttamaan yhdessä sprintissä, vaan ne tulee ennen mahdollista toteuttamista jakaa pienempiin, rajatumpiin storyihin. Tämän kaltaisia isoja storyja nimitetään usein epiikeiksi (engl. epic).
Joissain yhteydessä sanotaan että user storyt ovat ready, jos ne noudattavat INVEST-kriteeristöä eli ovat valmiita sprinttiin otettavaksi.
User story on siis elinaikanaan todennäköisesti ensin epic. Kun aikaa kuluu, story ehkä pilkotaan ja joistain sen osista tulee ready kun niitä tarkennetaan prioriteetin noustessa. Kun story on valittu sprinttiin ja se toteutetaan, muuttuu sen tilaksi done. Kaikki backlogille lisättävät storyt eivät toki ole niin isoja että niiden voisi ajatella olevan kokoluokkaa epic, uusi story voi olla pienehkö mutta vaatimuksiltaan selkiytymätön, eli ei vielä ready.
Velositeetti
User storyjen estimoinnin toinen keskeinen motivaatio on, että se mahdollistaa koko projektin tai jonkin sen suuremman kokonaisuuden viemän aikamäärän summittaisen arvioinnin.
Kuten aiemmin mainittiin, yleinen ketterissä menetelmissä käytetty estimoinnin yksikkö on abstrakti käsite story point, joka ei suoranaisesti vastaa mitään aikamäärettä. Miten estimaattien avulla on tästä huolimatta mahdollista arvioida projektin viemää aikamäärää?
Kehitystiimin velositeetti (engl. velocity) tarjoaa tähän osittaisen ratkaisun. Velositeetilla tarkoitetaan sitä story pointtien määrää, minkä verran tiimi pystyy keskimäärin toteuttamaan yhden sprintin aikana.
Jos tiimin velositeetti on selvillä ja projektissa tai sen jossain kokonaisuudessa toteutettavaksi tarkoitetut user storyt ovat estimoituja, on helppo tehdä alustava arvio vaadittavasta aikamäärästä
(user storyjen estimaattien summa) / velositeetti * sprintin pituus
Projektin alkaessa velositeetti ei yleensä ole selvillä, ellei kyseessä ole jo aiemmin yhdessä työskennellyt tiimi. On kehitetty useita erilaisia tapoja, joiden avulla velositeetti voidaan yrittää ennustaa jo ennen projektin aloittamista. Nämä ovat kuitenkin hyvin epäluotettavia, ja emme käsittele niitä nyt. Projektin alkaessa arviot sen kestosta ovatkin erittäin epätarkkoja, lähinnä pelkkiä arvauksia.
Velositeetti vaihtelee tyypillisesti alussa melko paljon, erityisesti jos sovellusalue ja/tai käytetyt teknologiat eivät ole tiimille täysin tuttuja. Velositeetti kuitenkin alkaa yleensä stabiloitumaan muutaman sprintin jälkeen.
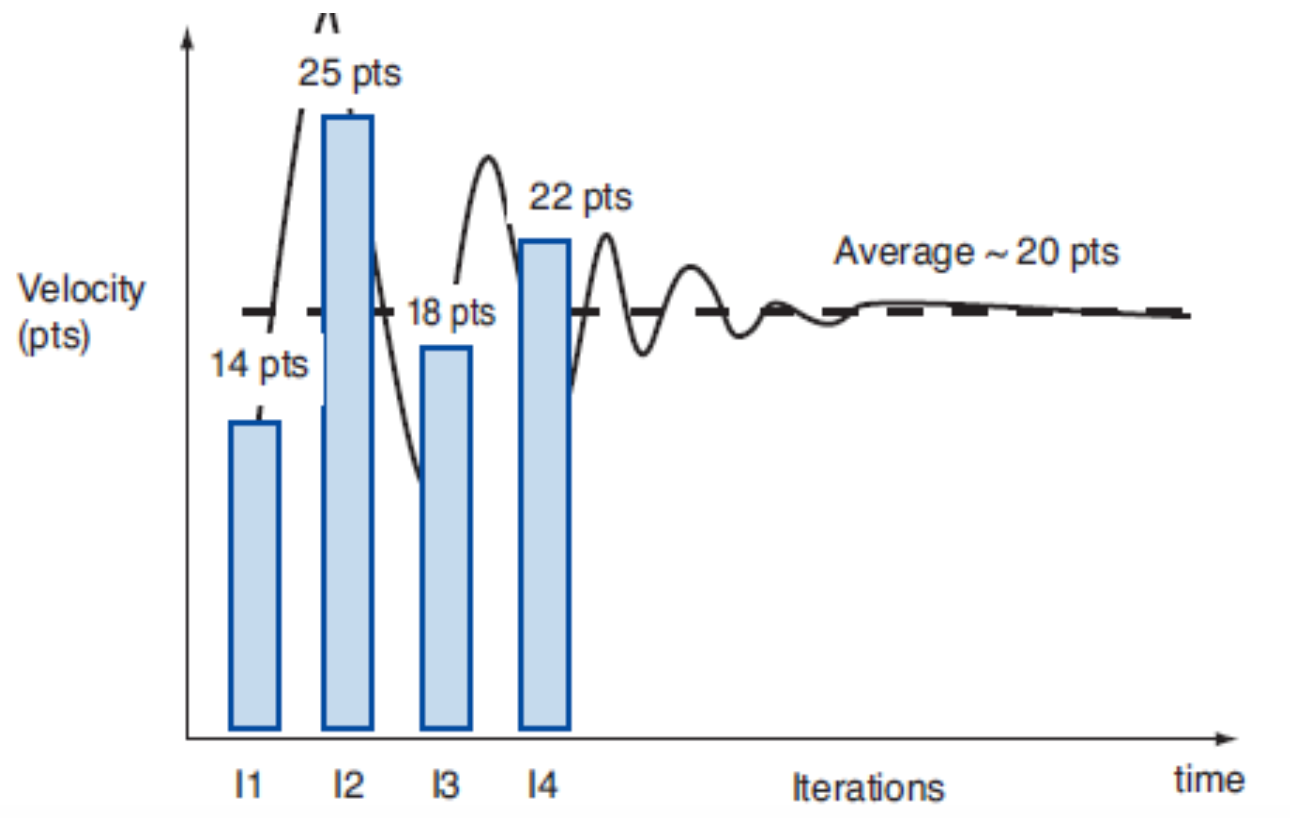
Tiimin velositeetti ja siihen perustuva projektin tai sen osakokonaisuuden keston arvio alkaa tarkentumaan pikkuhiljaa.
Ketterissä menetelmissä on olennaista kuvata mahdollisimman realistisesti projektin etenemistä. Tämän takia velositeettiin lasketaan mukaan ainoastaan täysin valmiiksi (eli definition of donen määrittelemällä laatutasolla) toteutettujen user storyjen story pointit. “Lähes valmiiksi” tehtyä työtä ei siis katsota ollenkaan tehdyksi työksi.
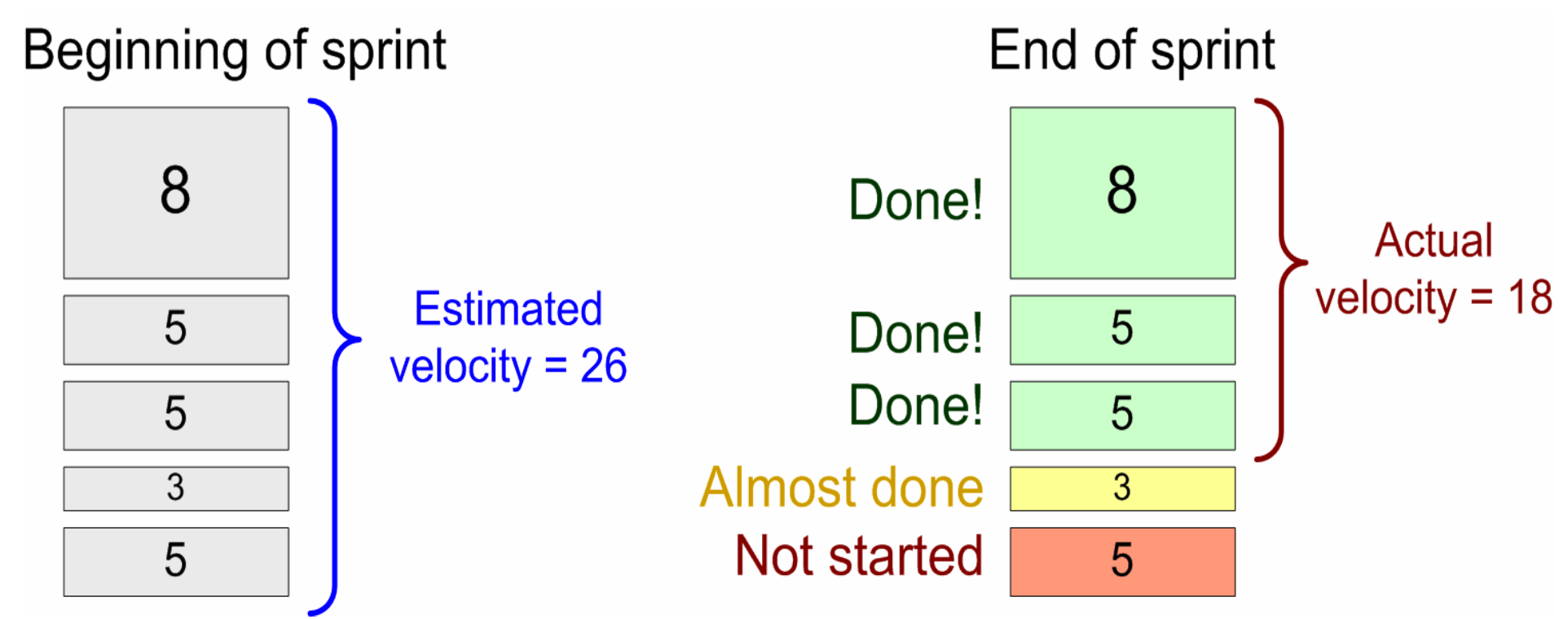
Eri tiimien velositeettien vertailu
Kuten aiemmin mainittiin, story point ei vastaa mitään aikaan sidottua työmäärää. Kukin tiimi määrittelee itse sen mitä story point tiimille tarkoittaa. Usein määritelmä perustuu jonkin tietyn user storyn oletettuun työmäärään. Tiimi voi esimerkiksi määritellä, että storyn käyttäjä lisää tuotteen ostoskoriin koko on yksi story point. Tämän takia taas eri kehitystiimien velositeetit eivät ole ollenkaan vertailukelpoisia, poikkeuksena tilanteet, joissa tiimit työskentelevät yhteisen backlogin parissa ja hoitavat estimoinnin yhdessä.
Burndown- ja burnup-kaaviot
Ketterän projektin etenemistä kuvataan joskus release burndown -kaavion avulla. Aika etenee kaavion x-akselilla sprintti kerrallaan, y-akselilla on jäljellä olevan työn määrä story pointteina mitattuna:
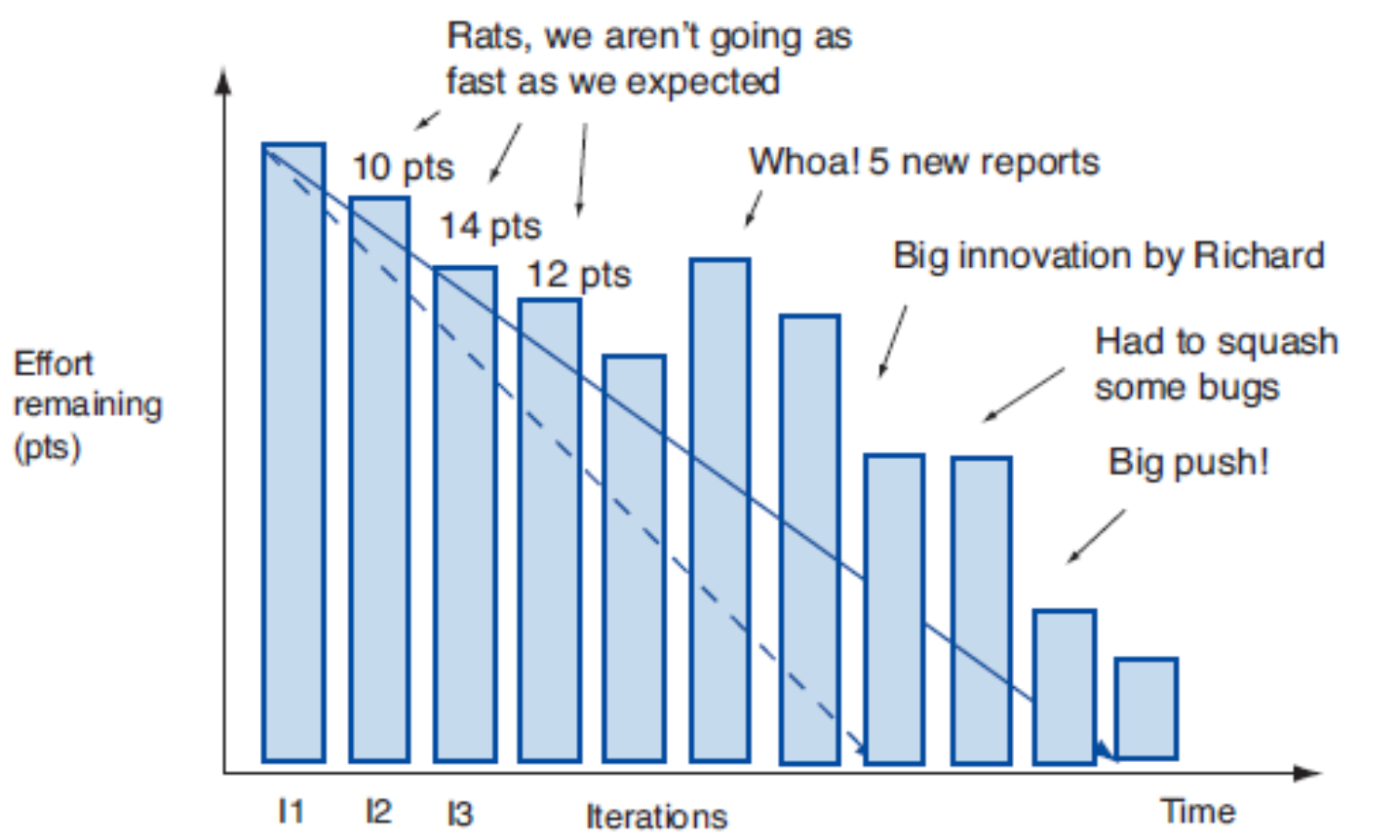
Ketterässä projektissa vaatimukset saattavat muuttua kehitystyön aikana, siksi jäljellä olevan työn määrä ei aina vähene. Joskus käytetäänkin burn up -kaavioita, joka tuo selkeämmin esiin kesken projektin etenemisen tapahtuvan työmäärän kasvun:
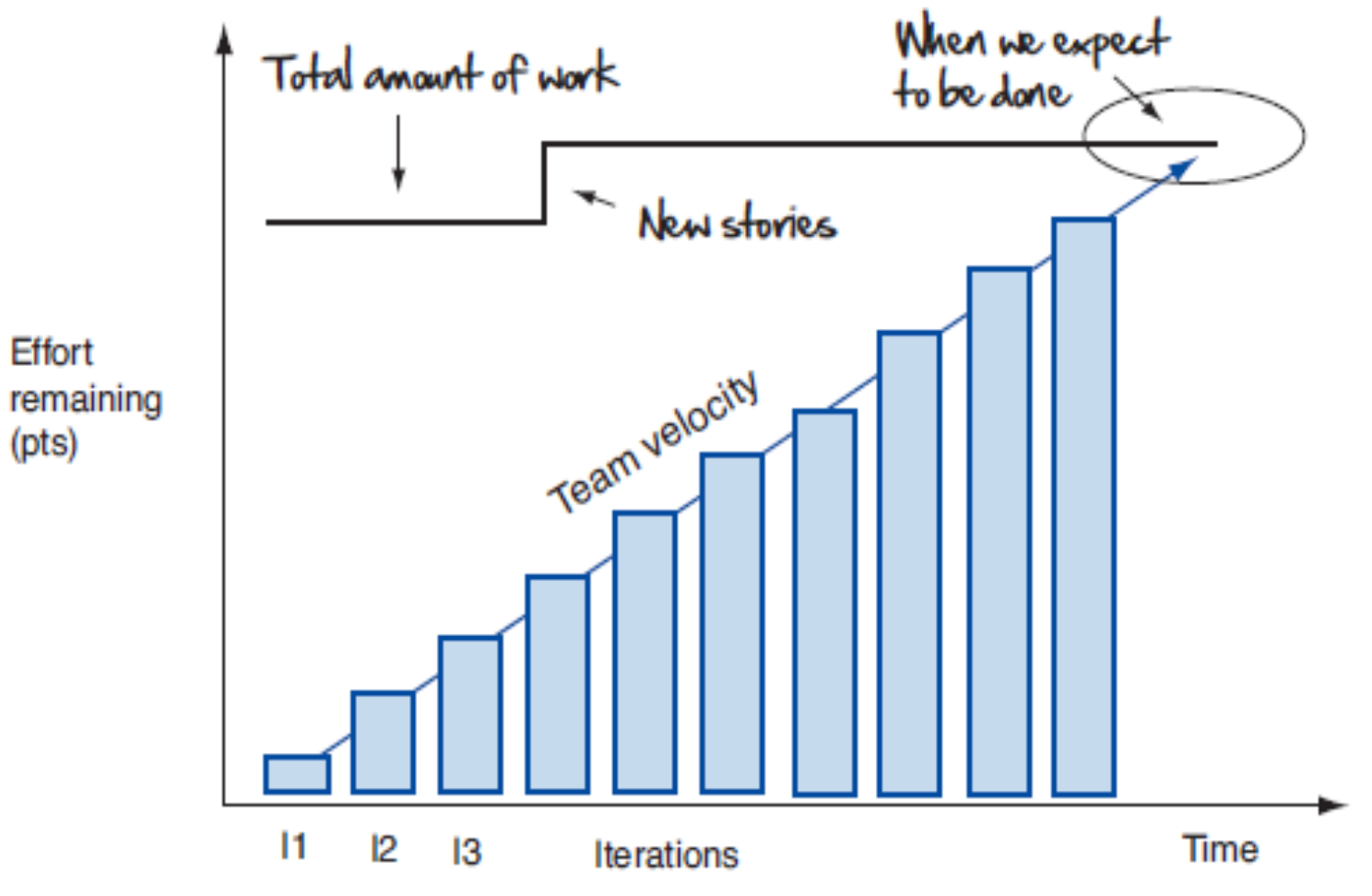
Julkaisun suunnittelu ja tuotteen roadmap
Product backlog siis listaa järjestelmän vaatimuksia kuvaavat user storyt prioriteettijärjestyksessä. Prioriteetin määrittelee useimmiten storyjen asiakkaalle tuova arvo. Kehitystiimi toteuttaa storyja sprintti kerrallaan, valiten kuhunkin sprinttiin joukon sillä hetkellä korkeimman prioriteetin omaavia storyjä.
Ohjelmistoja kehitettäessä tarvitaan usein pelkkää backlogia ja yksittäisiä sprinttejä korkeammalla tasolla olevaa näkymää projektin aikataulutukseen ja kehitystyön suuntaamiseen. Syitä tälle on monia. Sovelluksilla saattaa esimerkiksi olla erilaisia deadlineja, joihin mennessä tiettyjen ominaisuuksien on pakko olla valmiina. Joissain tilanteissa taas sovelluksen versioita halutaan julkaista tasaisin väliajoin, esimerkiksi 4 kuukauden välein.
Tällaistä yksittäisiä sprinttejä pidemmän aikavälin suunnittelun tekemistä nimitetään usein julkaisun suunnitteluksi (engl. release planning). Julkaisun suunnittelussa mietitään yleensä user storyjä yleisemmällä tasolla, mitä isompia toiminnallisia kokonaisuuksia kuhunkin julkaisuun tai etappiin (engl. milestone) halutaan mukaan. Etapit eli milestonet taas koostuvat tyypillisesti useammasta sprintistä.
Voidaankin ajatella, että julkaisun suunnittelussa backlogin sisältö jaetaan karkeasti isompiin lohkoihin, joihin sijoitetaan ne user storyt, joiden ajatellaan suunnitteluhetkellä sisältyvän kyseiseen milestoneen:

Eri milestonet saattavat olla ajallisesti saman pituisia, eli ne voivat koostua vakiomäärästä sprinttejä. Kaikissa tilanteissa tämäkään ole tarkoituksenmukaista, ja voi olla mielekästä että milestonejen pituus vaihtelee.
Kullakin milestonella voi olla oma korkeamman tason tavoitteensa, esim.:
- milestone/release 1: verkkokaupan perustoiminnallisuus
- milestone/release 2: tuotteiden arvostelu ja arvosteluihin perustuva suosittelu
- milestone/release 3: käyttäjien ostoshistoriaan liittyvä tuotteiden suosittelu
Näin ohjelmiston isojen linjojen suunniteltu eteneminen on huomattavasti helpompi kommunikoida ohjelmiston sidosryhmille kuin jos verrataan pelkän product backlogin käyttämistä kommunikaation välineenä.
Ketterän hengen mukaan milestonejen sisältö voi kuitenkin elää, ja mitä kauempana olevasta tulevaisuudesta on kyse, sitä spekulatiivisempi julkaisusuunnitelman sisältö on. Julkaisusuunnitelmaa nimitetään usein myös tuotteen roadmapiksi.
User story mapping
Product backlogin hienoisena hankaluutena on, että sovelluksen kehityksen suuret linjat eivät tule siitä kunnolla esille. User story mapping on viime aikoina huomiota saanut tekniikka, joka tarjoaa product backlogin “yksiulotteista” näkymää paremman työkalun sovelluksen julkaisun suunnitteluun.
Tekniikka jakaa user storyt sovelluksen eri toiminnallisten kokonaisuuksien alle omiksi sarakkeikseen tärkeysjärjestykseen. Seuraavassa esimerkkinä verkkokaupan story map, joka jaottelee user storyt sen mukaan liittyvätkö ne tuotteiden etsimiseen (product search), yksittäisen tuotteen näkymään (product page) vai ostoksen tekemiseen (checkout):
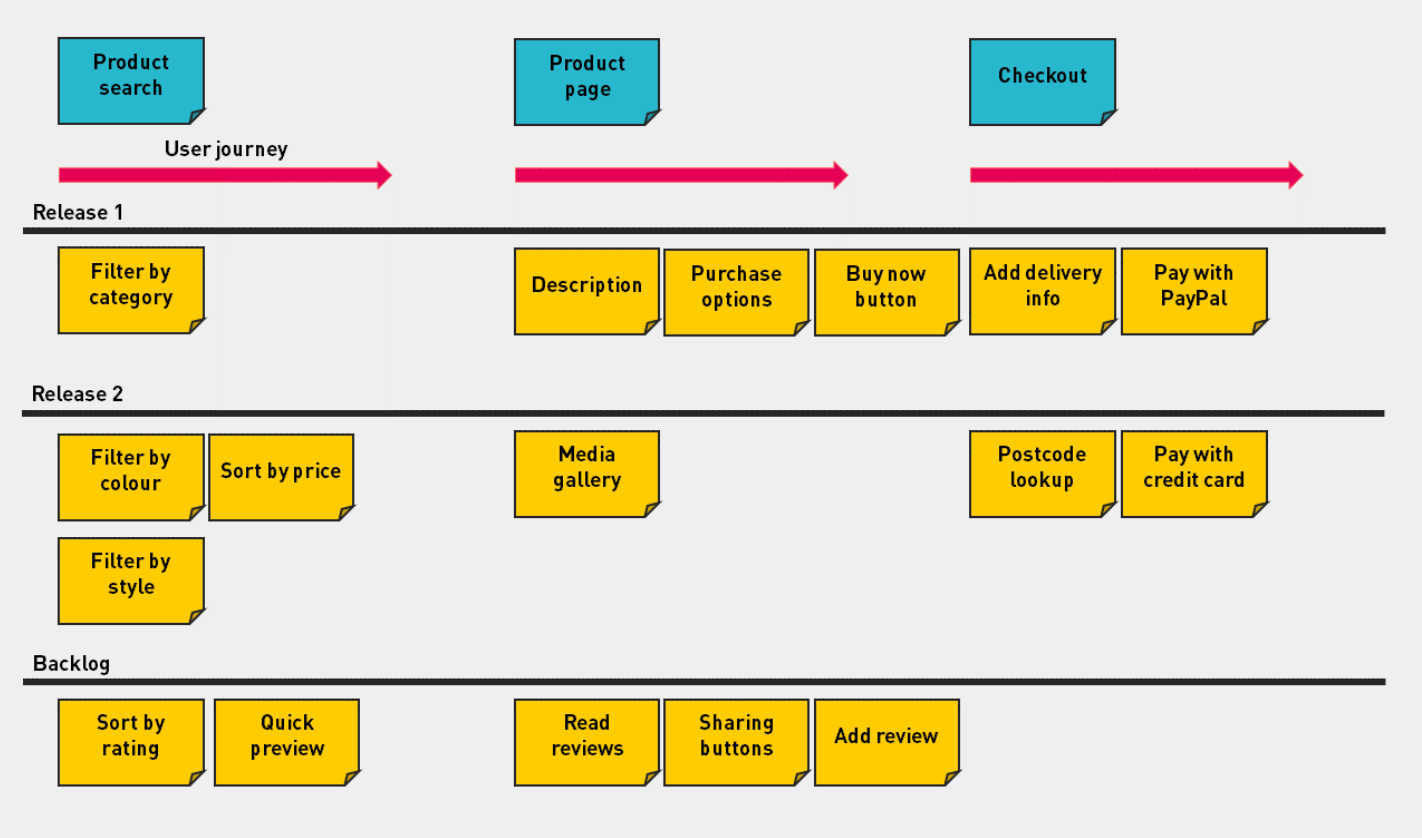
Story mapin rivit ovat loogisia kokonaisuuksia, joista kustakin muodostuu sovellukseen oma milestone tai vaikkapa yhdessä sprintissä kehitettävä mielekäs kokonaisuus.
Kannattaako estimointi?
User storyjen viemän työmäärän arvioimiseen on siis kaksi motivaatiota:
- auttaa asiakasta priorisoinnissa
- mahdollistaa koko projektin tai tiettyjä milestonejen viemän ajan ja täten myös kustannuksen arviointi
Story point -perustainen suhteellinen estimointi on saavuttanut vankan aseman ketterän ohjelmistokehityksen kaanonissa. Scrum guide mainitsee että backlogilla olevat vaatimukset ovat estimoituja, samoin kuten monet parhaat käytänteet kuten DEEP.
Viimeisen vuosikymmenen aikana on syntynyt #NoEstimates-liike, joka on ruvennut kyseenalaistamaan story point -perustaista estimointitapaa ja pitää siitä saavutettuja hyötyjä liian vähäisinä verrattuna estimointiin käytettyyn aikaan ja vaivaan. #NoEstimates-liike ei missään tapauksessa kiistä etteikö työmääräarvioista olisi hyötyä, tarkoituksena onkin saada ihmiset ajattelemaan, missä tilanteissa estimointi on järkevää sekä nostaa esiin vaihtoehtoisia tapoja estimoinnin suorittamiseen.
Eräs jo vuosia käytetty menetelmä on arvioida kehitystiimin velositeetti laskemalla kussakin sprintissä valmistuneiden user storyjen lukumäärä sen sijaan, että käytetään story point -perustaista estimointia. Monien kokemuksen mukaan menetelmä toimii varsin hyvin, erityisesti jos storyt ovat riittävän tasakokoisia.
Sprintin suunnittelu
Kertauksena viime viikolta, Scrum määrittelee pidettäväksi ennen jokaista sprinttiä suunnittelupalaverin. Palaverin primäärisenä tavoitteena on selvittää, mitä user storyjä sprintiin valitaan toteutettavaksi.
Sprintin suunnittelun lähtökohtana on sopivassa tilassa oleva, eli DEEP product backlog. Backlog on siis priorisoitu, estimoitu, ja korkeimman prioriteetin omaavat user storyt tarpeeksi pieniä sekä product ownerin hyvin ymmärtämiä.
Sprintin suunnittelussa product owner varmistaa, että kehitystiimi ymmärtää hyvin product backlogin kärkipäässä olevat user storyt. Tiimi valitsee tehtäväksi niin monta backlogin storyistä kuin se arvioi kykenevänsä sprintin aikana toteuttamaan definition of donen määrittelemällä laatutasolla.
Sprintin tavoite
Scrum guide kehottaa että suunnittelun yhteydessä määritellään sprintin tavoite (engl. sprint goal), jolla tarkoitetaan lyhyttä, yhden tai kahden lauseen kuvausta siitä, mitä tiimi on aikeissa sprintin aikana tehdä.
Scrumin kehittäjä Ken Schwaber mainitsee 2002 kirjoitetussa kirjassaan asettavansa usein ensimmäisen sprintin tavoitteeksi: demonstrate a key piece of user functionality on the selected technology.
Esimerkiksi verkkokauppaa kehitettäessä seuraavien sprinttien tavoitteita voisivat olla:
- Ostoskorin perustoiminnallisuus: tuotteiden lisäys ja poisto
- Ostosten maksaminen ja toimitustavan valinta
Sprintin tavoite toimii tiimin ulkopuoliselle nopeana kuvauksena siitä, mitä tiimi on kuluvan sprintin aikana tekemässä. Vaikka sama asia periaatteessa selviää myös katsomalla, mitkä user storyt ovat tiimillä työn alla, on geneerisemmässä muodossa oleva lyhyempi kuvaus parempi monille ohjelmiston sidosryhmille, kuten firman johdolle, joita ei kiinnosta seurata tapahtumia yksittäisten storyjen tarkkuudella.
Sprintin onnistumista tarkastellaan yleensä suhteessa sprintin tavoitteeseen, eli vaikka sprintissä jäisikin yksittäisiä user storyjä toteuttamatta, voidaan sprintti todeta onnistuneeksi jos toteutettu toiminnallisuus kattaa sprintin tavoitteiden oleelliset osat.
Sprintissä toteutettavien user storyjen valinta
Kehitystiimi siis päättää kuinka monta user storyä sprinttiin otetaan toteutettavaksi. Pääperiaate on valita “sopiva määrä” backlogin korkeimmalle priorisoituja user storyjä ja siirtää ne sprint backlogiin.
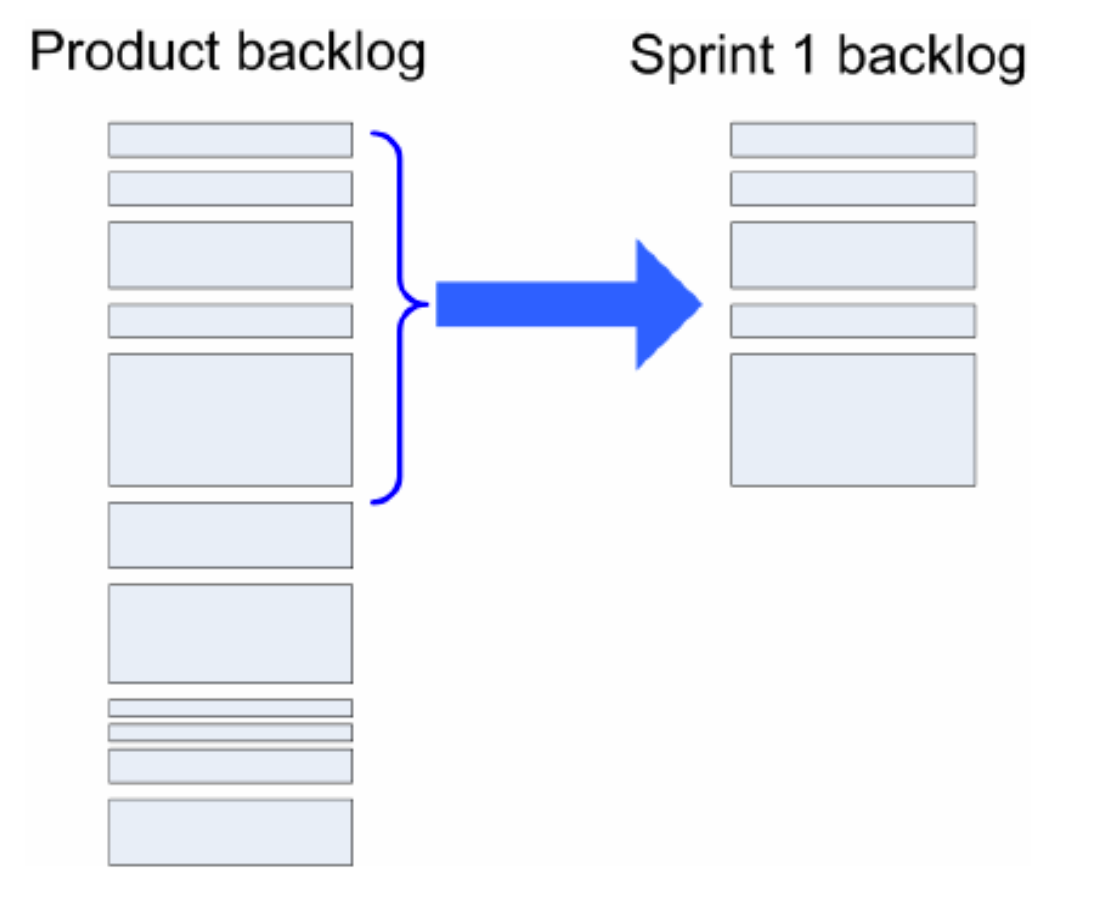
Tapoja päättää sprinttiin otettavien storyjen määrä on useita:
- jos storyt ovat estimoituja ja tiimin velositeetti tunnetaan, otetaan sprinttiin velositeetin verran storyjä
- jos estimaatteja ei ole ja/tai velositeettiä ei tunneta, otetaan niin monta korkeimman prioriteetin storyä, kuin mihin kaikki tiimiläiset tuntevat voivansa sitoutua
- edellisten yhdistelmä, eli vaikka velositeetti ja estimaatit olisivat tiedossa, niin käytetään myös harkintaa sen suhteen, onko velositeetin avulla valittu määrä tiimiläisistä sopivan tuntuinen
Käytetään mitä valintaperiaatetta tahansa, on joka tapauksessa oleellista että toteutettavaksi valitaan vain sellainen määrä storyjä, jotka tiimi kokee voivansa toteuttaa kunnolla, eli definition of donen määrittelemällä laatutasolla.
Product ownerin vaikutusmahdollisuudet sprintin storyihin
Oletusarvoisesti sprinttiin siis otetaan joukko backlogin kärjessä olevia user storyjä:
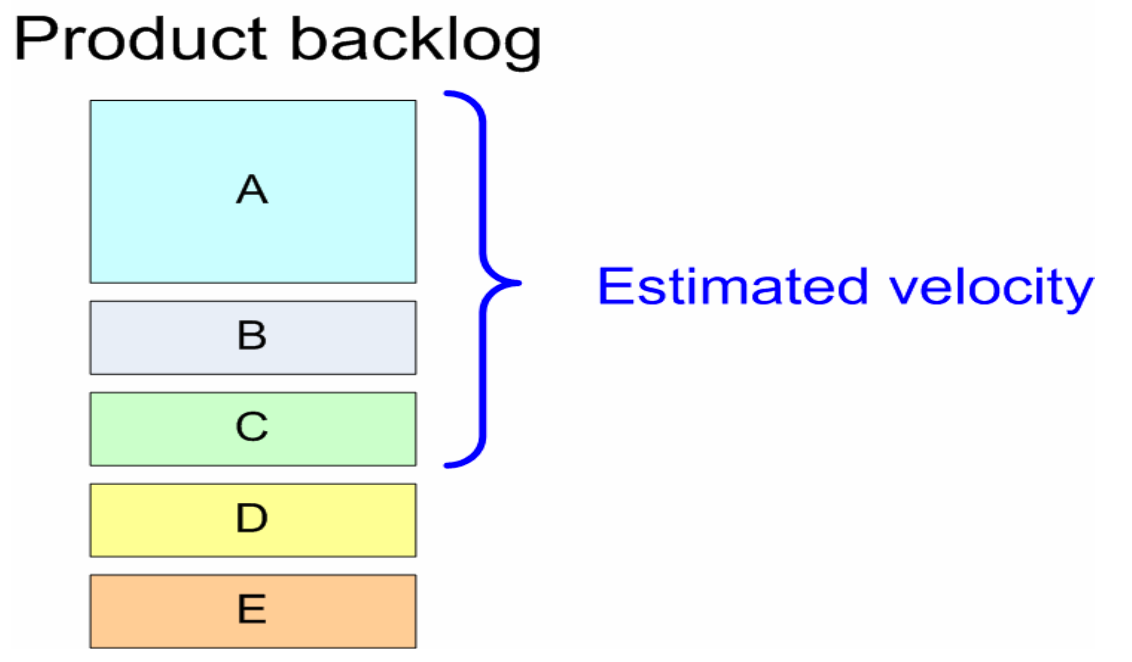
Product ownerilla on kuitenkin mahdollisuuksia vaikuttaa sprinttiin mukaan otettaviin storyihin tekemällä uudelleenpriorisointia.
Entä jos product owner haluaa storyn D mukaan sprinttiin? Product owner nostaa D:n prioriteettia, C tippuu pois sprinttiin valittavien user storyjen joukosta:
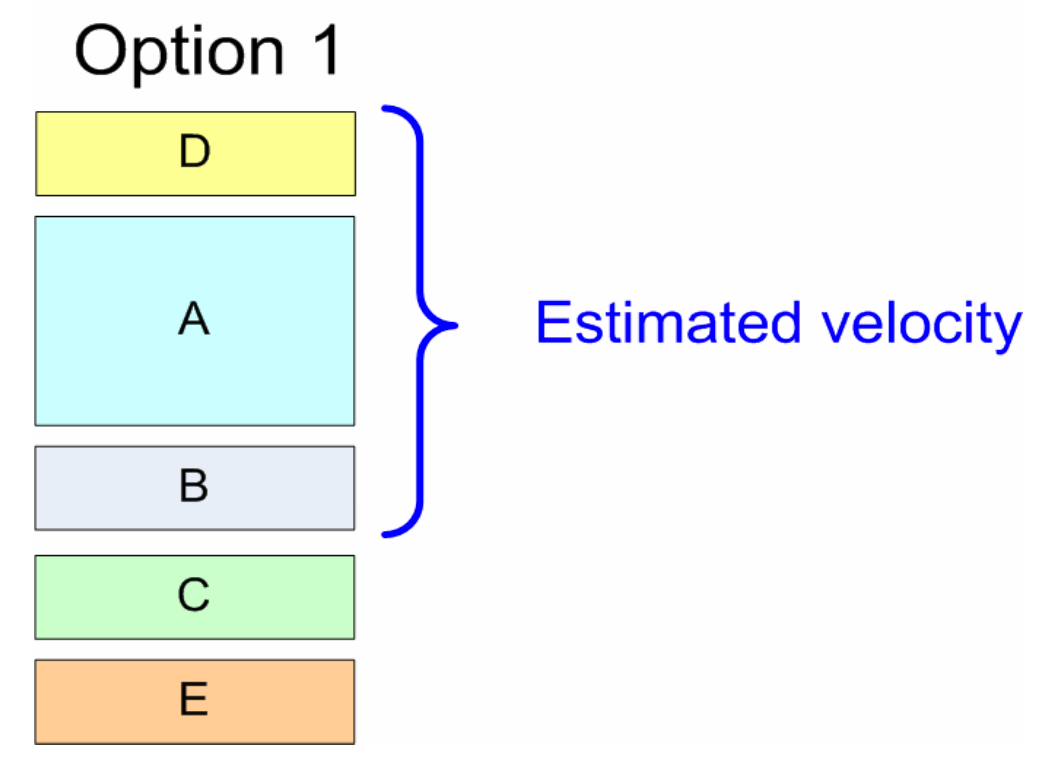
Entä jos product owner haluaa sprinttiin mukaan kaikki user storyt A-D? Jostain on luovuttava: product owner pienentää user storyn A määrittelemää toiminnallisuutta, kehitystiimi estimoi pienennetyn A:n ja nyt A-D mahtuvat sprinttiin:
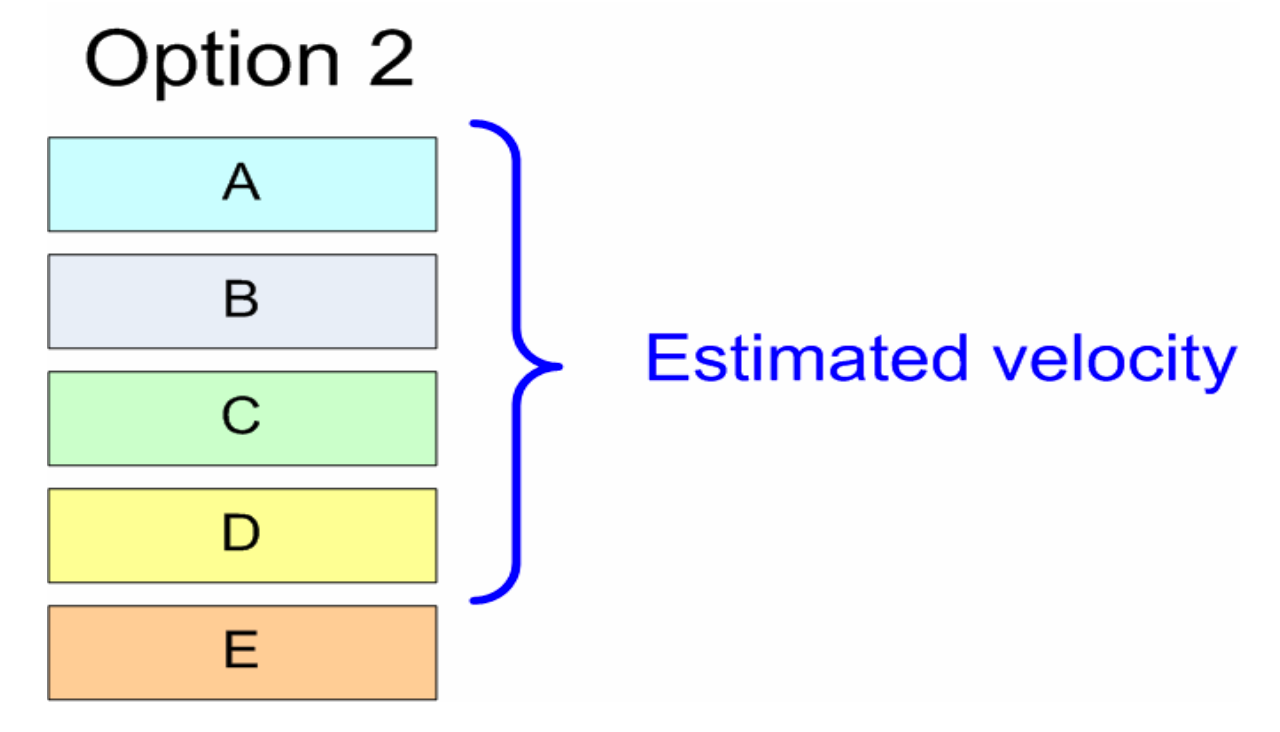
Entä jos A:n toiminnallisuutta ei saa karsia ja product owner silti haluaa A-D:n mukaan sprinttiin? Ratkaisu tähän on jakaa user story A kahteen pienempään osaan A1:n ja A2:n. A1 sisältää A:n tärkeimmät piirteet ja otetaan mukaan sprinttiin, A2 saa alemman prioriteetin, ja jää sprintin ulkopuolelle:
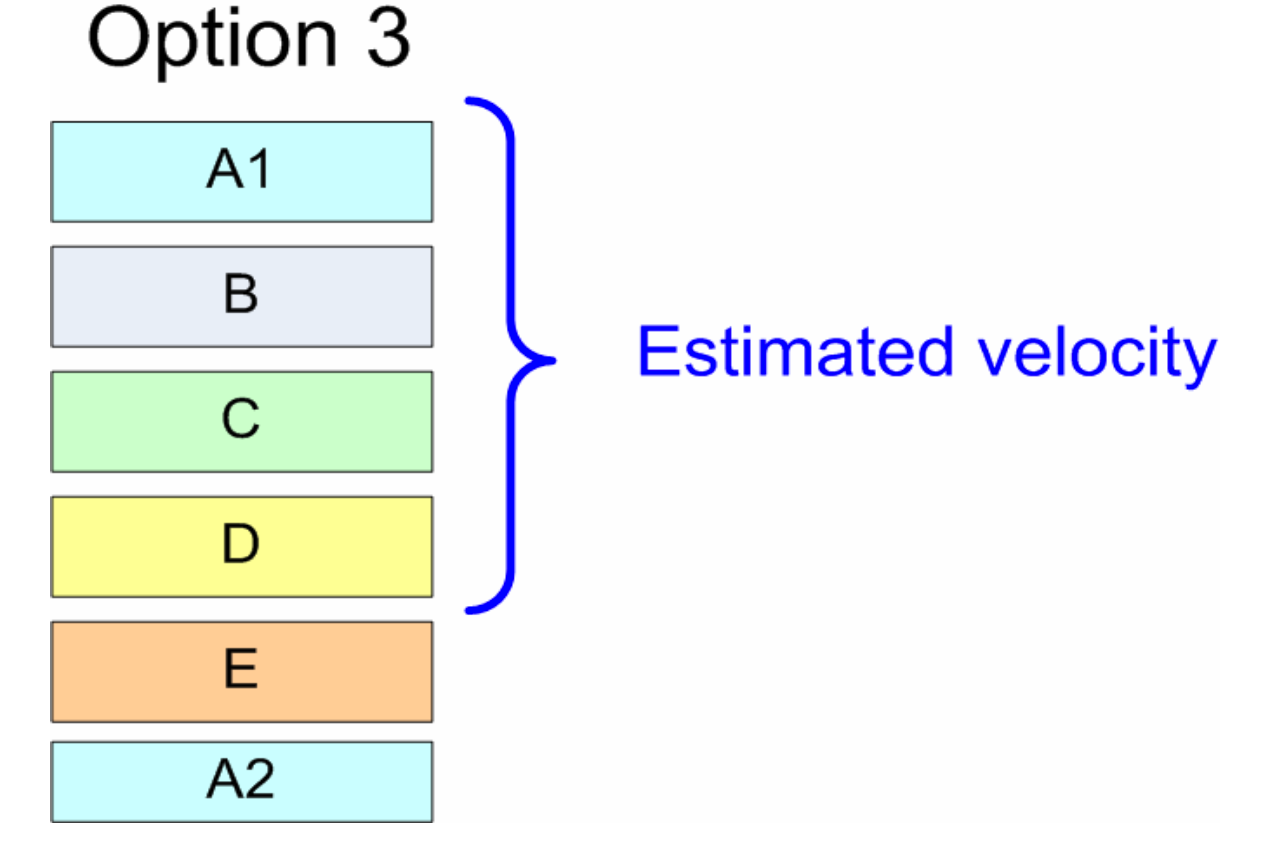
User storyjen jakaminen
User storyjen jakaminen pienemmiksi ei ole aloittelijalle, eikä aina ammattilaisellekaan helppoa.
Jo aiemmin mainittu INVEST-periaate antaa kuusi kriteeriä hyvälle, toteutettavaksi sopivalle user storylle, ja nämä kriteerit kannattaa pitää myös jakaessa storyjä pienemmiksi. Eräs melko ilmeinen tapa olisi jakaa storyjä ohjelmiston arkkitehtuurikerrosten mukaan, eli esim. lisää tuote ostoskoriin jaettaisiin seuraaviin storyihin:
- selaimessa toimivaan käyttöliittymään nappi ostoksen lisäämiseksi
- palvelimella olevaan sovelluslogiikkaan mekanismi ostoskorin päivittämiselle
- tietokantaan taulu ostoskorin esittämiseen
Tällainen jako ei kuitenkaan ole hyvä. Näin jaetut storyt eivät ole asiakkaalle arvoa tuottavia (valuable) eivätkä toisistaan riippumattomia (independent), eli jos storyista toteutettaisiin vaikkapa ensimmäinen ja toinen, oltaisiin vielä riippuvaisia kolmannesta storysta ennen kuin toiminnallisuus olisi mielekäs.
Seuraavassa muutamia erilaisia tapoja storyjen jakamiseen Richard Lawrencen inspiroimana.
Pattern 1: business rule variations
Story, joka sisältää monenlaisia kompleksisia ehtoja (business rule), esim.
As a user, I can search for flights with flexible dates.
kannattaa jakaa siten että jokainen näistä ehdoista eritellään omaksi storykseen:
- … as “between dates x and y”
- … as “a weekend in December”
- … as “± n days of dates x and y”
Pattern 2: simple/complex
Hieman samanlainen kuin edellinen tapa, on jakaa monimutkainen user story siten, että siitä erotetaan yksinkertainen, mutta jo itsessään hyödyllinen story, eräänlainen “minimal viable product”, ja muodostetaan joukko storyja, jotka lisäävät sen määrittelemää perustoiminnallisuutta.
Esimerkiksi joustavaa lentojen hakua kuvaava story
As a user, I can search for flights between two destinations
voidaan jakaa seuraavasti
- … when only direct flights used
- … specifying a max number of stops
- … including nearby airports
- … using flexible dates
Pattern 3: major effort
Joskus hyvä jakoperuste on toteuttaa story toimimaan ensin yhden esimerkkitapauksen kanssa ja yleistää se omana storynaan. Esimerkiksi luottokorttimaksamista koskeva story
As a user, I can pay for my flight with VISA, MasterCard, Diners Club, or American Express.
voitaisiin jakaa kahtia, missä ensimmäisessä storyssa vasta hoidettaisiin yksi luottokorttityyppi, ja seuraava story yleistäisi toiminnan kaikkiin kortteihin:
- … I can pay with VISA
- … I can pay with all four credit card types (VISA, MC, DC, AMEX) (given one card type already implemented)
Pattern 4: data entry methods
Hyvä tapa storyjen jakoon on myöskin muodostaa ensin versio, jossa on yksinkertainen käyttöliittymä ja laajentaa sitä omana storynaan. User story
As a user, I can search for flights between two destinations
jakaantuukin helposti kahteen esim. seuraavasti
- … using simple date input
- … with a fancy calendar UI
Pattern 5: Defer Performance
Joissain tapauksissa vastaava jako voidaan tehdä suorituskyvyn suhteen, eli aluksi tehdään perusversio ja laajentava story optimoi suorituskykyä. User story
As a user, I can search for flights between two destinations
siis jakaantuu kahtia seuraavasti:
- … slow—just get it done, show a “searching” animation
- … in under 5 seconds
Pattern 6: Operations
Eräs yleisimpiä tapoja jakamiseen on eritellä storyyn sisältyvät toiminnot omiksi storyikseen.
Käyttäjän hallinnointia kuvaava story
As a user, I can manage my account
jakaantuu mukavasti moneen osaan
- … I can sign up for an account
- … I can edit my account settings
- … I can cancel my account
Pattern 7: Break Out a Spike
On monia tilanteita, joissa storyn kokoa on todella vaikeaa arvioida etukäteen. Story voi joko olla vaatimuksiltaan epäselvä, eli ei oikein tiedetä vielä mitä halutaan, tai story saattaa sisältää jonkin toteutusteknisesti riskialttiin osan. Joskus storyn sisältämä epävarmuus ei poistu mitenkään muuten kuin tekemällä kokeellinen toteutus, jonka avulla tutkitaan teknisiä riskejä tai selvitellään käyttäjän tahtotilaa.
Tällaisestä eksperimentaalisesta toteutuksesta käytetään nimitystä spike solution, ja useimmiten sellaisen toteuttamiseen annetaan jokin rajattu määrä aikaa, esim. 2 päivää.
Jos tiimi ei ole toteuttanut koskaan luottokorttimaksuun liittyvää toiminnallisuutta, user storysta
As a user, I can pay by credit card
kannattaa eriyttää aikarajattu eksperimentti joka suoritetaan aiemmassa sprintissä. Tämän jälkeen toivon mukaan varsinaisen toiminnallisuuden toteuttava story osataan estimoida paremmin:
- Investigate credit card processing
- Implement credit card processing
Aiemmin tässä osassa puhuimme Lean-startup-menetelmästä, jossa uusien ideoiden toimivuutta kokeillaan A/B-testauksella, eli ideasta toteutetaan minimal viable product (MVP) eli minimalistinen versio, joka annetaan käyttöön osalle järjestelmän käyttäjistä. Jos uusi idea vaikuttaa toimivalta, toteutetaan se kunnolla ja korvataan sillä alkuperäinen toiminnallisuus. A/B-testaus onkin idealtaan hyvin samankaltainen kuin spike-solution, eli A/B-testissä rakennettavan MVP-version avulla selvitetään jonkin idean toimivuus ja vasta sen jälkeen toteutetaan toiminnallisuus kokonaisessa laajuudessaan.
User storyjen jakamisesta on monia etuja. Storyjä jaettaessa huomataan usein, että alkuperäinen iso story eli epiikki, kuvaa itse asiassa paljon laajemman toiminnallisuuden kuin mille on tarvetta, eli sovelluksesta saadaan storyjen jakamisen avulla mahdollisesti karsittua pois paljon turhaa toiminnallisuutta. Storyjen pienuus kasvattaa myös ohjelmistokehityksen ennustettavuutta. Mitä pienempiä storyt ovat, sitä helpompi ne on estimoida ja sitä varmemmin ne saadaan toteutettua yhden sprintin aikana, ja näin tiimin velositeetista tulee paremmin ennustettava.
Sprintin tekninen suunnittelu
Sprintin suunnittelun yhteydessä sprinttiin valituille user storyille tehdään yleensä myös riittävä määrä teknistä suunnittelua, eli hahmotellaan, miten storyt saadaan toteutettua. Suunnitellaan komponentteja ja rajapintoja karkealla tasolla sekä huomioidaan user storyjen aiheuttamat muutokset olemassa olevaan osaan sovelluksesta.
Suunnittelun yhteydessä on usein tapana pilkkoa kukin user story teknisen tason tehtäviksi (engl. task) jotka on toteutettava, jotta user story saadaan valmiiksi.
Esimerkiksi story tuotteen lisääminen ostoskoriin voitaisiin pilkkoa seuraaviin teknisen tason taskeihin:
- tarvitaan sessio, joka muistaa asiakkaan
- oliot ja tietorakenteet ostoskorin ja ostoksen esittämiseen
- laajennus tietokantaskeemaan
- html-näkymää päivitettävä tarvittavilla painikkeilla
- kontrolleri painikkeiden käsittelyyn
- yksikkötestit kontrollerille ja ostoskorin logiikalle
- hyväksymistestien automatisointi
Sprint backlog
Sprintin tehtävälista eli sprint backlog koostuu sprintiin valituista user storyista sekä niihin liittyvistä teknisen tason tehtävistä eli taskeista. Sprint backlog on ensisijaisesti kehitystiimin työväline ja tiimi päättää scrum masterin avustuksella sen miten se organisoi sprint backlogin.
Sprint backlog organisoidaan usein taulukkomaiseksi taskboardiksi, jossa on yksi rivi kutakin sprinttiin valittua user storya kohti. Storyyn liittyvät taskit kulkevat vasemmalta oikealle niiden statusta kuvaavien sarakkeiden not started, in progress, done kautta:
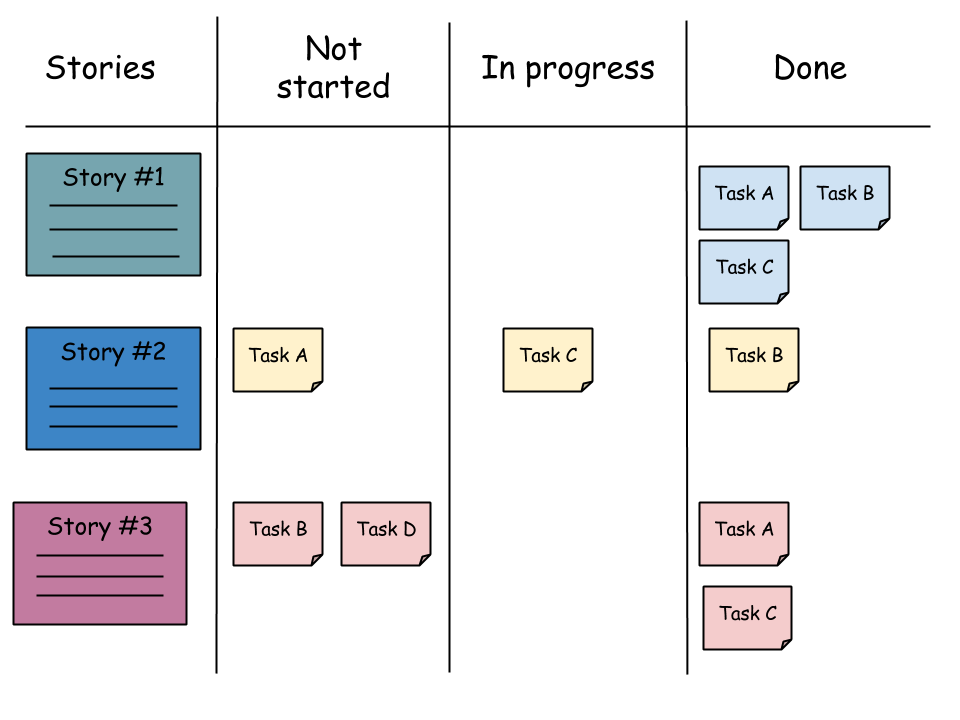
Kaikkia storyyn liittyviä taskeja ei sprintin suunnittelun aikana yleensä löydetä ja uusia taskeja lisätään tarvittaessa sprintin edetessä.
Samassa tilassa työskentelevien tiimien paras käytäntö on käyttää fyysisiä taskboardeja, user storyt ovat esimerkiksi pahvikortteja ja taskit kirjoitetaan post it -lapuille.

Esimerkin taskboardissa on edellisestä poiketen myös sarake blocked, joka kuvaa niitä taskeja, joiden toteuttaminen on syystä tai toisesta keskeytynyt jonkin esteen takia. Task board voikin sisältää mitä tahansa sarakkeita. Scrum ei anna mitään ohjeistoa sprint backlogin muodostamiseen, pääasia onkin että tiimi muokkaa taskboardinsa omia tavoitteitaan tukevaksi. On myös melko tyypillistä että tiimi muokkaa taskboardia projektin kuluessa huomatessaan että olemassa olevan taskboardin rakenne ei ole enää optimaalinen tiimin työskentelylle.
Sprintin työmääräarviot ja burndown
Scrum guiden ennen vuotta 2020 julkaistujen versioiden mukaan tiimin tulee seurata sprintin aikana kuinka paljon sprintissä on vielä töitä jäljellä. Eräs tapa toteuttaa sprintinaikainen työmäärän seuranta on estimoida sprintissä olevien taskien työmäärää. Useiden asiantuntijoiden mukaan sprinttiin kuuluvat taskit tulisi estimoida niiden edellyttämän työtuntimäärän mukaan, toisin kuin user storyt, jotka estimoidaan abstraktin aikamääreen eli story pointin tarkkuudella.
Taskien estimaatit tulee pitää ajan tasalla, eli jokaisen taskin jäljellä olevan työn määrä arvioidaan esim. päivittäisessä scrum-palaverissa eli daily scrumeissa.
Jäljellä olevan työn määrä (tunteina mitattuna) voidaan visualisoida sprintin etenemistä kuvaavalla burndown-käyrällä:
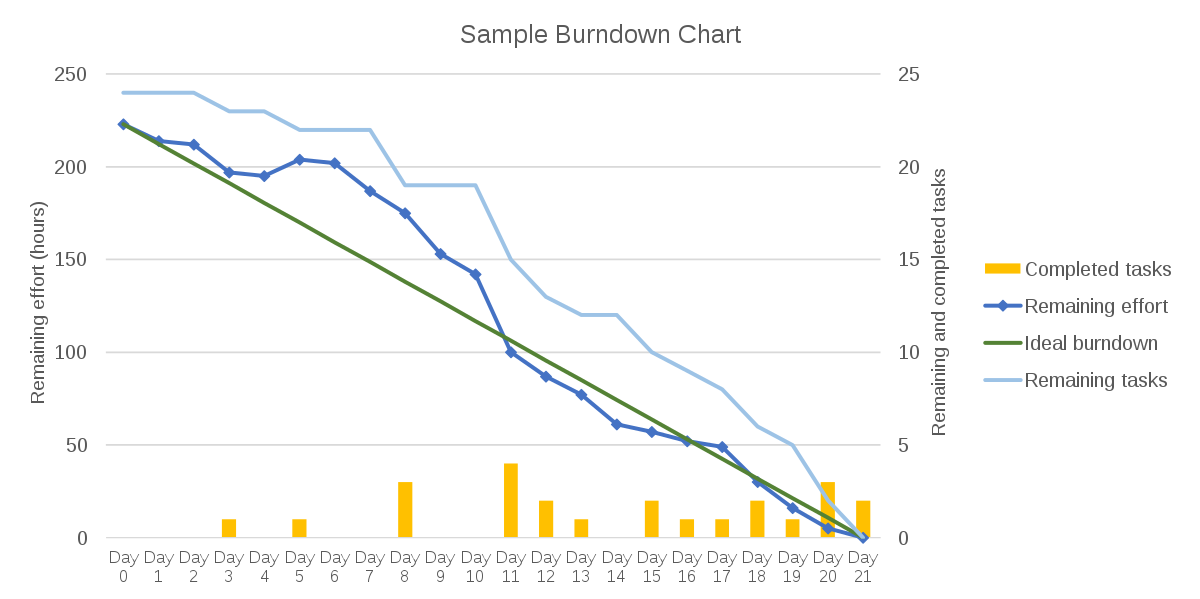
Kuva sisältää useitakin eri käyriä, tummemman sininen kuvaa sprintissä jäljellä olevaa työmäärää tunteina.
Työmääräarvio voi myös nousta kesken sprintin jos kesken sprintin identifioidaan uusia taskeja tai jokin task huomataan monimutkaisemmaksi kuin alunperin ajateltiin. Oleellista on, että taskien työmääräarviot ovat arvioita niihin vielä tarvittavasta työmäärästä.
Scrumissa ei seurata millään tavalla taskeihin käytettyä työmäärää, eli vaikka johonkin taskiin olisi käytetty 5 tuntia, sitä ei merkata mihinkään eikä sitä suoraan vähennetä työmääräarviosta vaan tehdään uusi työmääräarvio siitä, paljonko vielä ajatellaan tarvittavan aikaa, jotta story saadaan valmiiksi.
Sprintin taskboardin formaatti
Yleinen konsensus on, että ainakin Sprintin hallintaan manuaalinen postit-lappuja hyödyntävä taskboard on käytettävyydeltään ja informatiivisuudeltaan ylivertainen.
Usein toki käytetään elektronisia versioita taskboardista, joskus siihen pakottavat yritysten käytänteet, joskus taas tiimiläisten työskentelytapa ja paikka, esimerkiksi hybriidi- tai etätiimille elektroninen taskboard voi olla ainoa toimiva ratkaisu.
Erilaisia ratkaisuja elektronisen backlogin ja taskboardin muodostamiseen on lukemattomia. Voidaan käyttää jotain yleishyödyllistä sovellusta, esimerkiksi Exceliä tai Google Driveä. GitHub Projects tarjoaa nykyään varsin käyttökelpoisen taskboard-näkymän GitHubin issueihin. On myös olemassa suuri joukko enemmän tai vähemmän käyttökelpoisia sovelluksia, jotka on tehty varta vasten ketterien projektien hallintaan, muutamana esimerkkinä mainittakoon JIRA, Asana, Trello, Pivotal Tracker, Trac ja Bugzilla.
Taulukkolaskentaohjelmat toimivat kohtuullisen hyvin elektronisena taskboardina. Taulukkolaskentaa käyttäessä sprintin jokaiselle päivälle on oma sarake, johon merkitään kunkin päivän alussa estimaatti taskien jäljellä olevasta työmäärästä (tunteina):
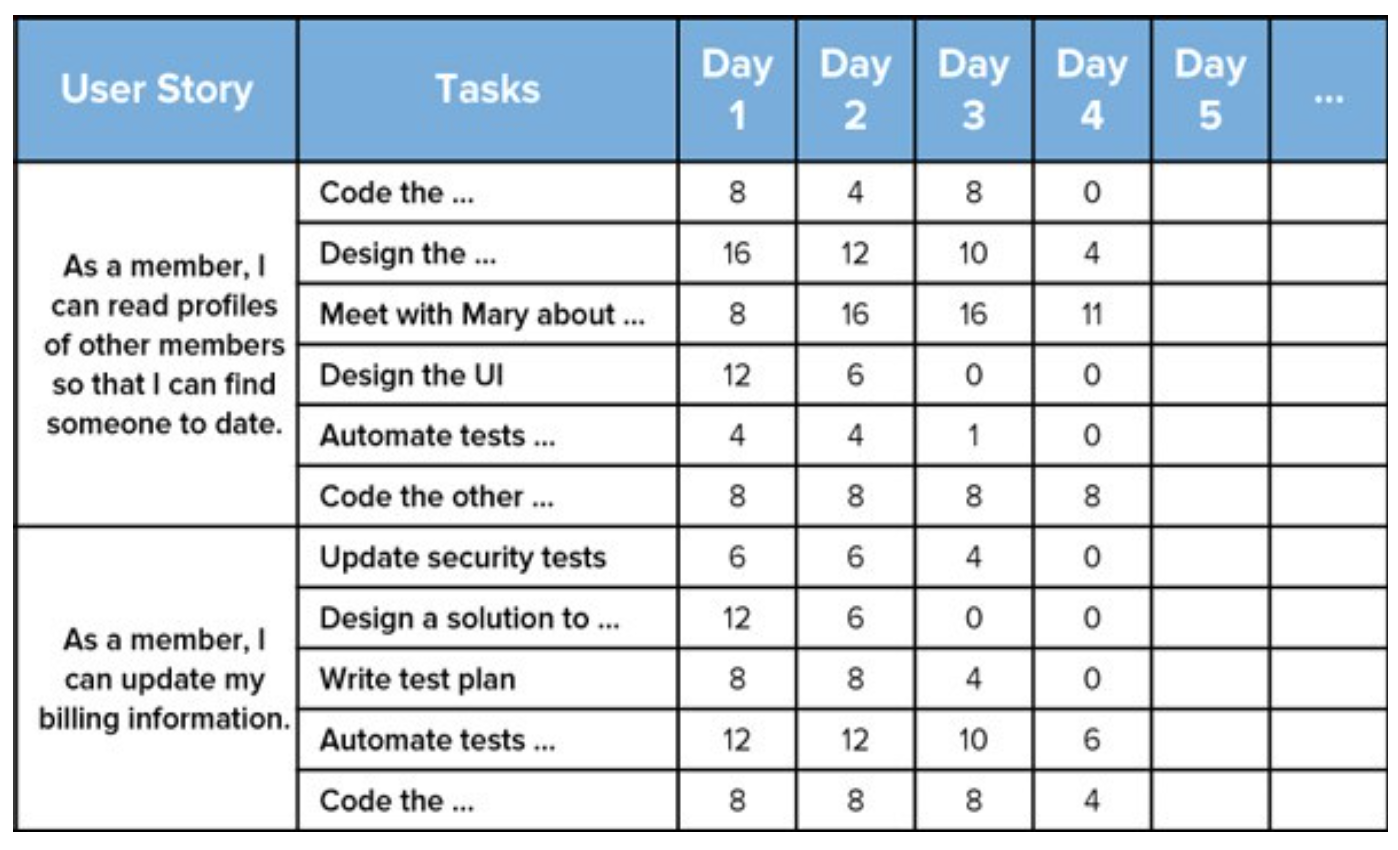
Näin sprintin burndown-kaavion piirto on helppo automatisoida. Erään ohjelmistoprojektin product- ja sprintbacklogit täällä.
Taskboard ja mahdollisesti käytössä oleva burndown-käyrä tuovat selkeästi esille sprintin etenemisen asteen ja onkin suositeltavaa, että ne ovat kaikkien tiimiläisten ja projektin sidosryhmäläisten nähtävillä. Elektronisia taskboardeja käytettäessä on aina se riski, että ne eivät säteile informaatiota yhtä hyvin kuin seinällä oleva manuaalinen taskboard. Näin ketterän kehityksen kannalta elintärkeä läpinäkyvyyden periaate saattaa vaarantua.
Kannattaako sprintin sisäinen työmäärän estimointi
On hieman kiistanalaista, kannattaako storyihin liittyvien taskien työmäärää estimoida. Uusin, eli vuonna 2020 julkaistu Scrum guide ei mainitse sprint backlogin estimoinnista mitään. Syksyllä 2019 julkaistu kirja A Scrum book ei suosittele taskien tasolla pidettävää työmääräarvioita, vaan kehottaa seuraamaan sprinttienkin aikana ainoastaan sitä kuinka monen story pointin verran user storyja on saatu valmiiksi.
Neuvo onkin varsin viisas: on nimittäin mahdollista, että tiimi saa sprintissä tehtyä lähes kaikki taskit saamatta kuitenkaan yhtäkään storya täysin valmiiksi, eli burndown voi näyttää melko hyvältä mutta asiakkaan saama arvo on lopulta nolla.
Fyysistä taskboardia käytettäessä sprintin työmäärän estimoinnin ja burndown-käyrän piirtämisen sijaan erittäin simppeli tapa sprintin etenemisen seurantaan on laskea, tai jopa ainoastaan visuaalisesti katsoa taskboardilta, mikä on jo valmiiden ja vielä valmistumattomien sprinttiin kuuluvien taskien lukumäärä.
Yhtä aikaa tehtävän työn rajoittaminen: Lean ja Scrumban
Yhtä aikaa työn alla olevien taskien suuri määrä voikin koitua scrumissa ongelmaksi, sillä riski sille, että sprintin päätyttyä on paljon osittain valmiita user storyja kasvaa. Voikin olla mielekästä rajoittaa yhtä aikaa työn alla olevien töiden määrää asettamalla work in progress (eli WIP) -rajoituksia. WIP-rajoitukset on lainattu Kanban-menetelmästä, jota käsittelemme tarkemmin osassa 5. Scrumin ja Kanbanin yhdistelmää kutsutaan usein nimellä Scrumban. Scrumbanissa on tosin muitakin Kanbanista lainattuja elementtejä kuin WIP-rajoitukset.
WIP-rajoituksia voidaan soveltaa monella tavalla, esim. rajaamalla tietyssä taskboardin vaiheessa olevien töiden määrää:
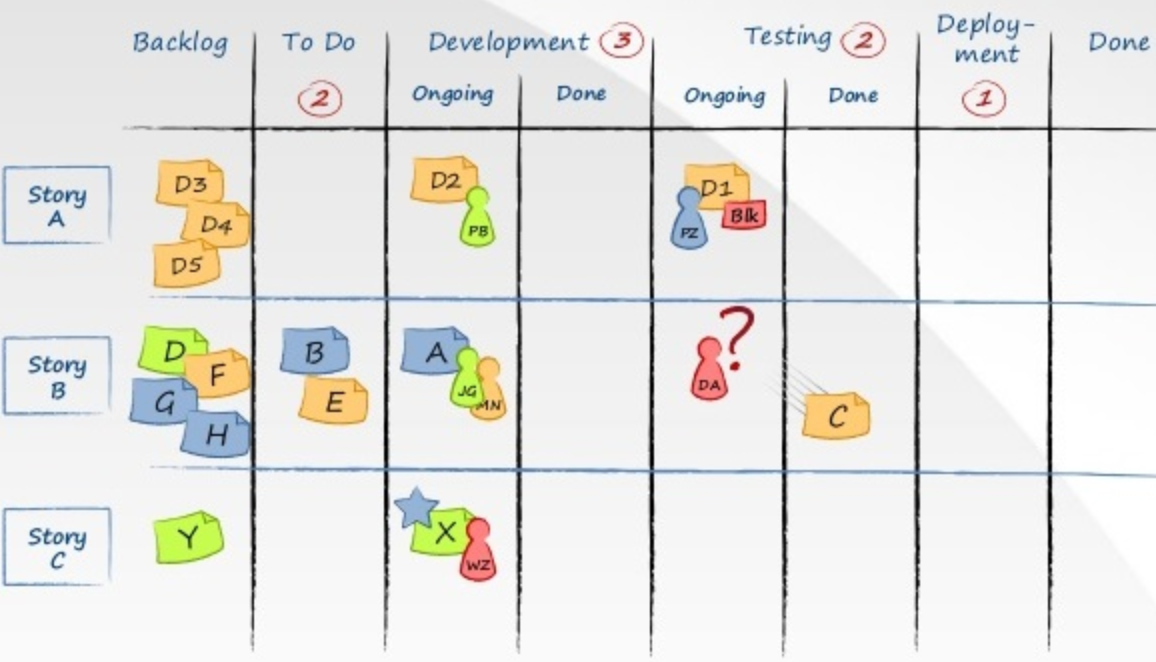
Kuvan esimerkissä rajoitteet on ilmaistu työvaiheita kuvaavien sarakkeiden otsikoihin merkittynä numerona. Esimerkiksi numero 3 sarakkeessa development määrää, että toteutusvaiheessa ei saa olla yhtä aikaa enempää kuin kolme taskia, vastaavasti 2 sarakkeessa testing rajaa kerrallaan testauksen alla olevien taskien määräksi kaksi.
Yhtä aikaa tehtävän työn määrää kontrolloivien WIP- eli Work in progress -rajoitusten idea on siis peräisin Kanban-menetelmästä. Kanban-menetelmä taas on eräs keskeisimmistä Lean-ajattelun työkaluista.
Lean-ajattelun taustalla on idea hukan (engl. waste, jap. muda) eli arvoa tuottamattomien asioiden eliminointi organisaatioiden toiminnasta. Lean-ajattelu on peräisin jo kymmeniä vuosia vanhasta Toyota Production Systemistä.
Lean tunnistaa usean tyyppistä hukkaa (lean waste), näiden joukossa ovat esimerkiksi osittain tehty työ (partially done work), välivarastointi ja turha odottaminen. Ohjelmistotuotannon kontekstiin sovellettuna työvaiheet, jotka eivät ole vielä definition of donen mielessä valmiina edustavat leanin mukaista hukkaa. Esimerkiksi testaamista odottavien toiminnallisuuksien (user storyjen) katsotaan olevan “välivarastoituna”, samoin jo testatut mutta tuotantoon viemistä vielä odottavat toiminnallisuudet ovat “välivarastossa”.
Asiakkaalle toiminnallisuudet alkavat tuottaa arvoa vasta kun ne saadaan käyttöön, siinä vaiheessa kun toiminnallisuudet ovat työn alla, ne aiheuttavat ainoastaan kustannuksia ja muodostavat riskin.
Kanban- ja Scrumban-menetelmissä WIP-rajoitteilla rajataan useimmiten yhtä aikaa työn alla olevien user storyjen määrää. Kanbanissa ja Scrumbanissa ei yleensä ole olemassa Scrumin sprintin kaltaista kehitystyötä rytmittävää käsitettä vaan saatetaan noudattaa periaatetta, missä tiimi tekee yhden user storyn kerrallaan valmiiksi, demoaa sen asiakkaalle ja valitsee product backlogista seuraavan storyn työn alle.
Joissain tapauksissa asiakastapaamiset ja valmiiden storyjen esittely voi Kanbanissa ja Scrumbanissa tapahtua sovitun aikataulun, esimerkiksi 2 viikon välein vaikka itse kehitystyö ei noudattaisi sprinttejä vaan etenisi story kerrallaan.
WIP-rajoitteita voidaan soveltaa Scrumin yhteydessä monella tapaa. Edellä olleessa esimerkissä rajoitettiin kerrallaan yhdessä työvaiheessa sallittujen taskien määrää. Voi olla mielekästä myös määritellä, kuinka monta taskia yhdellä henkilöllä saa olla yhdellä kertaa työn alla. Ehkä paras tapa soveltaa WIP-rajoitteita on rajoittaa kerrallaan työn alla olevien user storyjen määrää. Esimerkiksi Scrum book suosittelee, että työn alla on kerrallaan ainoastaan yksi user story. Näin taataan että arvoa tuottavia kokonaisuuksia “virtaa” sovelluksen käyttäjälle mahdollisimman tasaisesti.
WIP-rajoitteita säädetään usein retrospektiivien yhteydessä jos kehitystyössä havaitaan ongelmia.
Ennen seuraavaa sprintin alkua
Kuten edellisessä osassa mainittiin, pidetään sprintin lopussa sprint review eli katselmointi sekä sprintin retrospektiivi. Katselmoinnissa arvioidaan kehitystiimin tekemää työtä. Kesken jääneet tai epäkelvosti toteutetut user storyt siirretään takaisin backlogiin.
Sprintin aikana product backlogiin on ehkä tullut uusia user storyja tai jo olemassa olevia storyjä on muokattu ja uudelleenpriorisoitu. On suositeltavaa että kehitystiimi käyttää pienen määrän aikaa sprintin aikana product backlogin vaatimiin toimiin eli backlog groomingiin, esim. uusien user storyjen estimointiin. Jos product backlog on hyvässä kunnossa eli DEEP sprintin loppuessa, on jälleen helppo lähteä sprintin suunnitteluun ja uuteen sprinttiin.
Retrospektiivissa taas tiimi itse tarkastelee omaa toimintatapaansa ja identifioi mahdollisia kehityskohteita seuraavaan sprinttiin. Eräs tärkeä tarkastelun kohde retrospektiivissa on sprintin taskboard, tuoko se riittävästi läpinäkyvyyttä sprintin seurantaan, tulisko boardille lisätä näkyviin useampia työvaiheita (esim. testing, releasing, …), jumiutuiko taskeja odottamattomalla tavalla joihinkin työvaiheisiin, tulisiko boardille lisätä WIP-rajoitteita?