Osa 4

- Kurssikoe tiistaina 16.12. klo 13.00-15.30 A111 ja CHE A110. Ohje kokeeseen
- Miniprojektin lopputoimenpiteet
- Laskarien muuttuminen kurssipisteiksi selviää täältä
Sisällysluettelo
Olemme nyt käsitelleet ohjelmiston elinkaaren vaiheista vaatimusmäärittelyä ja laadunhallintaa. Tässä osassa aiheena on ohjelmiston suunnittelu ja toteutus.
Osa sisältää paljon koodiesimerkkejä.
Tämän osan luvuista ne, joihin on merkitty [viikko 6] liittyvät viikon 6 laskareihin, eli voit ohittaa ne aiemmilla viikoilla.
Typoja materiaalissa
Tee korjausehdotus editoimalla tätä tiedostoa GitHubissa.
Kurssipalaute
Kurssilla on käytössä normaalin lopussa kerättävän palautteen lisäksi ns. jatkuva palaute: voit antaa milloin vain kurssihenkilökunnalle anonyymiä palautetta osoitteessa https://norppa.helsinki.fi/targets/95023982/feedback
Ohjelmiston suunnittelu
Ohjelmiston suunnittelu jakautuu yleensä kahteen vaiheeseen: arkkitehtuurisuunnitteluun ja olio- tai komponenttisuunnitteluun.
Arkkitehtuurisuunnittelussa hahmotellaan ohjelman rakenne karkealla tasolla, eli mietitään mistä suuremmista rakennekomponenteista ohjelma koostuu. Miten komponentit kommunikoivat ja minkälaiset niiden väliset rajapinnat ovat.
Olio- tai komponenttisuunnittelussa taas suunnitellaan yksityiskohtaisemmin, miten yksittäiset komponentit, luokat ja metodit tulisi toteuttaa.
Näiden teknisten näkökulmien lisäksi ohjelmiston määrittelyn ja suunnittelun välimaastossa on käyttöliittymä- ja käyttökokemussuunnittelu, joihin kurssin materiaalissa ei valitettavasti pystytä syventymään. Osastolla on muutamia syventäviä kursseja aihepiiristä, mm. Human computer interaction.
Ohjelmiston suunnittelun ajoittuminen riippuu käytettävästä tuotantoprosessista. Vesiputousmallissa suunnittelu tapahtuu vaatimusmäärittelyn jälkeen ja ohjelmointi aloitetaan vasta kun suunnittelu on valmiina ja dokumentoitu. Ketterissä menetelmissä suunnittelua tehdään jokaisessa sprintissä tarpeen mukaan, eikä tarkkaa suunnitteludokumenttia yleensä laadita.
Vesiputousmallin mukainen suunnitteluprosessi tuskin on enää juuri missään käytössä, ja ainakin vaatimusmäärittely ja arkkitehtuurisuunnittelu limittyvät.
Tarkkaa ja raskasta suunnittelua ennen ohjelmointia, jota kutsutaan joskus nimellä Big Design Up Front (BDUF), tehdään yhä. Se sopii erityisesti järjestelmiin, joissa sovellusalue tunnetaan hyvin ja vaatimukset eivät muutu.
Ohjelmiston arkkitehtuuri
Käsite ohjelmiston arkkitehtuuri (engl. software architecture) on ollut olemassa jo vuosikymmeniä. Termi on vakiintunut yleiseen käyttöön 2000-luvun aikana ja on siirtynyt mm. riviohjelmoijaa kokeneempaa työntekijää tarkoittavaksi nimikkeeksi ohjelmistoarkkitehti engl. software architect.
Useimmilla alan ihmisillä on jonkinlainen kuva siitä, mitä ohjelmiston arkkitehtuurilla tarkoitetaan. Termiä ei ole kuitenkaan yrityksistä huolimatta onnistuttu määrittelemään siten, että kaikki olisivat määritelmästä yksimielisiä.
IEEE:n standardi Recommended practices for Architectural descriptions of Software intensive systems määrittelee käsitteen seuraavasti:
Ohjelmiston arkkitehtuuri on järjestelmän perusorganisaatio, joka sisältää järjestelmän osat, osien keskinäiset suhteet, osien suhteet ympäristöön sekä periaatteet, jotka ohjaavat järjestelmän suunnittelua ja evoluutiota.
Otetaan esimerkiksi pari muutakin määritelmää.
Philippe Krutchten määrittelee arkkitehtuurin seuraavasti
An architecture is the set of significant decisions about the organization of a software system, the selection of structural elements and their interfaces by which the system is composed, together with their behavior as specified in the collaborations among those elements, the composition of these elements into progressively larger subsystems, and the architectural style that guides this organization - these elements and their interfaces, their collaborations, and their composition.
McGovern ym. taas sanovat
The software architecture of a system or a collection of systems consists of all the important design decisions about the software structures and the interactions between those structures that comprise the systems. The design decisions support a desired set of qualities that the system should support to be successful. The design decisions provide a conceptual basis for system development, support, and maintenance.
Vaikka arkkitehtuurin määritelmät hieman vaihtelevat, löytyy määritelmistä joukko samoja teemoja. Jokaisen määritelmän mukaan arkkitehtuuri määrittelee ohjelmiston rakenteen, eli jakautumisen erillisiin osiin sekä osien väliset rajapinnat. Arkkitehtuuri ottaa kantaa rakenteen lisäksi myös käyttäytymiseen, se määrittelee arkkitehtuuritason rakenneosien vastuut ja niiden keskinäisen kommunikoinnin muodot.
Arkkitehtuuri keskittyy järjestelmän tärkeimpiin rakenteellisiin periaatteisiin. Se ei kuvaa järjestelmää yksityiskohtaisesti, vaan keskittyy suuriin linjoihin ja toimii abstraktiona.
Artikkelissa Who needs an architect Martin Fowler toteaa seuraavasti you might end up defining architecture as things that people perceive as hard to change, eli arkkitehtuurin voisi määritellä niiksi asioiksi, jotka ovat ohjelmistossa vaikeita muuttaa. Järjestelmän tärkeät rakenneperiaatteet voivat myös muuttua ajan myötä, eli arkkitehtuuri ei ole muuttumaton mutta sen radikaali muuttaminen voi olla haastavaa.
Melkein sama hieman toisin ilmaistuna oli Krutchtenin määritelmässä mainittu set of significant decisions about the organization of a software system, eli arkkitehtuuri muodostuu arkkitehtuuristen päätösten, eli joukon ohjelmiston rakenteen ja toiminnan kannalta tehtävien fundamentaalisten valintojen kautta.
Arkkitehtuuriin vaikuttavia tekijöitä
Osassa 2 mainittiin järjestelmän vaatimusten jakautuvat kahteen luokkaan, toiminnallisiin ja ei-toiminnallisiin vaatimuksiin.
Järjestelmän ei-toiminnalliset laatuvaatimukset (engl. -ilities) vaikuttavat merkittävästi arkkitehtuuriin. Laatuvaatimuksia ovat esimerkiksi käytettävyys, suorituskyky, skaalautuvuus, vikasietoisuus, tiedon ajantasaisuus, tietoturva, ylläpidettävyys, laajennettavuus, testattavuus, hinta, time-to-market, …
Koska jotkin laatuvaatimukset voivat olla ristiriidassa keskenään, arkkitehdin on löydettävä kompromissi, joka tyydyttää kaikkia sidosryhmiä. Esimerkiksi time-to-market, eli kuinka nopeasti sovellus saadaan loppukäyttäjille ja alhainen hinta, lienevät ristiriidassa lähes kaikkien laatuvaatimusten kanssa.
Tiedon ajantasaisuus, skaalautuvuus ja vikasietoisuus ovat ominaisuuksia, joiden välillä on usein tehtävä kompromisseja. On jopa matemaattisesti todistettu, että kaikissa tilanteissa ei voida saavuttaa kaikkia näitä yhtä aikaa (ks. CAP-teoreema).
Myös toteutusteknologiat, esimerkiksi toteutuksessa käytettävät sovelluskehykset ja integraatio olemassaoleviin järjestelmiin sekä järjestelmän toimintaympäristö esim. lääketieteen ja ilmailualan säädökset sekä edellytetyt toimintastandardit, vaikuttavat arkkitehtuuriin.
Arkkitehtuurin suurin merkitys on antaa sovelluksen kehitykselle ja ylläpidolle sellaiset raamit, että sovellus pystyy jatkossakin vastaamaan asiakkaan asettamien toiminnallisten vaatimusten lisäksi järjestelmälle asetettuihin laatuvaatimuksiin.
Joskus käy niin, että sovellukselle alunperin valittu arkkitehtuuri ei enää palvele tarkoitustaan. Näin voi esimerkiksi käydä, jos sovelluksen laatuvaatimukset muuttuvat radikaalisti, esim. jos tulee tarve saada sovellus skaalautumaan huomattavasti suuremmalle käyttäjäjoukolle, mitä alkuperäinen arkkitehtuuri kykenee. Arkkitehtuurin muuttaminen on hankalaa ja kallista, mutta joskus muuta vaihtoehtoa ei ole.
Arkkitehtuurityyli
Ohjelmiston arkkitehtuuri perustuu yleensä yhteen tai useampaan arkkitehtuurityyliin (engl. architectural style), jolla tarkoitetaan hyväksi havaittua tapaa strukturoida tietyntyyppisiä sovelluksia.
Arkkitehtuurityylejä on suuri määrä, esim:
- Kerrosarkkitehtuuri
- Model-view-controller
- Pipes-and-filters
- Client-server
- Publish-subscribe
- Event driven
- REST
- Mikropalveluarkkitehtuuri
- Palveluperustainen arkkitehtuuri
Useimmiten sovelluksen rakenteesta löytyy monien arkkitehtuuristen tyylien piirteitä.
Kerrosarkkitehtuuri
Arkkitehtuurityyleistä varmasti tunnetuin ja eniten käytetty on kerrosarkkitehtuuri (engl. layered architecture), jossa pyrkimyksenä on jakaa sovellus käsitteellisiin kerroksiin, joissa kukin kerros suorittaa oman “abstraktiotason” tehtäväänsä käyttäen ainoastaan sen alapuolella olevan kerroksen palveluja.
Kerrosarkkitehtuurissa ylimmät kerrokset ovat lähempänä käyttäjää, ylimpänä kerroksena on yleensä käyttöliittymä (kuvassa presentation layer) ja tämän alapuolella sovelluslogiikasta (kuvassa business layer) vastaava kerros. Alimmat kerrokset taas keskittyvät koneläheisiin asioihin, kuten tiedon tallennukseen (kuvassa persistence layer ja database layer) tai verkon yli tapahtuvaan kommunikaatioon.
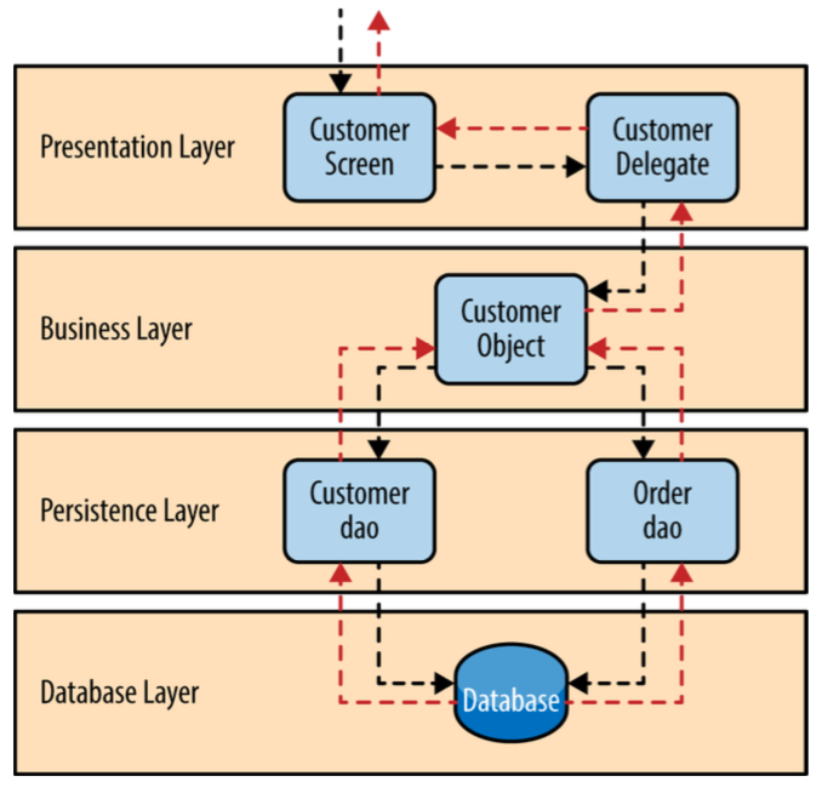
Käytännössä kukin kerros on kokoelma toisiinsa liittyviä olioita tai komponentteja, jotka muodostavat oman abstraktiotasonsa toiminnallisuuden suhteen loogisen kokonaisuuden.
Kerrosarkkitehtuurilla on monia etuja. Kerroksittaisuus helpottaa ylläpitoa, sillä jos tietyn kerroksen palvelurajapintaan eli muille kerroksille näkyvään osaan tehdään muutoksia, aiheuttavat muutokset ylläpitotoimenpiteitä ainoastaan suoraan yläpuolella olevaan kerroksen. Esim. käyttöliittymän muutokset eivät vaikuta muihin kerroksiin ja tiedon tallennuksesta huolehtivaan kerrokseen tehtävät muutokset eivät vaikuta käyttöliittymään.
Sovelluslogiikan riippumattomuus käyttöliittymästä helpottaa ohjelman siirtämistä uusille alustoille, esimerkiksi toimimaan webin lisäksi mobiiliympäristössä. Alimpien kerroksien palveluja, kuten tallennuskerrosta tai ainakin sen osia voidaan mahdollisesti uusiokäyttää myös muissa sovelluksissa.
Kerrosarkkitehtuuri on sovelluskehittäjän kannalta selkeä ja hyvin ymmärretty malli, mutta sen soveltaminen saattaa johtaa massiivisiin monoliittisiin sovelluksiin, joita on lopulta vaikea laajentaa ja joiden skaalaaminen tukemaan suuria yhtäaikaisia käyttäjämääriä voi muodostua ongelmaksi.
Todo-sovelluksen arkkitehtuuri
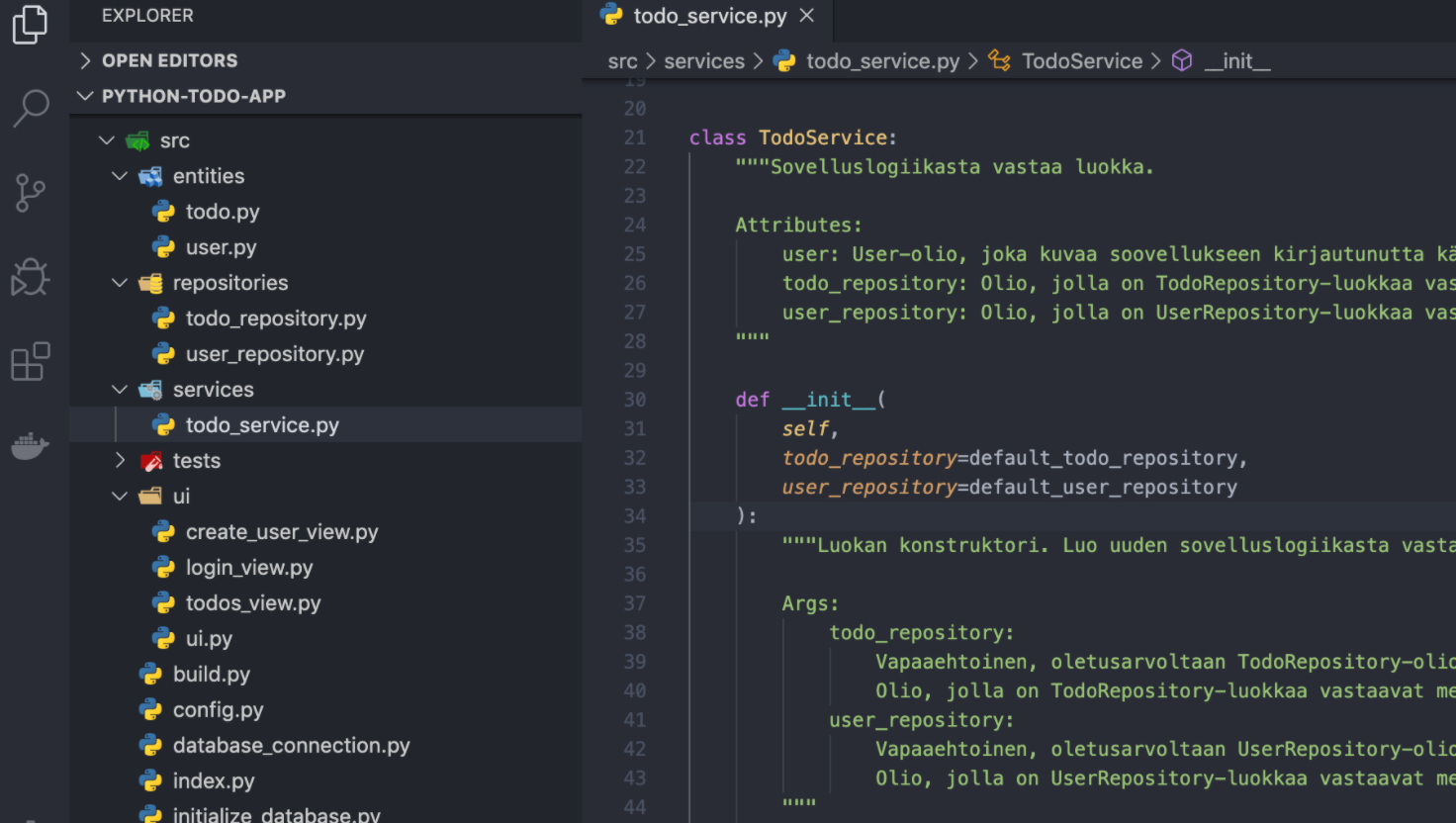
Eräs konkreettinen, joskin hyvin yksinkertainen esimerkki kerrosarkkitehtuuria noudattavasta sovelluksesta on kurssin Ohjelmistotekniikka referenssisovelluksena toimiva Todo-sovellus.
Koodin tasolla kerrosrakenne näkyy siinä, miten sovelluksen koodi jakautuu hakemistoihin:
Arkkitehtuuria heijasteleva pakkausrakenne voidaan kuvata UML:n pakkauskaaviolla:
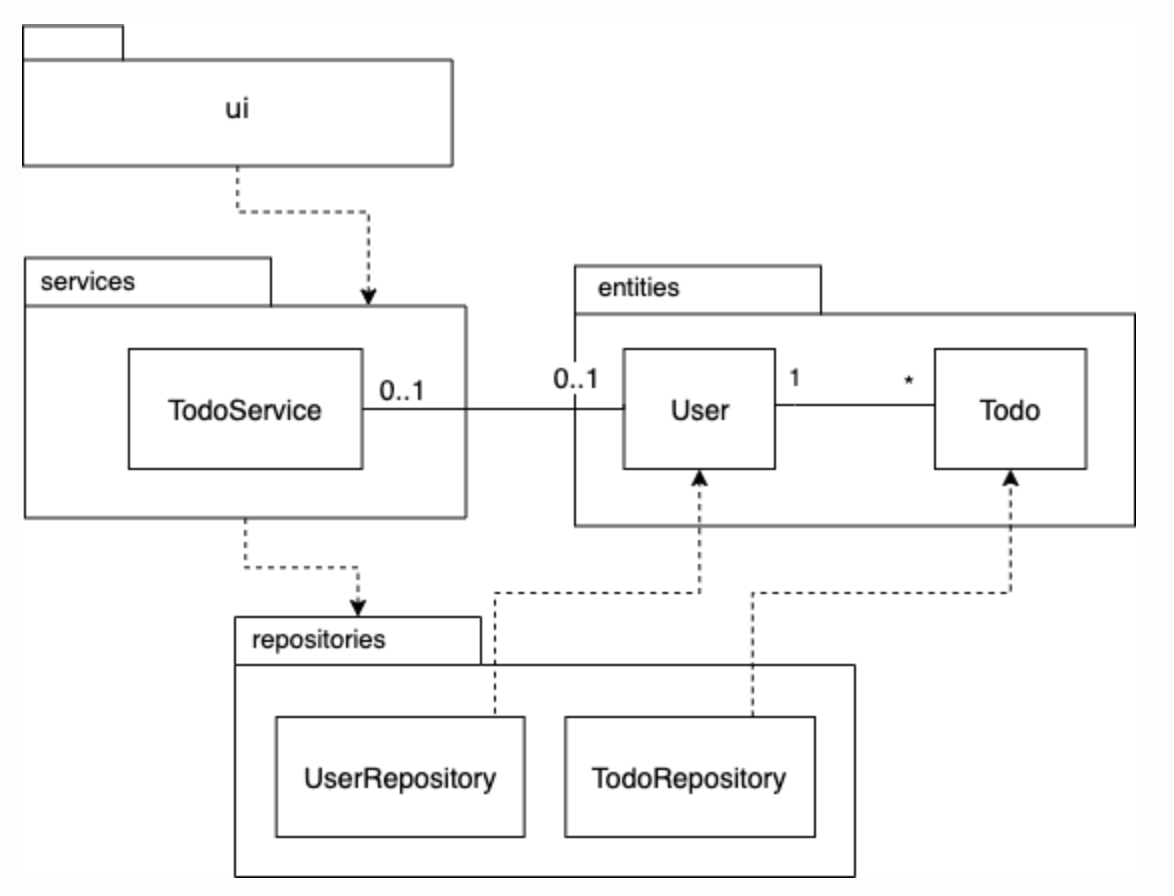
Pakkauksina kuvattujen kerroksien välille on merkitty riippuvuudet katkoviivalla. Käyttöliittymä ui riippuu sovelluslogiikasta services, joka taas riippuu tallennuskerroksesta repositories.
Käytännössä riippuvuus tarkoittaa sitä, että ylemmän kerroksen koodista kutsutaan jotain alemman kerroksen koodin metodia. Kerrosarkkitehtuurin hengen mukaisesti riippuvuuksia on vain ylhäältä alas, eli esim. sovelluslogiikkakerroksen koodi ei kutsu käyttöliittymäkerroksen koodia.
Sekä sovelluslogiikka, että tallennuspalvelut käyttävät pakkauksen entities-olioita. Vaikka kyseinen pakkaus kuuluu loogisesti ajatelleen tallennuspalveluita ylempään “bisneslogiikkakerrokseen”, ohjelmakoodin tasolla alempana oleva tallennuskerros on riippuvainen pakkauksesta sillä se käsittelee pakkauksen luokkien koodia.
Arkkitehtuurin kuvaamisesta
Kovista yrityksistä huolimatta ohjelmistojen arkkitehtuurien kuvaamiselle ei ole onnistuttu kehittämään mitään yleisesti käytössä olevaa notaatiota. UML:ää käytetään jonkin verran, mutta kovin suosittu ja käyttökelpoinen ei sekään ole. Edellisessä esimerkissä käytettyä pakkauskaaviota paremmin isompien sovellusten arkkitehtuurien kuvaamiseen sopii komponenttikaavio.
Komponenttikaavio eroaa pakkauskaaviosta lähinnä merkintätavoiltaan ja tuo hieman paremmin esiin eri komponenttien tarjoamat sekä käyttämät rajapinnat. Esimerkiksi alla olevassa kuvassa oleva verkkokaupan sovelluslogiikasta vastaava komponentti web store tarjoaa rajapinnat tuotteiden haulle, ostosten tekemiselle ja käyttäjien hallinnoinnille. Komponentti itsessään jakautuu kolmeen alikomponenttiin, joista authentication tarjoaa sisäisen rajapinnan shopping chart -komponentin käyttöön.
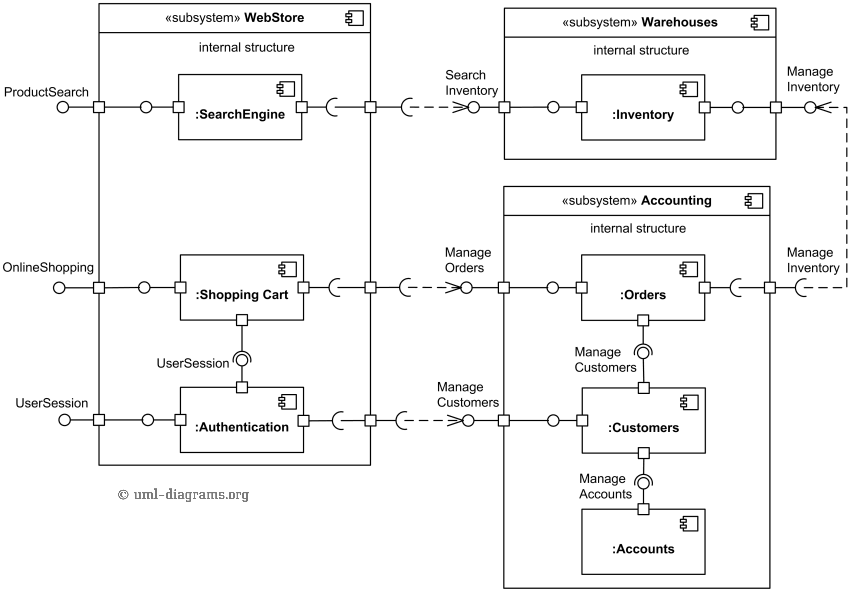
UML:n sijaan arkkitehtuurin kuvaamiseen käytetään kuitenkin useimmiten epäformaaleja laatikko/nuoli-kaavioita.
Seuraavassa esimerkki oman sovelluskehitystiimini valkotaululle piirtämästä arkkitehtuurikuvauksesta:
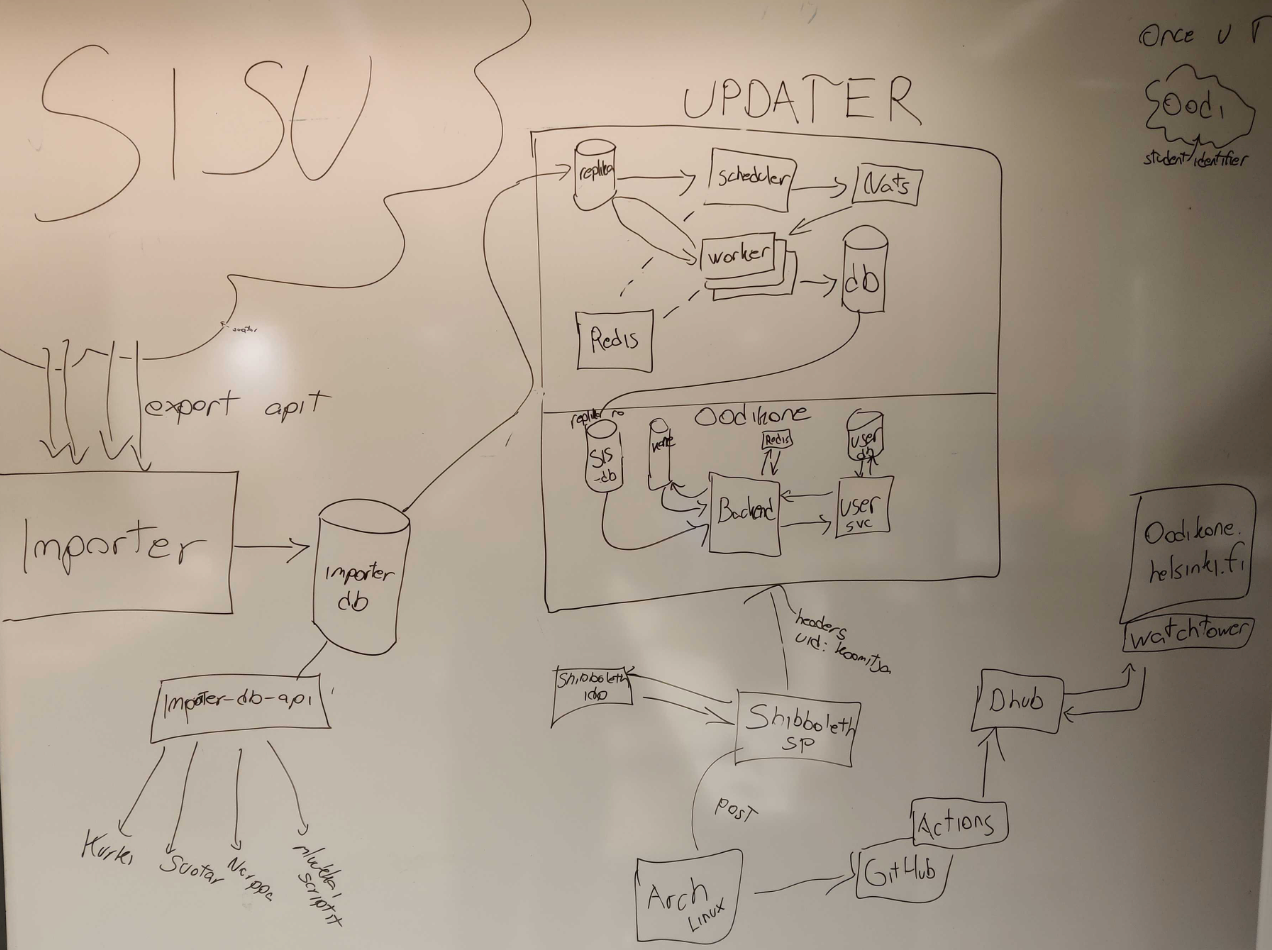
Arkkitehtuurikuvaus kannattaa tehdä useasta näkökulmasta, sillä ne vastaavat erilaisiin tarpeisiin. Korkean tason kuvauksen avulla voidaan esim. strukturoida vaatimusmäärittelyn aikana käytäviä keskusteluja eri sidosryhmien kanssa. Yksityiskohtaisemmat kuvaukset taas toimivat ohjeena järjestelmän tarkemmassa suunnittelussa ja ylläpitovaiheen aikaisessa laajentamisessa.
Kannattaa huomata, että arkkitehtuurikuvaus ei suinkaan ole pelkkä kuva, mm. komponenttien vastuut tulee tarkentaa sekä niiden väliset rajapinnat ja kommunikaation muodot määritellä. Jos näin ei tehdä, kasvaa riski sille että arkkitehtuuria ei noudateta.
Hyödyllinen arkkitehtuurikuvaus myös perustelee tehtyjä arkkitehtuurisia valintoja. Ei nimittäin ole ollenkaan harvinaista, että jotain ohjelmistoon tehtyjä arkkitehtuuritason suunnitteluratkaisuja ihmetellään parin vuoden päästä ja kukaan ei enää muista aikoinaan tarkasti mietittyjä perusteita tehdyille päätöksille.
Mikropalveluarkkitehtuuri
Kerrosarkkitehtuurin eräänä epäkohtana mainittiin, että sen soveltaminen saattaa johtaa massiivisiin monoliittisiin sovelluksiin, joita on lopulta vaikea laajentaa ja joiden skaalaaminen suurille käyttäjämäärille voi muodostua ongelmaksi.
Mikropalveluarkkitehtuuri (engl. microservices), joka on yleistynyt viime aikoina, pyrkii ratkaisemaan nämä ongelmat. Se jakaa sovelluksen useisiin pieniin, verkossa toimiviin ja itsenäisiin palveluihin, jotka kommunikoivat keskenään verkon välityksellä.
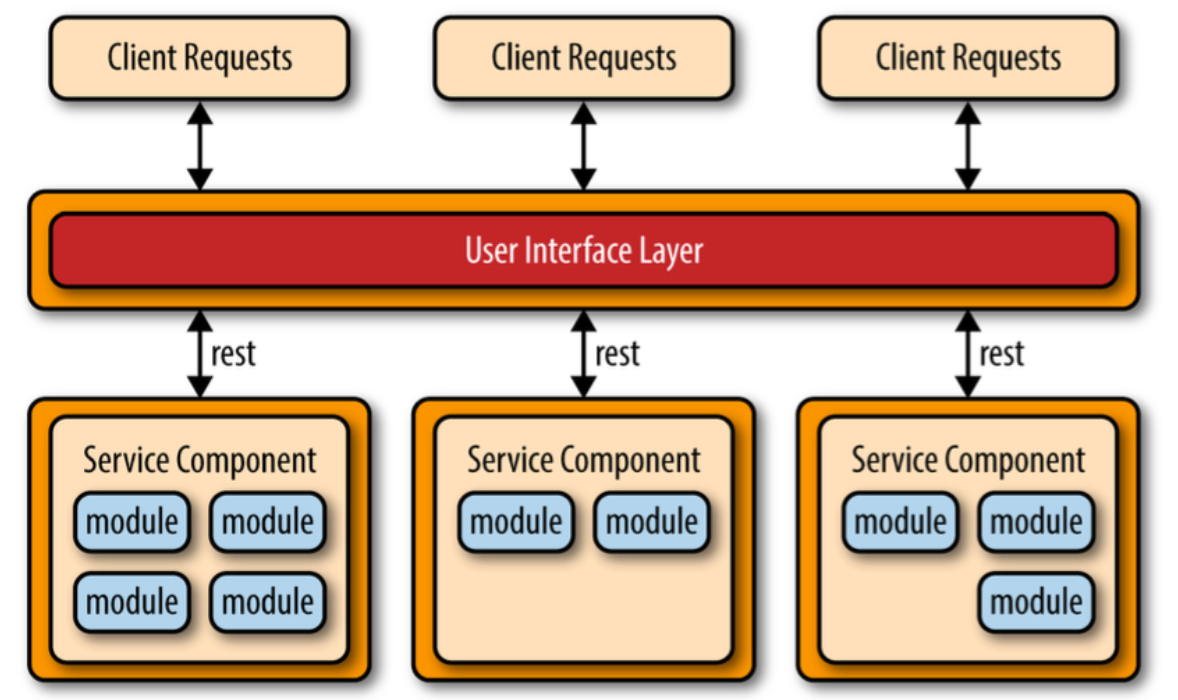
Mikropalveluihin perustuvassa sovelluksessa yksittäisistä palveluista pyritään tekemään mahdollisimman riippumattomia ja löyhästi toisiinsa kytkettyjä. Palvelut eivät esimerkiksi käytä yhteistä tietokantaa eivätkä jaa koodia. Palvelut eivät kutsu suoraan toistensa metodeja, sen sijaan ne kommunikoivat verkon välityksellä.
Mikropalveluiden on tarkoitus olla suhteellisen pieniä ja huolehtia vain “yhdestä asiasta”. Esimerkiksi verkkokaupassa erillisiä mikropalveluja voisivat olla:
- Käyttäjien hallinta
- Tuotteiden suosittelu
- Tuotteiden hakutoiminnot
- Ostoskorin toiminnallisuus
- Ostosten maksusta huolehtiva toiminnallisuus
Järjestelmään lisätään toiminnallisuutta yleensä toteuttamalla uusia palveluita tai laajentamalla olemassa olevia. Sovelluksen laajentaminen voi näin olla helpompaa kuin kerrosarkkitehtuurissa, missä laajennus yleensä edellyttää jokaisessa kerroksessa olevan koodin muokkaamista.
Mikropalveluja hyödyntävää sovellusta voi olla helpompi skaalata, sillä suorituskyvyn pullonkaulan aiheuttavia mikropalveluja voidaan suorittaa useita rinnakkain.
Mikropalveluilla sovellusta voi kehittää helposti useilla ohjelmointikielillä tai eri sovelluskehyksillä. Toisin kuin monoliittisissa projekteissa, mikään ei edellytä, että kaikki mikropalvelut olisi toteutettu samalla tekniikalla.
Mikropalveluiden kommunikointi
Mikropalvelut siis kommunikoivat keskenään verkon välityksellä. Erilaisia tapoja kommunikointiin on useita.
Yksinkertainen vaihtoehto on käyttää kommunikointiin HTTP-protokollaa, eli samaa mekanismia, jonka avulla web-selaimet keskustelevat palvelimien kanssa. Tällöin sanotaan, että mikropalvelut tarjoavat kommunikointia varten REST-rajapinnan. Viikon 3 laskareissa haettiin NHL-tilastotietoja JSON-muotoista dataa tarjoavasta REST-rajapinnasta.
Vaihtoehtoinen, huomattavasti joustavampi kommunikointikeino on ns. viestinvälityksen (message queue/bus) käyttö.
Palvelut eivät lähetä viestejä suoraan toisilleen, vaan käytössä on verkossa toimiva viestinvälityspalvelu, joka hoitaa viestien välityksen eri palveluiden välillä.
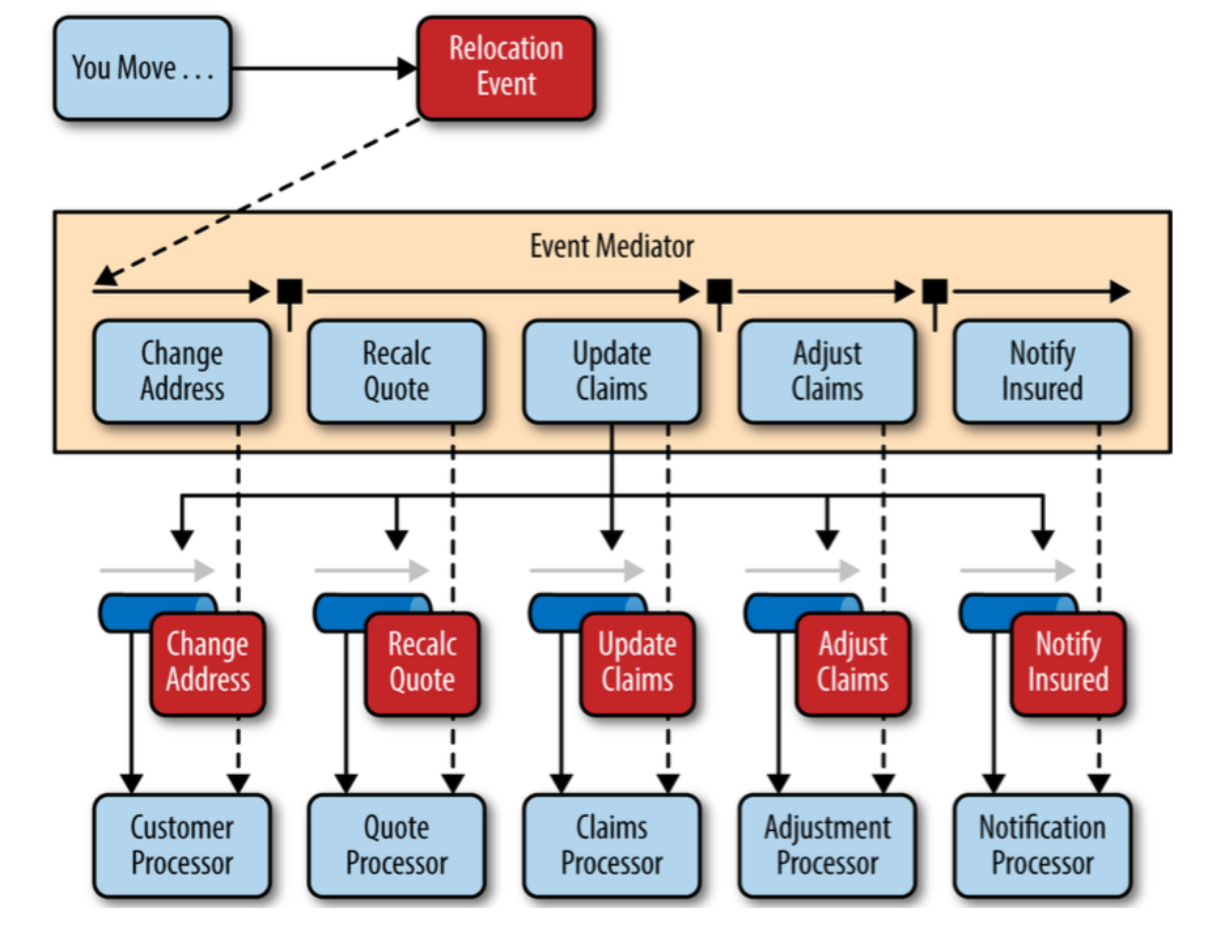
Periaatteena viestinvälityksessä on se, että palvelut julkaisevat (publish) viestejä viestinvälityspalveluun. Viesteillä on tyypillisesti jokin aihe (topic) ja sen lisäksi datasisältö, esimerkiksi:
{
"topic": "new_user",
"data": {
"username": "Arto Hellas",
"age": 31,
"education": "PhD",
"occupation": "Aalto University"
}
}
Palvelut voivat tilata (subscribe) viestipalvelusta niihin aiheisiin liittyvät viestit joista ne ovat kiinnostuneita. Esimerkiksi käyttäjähallinnasta vastaava palvelu todennäköisesti tilaa viestit, joiden aihe on new_user. Viestinvälityspalvelu välittää vastaanottamansa viestit edelleen kaikille palveluille, jotka ovat kyseisen aiheen tilanneet.
Kaikki viestien välitys tapahtuu siis viestinvälityspalvelun kautta, eli palvelut eivät kommunikoi suoraan toistensa kanssa. Näin mikropalveluista tulee erittäin löyhästi kytkettyjä, ja muutokset yhdessä palvelussa eivät vaikuta mihinkään muualle, niin kauan kuin viestit säilyvät entisen muotoisina.
Viestien lähetys on lähettäjän kannalta asynkronista eli palvelu lähettää viestin, jatkaa se heti koodissaan eteenpäin siitä huolimatta onko viesti välitetty sen tilanneille palveluille.
Asynkronisten viestien (joita kutsutaan usein myös eventeiksi) välitykseen perustuvaa arkkitehtuureja kutsutaan myös event-driven-arkkitehtuureiksi. Kaikki event-driven-arkkitehtuurit eivät suinkaan ole mikropalveluarkkitehtuureja, esim. Pythonin Tkinter-kirjaston avulla toteutettu käyttöliittymä kommunikoi sovelluksen kanssa eventtien avulla.
Mikropalveluiden haasteita
Monista eduistaan huolimatta mikropalveluarkkitehtuurin soveltaminen tuo mukanaan koko joukon uusia haasteita. Ensinnäkin sovelluksen jakaminen järkeviin mikropalveluihin on haastavaa. Vääränlainen jako palveluihin voi tuottaa sovelluksen, jossa jokainen palvelu joutuu keskustelemaan verkon yli pahimmassa tapauksessa kymmenien palvelujen kesken ja näin sovelluksen suorituskyky kärsii.
Useista palveluista koostuvan sovelluksen debuggaaminen ja testaaminen on monimutkaisempaa kuin monoliittisen. Tämä on erityisen totta, jos mikropalvelut käyttävät viestinvälitystä.
Kymmenistä tai sadoista mikropalveluista koostuvan ohjelmiston käynnistäminen ja hallinta tuotantopalvelimilla on haastavaa ja vaatii pitkälle vietyä automatisointia. Sama koskee sovelluskehitysympäristöä ja jatkuvaa integraatiota. Mikropalveluiden menestyksekäs soveltaminen edellyttääkin vahvaa DevOps-kulttuuria.
Mikropalveluiden yhteydessä käytetäänkin paljon konttiteknologiaa (engl. container), eli käytännössä Docker-ohjelmistoa. Kontit ovat hieman yksinkertaistaen sanottuna kevyitä virtuaalikoneita, joita on mahdollista suorittaa suuret määrät yksittäisellä palvelimella. Jos mikropalvelu on omassa kontissa, vastaa se käytännössä tilannetta, missä mikropalvelua suoritettaisiin omalla koneellaan.
Aihe on tärkeä, mutta emme valitettavasti voi mennä siihen tämän kurssin puitteissa ollenkaan, onneksi Avoimessa yliopistossa on tarjolla sopiva kurssi aiheesta: DevOps with Docker.
Arkkitehtuuri ketterissä menetelmissä
Ketterien menetelmien kantava teema on toimivan, asiakkaalle arvoa tuottavan ohjelmiston nopea toimittaminen, tämä on mainittu selkeästi jo ketterän manifestin periaatteissa:
Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
Ketterät menetelmät suosivat suunnitteluratkaisujen yksinkertaisuutta:
Simplicity, the art of maximizing the amount of work not done, is essential
Arkkitehtuuriin suunnittelu ja dokumentointi taas on perinteisesti ollut melko pitkäkestoinen, ohjelmoinnin aloittamista edeltävä vaihe, eräänlainen Big Design Up Front. Ketterät menetelmät ja “arkkitehtuurivetoinen” ohjelmistotuotanto ovat siis jossain määrin keskenään ristiriidassa.
Ketterien menetelmien yhteydessä puhutaan usein inkrementaalisesta suunnittelusta ja arkkitehtuurista.
Ideana on, että arkkitehtuuri mietitään ja dokumentoidaan riittävällä tasolla projektin alussa. Ohjelmiston lopullinen arkkitehtuuri muodostuu iteraatio iteraatiolta samalla kun ohjelmistoon toteutetaan uutta toiminnallisuutta. Esimerkiksi kerrosarkkitehtuurin mukaista sovellusta ei rakenneta “kerros kerrallaan”, vaan sen sijaan jokaisessa iteraatiossa tehdään pieni pala jokaista kerrosta, sen verran kuin iteraation toiminnallisuuksien toteuttaminen edellyttää.
Melko tyypillinen tapa on aloittaa projektit ns. nollasprintillä, jonka aikana luodaan mm. alustava arkkitehtuuri sekä backlog.
Scrumin varhaisissa artikkeleissa puhuttiin “pre game”-vaiheesta, jonka aikana tehtiin erilaisia kehitystyötä valmistelevia asioita, mm. hahmoteltiin alustava arkkitehtuuri. Sittemmin koko käsite on hävinnyt Scrumista ja toinen Scrumin alkuperäisistä kehittäjistä Ken Schwaber jopa eksplisiittisesti kieltää ja tyrmää koko “nollasprintin” olemassaolon.
Kävelevä luuranko
Yleinen lähestymistapa inkrementaaliseen arkkitehtuuriin on kävelevän luurangon, eli walking skeletonin käyttö. Alistair Coburn kuvailee käsitettä seuraavasti:
A Walking Skeleton is a tiny implementation of the system that performs a small end-to-end function. It need not use the final architecture, but it should link together the main architectural components.
The architecture and the functionality can then evolve in parallel.
What constitutes a walking skeleton varies with the system being designed.
For a layered architecture system, it is a working connection between all the layers.
The walking skeleton is not complete or robust and it is missing the flesh of the application functionality. Incrementally, over time, the infrastructure will be completed and full functionality will be added.
A walking skeleton, is permanent code, built with production coding habits, regression tests, and is intended to grow with the system.
Eli heti projektin alussa, mielellään jo ensimmäisessä sprintissä on tarkoitus toteuttaa suunnitellun arkkitehtuurin rungon sisältävä walking skeleton, joka sisältää jo rungon kaikista arkkitehtuurin peruskomponentteista ja kerroksia vastaavat tynkäkomponentit sekä niiden välisen kommunikaation.
Tätä luurankoa sitten kasvatetaan pikkuhiljaa projektin edetessä, kun sovelluksen toiminnallisuus kasvaa.
Walking skeleton ei ole pelkästään poisheitettävää koodia, vaan sovelluksen koodi rakentuu sen ympärille, eli skeletonia rakennettaessa on jo tarkoituksenmukaisin osin syytä ohjelmoida tuotantokoodin edellyttämällä laadulla, eli projektin definition of donea noudattaen.
Inkrementaalisen arkkitehtuurin etuja
Perinteisesti, esimerkiksi vesiputousmallia käytettäessä arkkitehtuurista on vastannut ohjelmistoarkkitehti ja ohjelmoijat ovat olleet velvoitettuja noudattamaan sovellukselle määriteltyä arkkitehtuuria.
Ketterissä menetelmissä ei suosita erillistä arkkitehdin roolia, esimerkiksi Scrum käyttää kaikista ryhmän jäsenistä nimikettä developer. Ketterien menetelmien ideaalina on, että kehitystiimi luo arkkitehtuurin yhdessä, tämä on myös yksi ketterän manifestin periaatteista:
The best architectures, requirements, and designs emerge from self-organizing teams.
Ketterän ideaalin mukaan ohjelmiston arkkitehtuuri on koodin tapaan tiimin yhteisomistama. Tästä on muutamiakin etuja.
Kehittäjät todennäköisesti sitoutuvat paremmin tiimin luoman ja omistaman arkkitehtuurin noudattamiseen kuin “norsunluutornissa” olevan tiimin ulkopuolisen arkkitehdin määrittelemään arkkitehtuuriin.
Tiimin keskenään suunnitteleman arkkitehtuurin dokumentointi voi olla kevyt ja informaali, esim. valkotaululle piirretty, sillä tiimi tuntee joka tapauksessa arkkitehtuurin hengen ja pystyy sitä noudattamaan. Jos arkkitehtuurin suunnittelee joku ulkopuolinen, sen kommunikointi tiimille edellyttää raskaampaa dokumentaatiota.
Ketterissä menetelmissä oletuksena on, että parasta mahdollista arkkitehtuuria ei pystytä suunnittelemaan projektin alussa, kun vaatimuksia, toimintaympäristöä ja toteutusteknologioita ei vielä tunneta. Jo tehtyjä arkkitehtonisia ratkaisuja on järkevä muuttaa, jos ajan myötä huomataan että aiemmin tehdyt valinnat eivät tue parhaalla tavalla ohjelmiston kehittämistä.
Eli kuten vaatimusmäärittelyn suhteen, myös arkkitehtuurin suunnittelussa ketterät menetelmät pyrkivät välttämään liian aikaisin tehtävää ja myöhemmin todennäköisesti turhaksi osoittautuvaa työtä.
Inkrementaalisen arkkitehtuurin riskit
Inkrementaalinen lähestymistapa arkkitehtuurin muodostamiseen edellyttää koodilta hyvää sisäistä laatua ja kehitystiimiltä suurta kurinalaisuutta.
Martin Fowler toteaa seuraavasti
Essentially, incremental design means that the design of the system grows as the system is implemented. Design is part of the programming processes and as the program evolves the design changes.
In its common usage, incremental design is a disaster. The design ends up being the aggregation of a bunch of ad-hoc tactical decisions, each of which makes the code harder to alter.
Fowlerin havaintojen mukaan inkrementaalisen arkkitehtuurin ja suunnittelun ihanne toteutuu vain harvoin, useimmiten sovelluskehittäjien huolimattomuus, aikataulupaineet ym. syyt johtavat siihen, että ohjelmiston sisäinen laatu alkaa ajan myötä heikentyä ja lopulta ohjelmisto on muodoton kasa spagettikoodia, eli big ball of mud jonka ylläpitäminen ja jatkokehittäminen muuttuu erittäin haastavaksi.
Olio- ja komponenttisuunnittelu
Sovelluksen arkkitehtuuri siis antaa raamit, jotka ohjaavat sovelluksen tarkempaa suunnittelua ja toteuttamista. Tätä tarkemman tason suunnittelua kutsutaan olio- tai komponenttisuunnitteluksi ja sen tarkoituksena on tarkentaa arkkitehtuuristen komponenttien väliset rajapinnat sekä hahmotella ohjelman tarkempi luokka- tai moduulirakenne.
Vesiputousmaisessa työskentelyssä komponenttisuunnittelu saattaa olla dokumentoitu hyvinkin tarkkaan esim. UML:n luokka- ja sekvenssikaavioita hyväksikäyttäen. Erityisesti ketterässä ohjelmistotuotannossa tarkka suunnittelu tapahtuu kuitenkin yleensä vasta ohjelmoitaessa.
Ohjelmiston suunnittelussa pyritään ennen kaikkia maksimoimaan koodin sisäinen laatu, eli pitämään sovellus rakenteeltaan helposti ylläpidettävänä ja laajennettavana.
Ylläpidettävyyden ja laajennettavuuden kannalta tärkeitä seikkoja ovat mm. seuraavat
- Koodin tulee olla luettavuudeltaan selkeää, ja sen tulee kertoa esim. nimeämisellä mahdollisimman selkeästi mitä koodi tekee, ja tuoda esiin koodin alla oleva “design”
- Yhtä paikkaa pitää pystyä muuttamaan siten, ettei muutoksesta aiheudu sivuvaikutuksia sellaisiin kohtiin koodia, jota muutoksen tekijä ei pysty ennakoimaan
- Jos ohjelmaan tulee tehdä laajennus tai bugikorjaus, tulee olla helposti selvitettävissä mihin kohtaan koodia muutos tulee tehdä
- Jos ohjelmasta muutetaan “yhtä asiaa”, tulee kaikkien muutosten tapahtua vain yhteen kohtaan koodia (metodiin, luokkaan tai komponenttiin)
- Muutosten ja laajennusten jälkeen tulee olla helposti tarkastettavissa ettei muutos aiheuta sivuvaikutuksia muualle järjestelmään
Ohjelmistoalalle vuosien varrella kerääntyneen kansanviisauden mukaan ylläpidettävyyden ja laajennettavuuden kannalta hyvällä koodilla on joukko yhteneviä ominaisuuksia, tai laatuattribuutteja, joita ovat esim. seuraavat:
- Kapselointi
- Korkea koheesion aste
- Riippuvuuksien vähäisyys
- Toisteettomuus
- Testattavuus
- Selkeys
Tutustutaan nyt näihin laatuattribuutteihin sekä periaatteisiin ja suunnitteluratkaisuihin, joita noudattamalla on mahdollista kirjoittaa ylläpidettävyydeltään laadukasta koodia. Monet näistä hyvän suunnittelun periaatteista on nimetty ja dokumentoitu suunnittelumalleina (engl. design patterns).
Olemme jo nähneet kurssin aikana muutamia suunnittelumalleja, ainakin seuraavat: dependency injection eli riippuvuuksien injektointi, sekä repository. Suurin osa tällä kurssilla käsiteltävistä suunnittelumalleista on syntynyt olio-ohjelmoinnin parissa. Osa suunnittelumalleista on relevantteja myös muita paradigmoja, kuten funktionaalista ohjelmointia käytettäessä. Muilla paradigmoilla on myös omia suunnittelumalleja, mutta niitä emme kurssilla käsittele.
Kapselointi
Ohjelmoinnin jatkokurssilla kapselointi (engl. encapsulation) määritellään seuraavasti:
Luokka voi piilottaa attribuutit asiakkailta. Pythonissa tämä tapahtuu lisäämällä attribuuttimuuttujan nimen alkuun kaksi alaviivaa. Tietojen piilottamista asiakkaalta kutsutaan kapseloinniksi. Nimensä mukaisesti attribuutti siis “suljetaan kapseliin” ja asiakkaalle tarjotaan sopiva rajapinta, jonka kautta tietoa voi käsitellä.
Aloitteleva ohjelmoija assosioi kapseloinnin usein juuri siihen että olion attribuutit määritellään piilotetuiksi ja niille tehdään tarvittaessa aksessorimetodit. Tämä on kuitenkin melko kapea näkökulma kapselointiin. Olion sisäisen tilan lisäksi kapseloinnin kohde voi olla mm. käytettävän olion tyyppi, käytetty algoritmi, olioiden luomisen tapa, käytettävän komponentin rakenne, jne…
Monissa suunnittelumalleissa on kyse juuri eritasoisten asioiden kapseloinnista, ja tulemme pian näkemään esimerkkejä asiasta.
Pyrkimys kapselointiin näkyy myös ohjelmiston arkkitehtuurin tasolla. Esimerkiksi kerrosarkkitehtuurissa ylempi kerros käyttää ainoastaan alapuolellaan olevan kerroksen ulospäin tarjoamaa rajapintaa, kaikki muu on kapseloitu näkymättömiin. Vastaavasti mikropalveluarkkitehtuureissa yksittäinen palvelu kapseloi toiminnallisuutensa sisäisen logiikan ja tarjoaa ulospäin ainoastaan verkon välityksellä käytettävän rajapinnan.
Koheesio
Koheesiolla (engl. cohesion) tarkoitetaan sitä, kuinka pitkälle metodissa, luokassa tai komponentissa oleva ohjelmakoodi keskittyy tietyn yksittäisen toiminnallisuuden toteuttamiseen. Hyvänä asiana pidetään mahdollisimman korkeaa koheesion astetta.
Koheesioon tulee siis pyrkiä kaikilla ohjelman tasoilla, metodeissa, luokissa ja komponenteissa.
Koheesio metoditasolla
Tarkastellaan esimerkkinä tietokannasta tietoa hakevaa metodia. Metodin koodi näyttää seuraavalta:
# SQL_SELECT_PARTS on vakio, joka sisältää SQL-kyselyn
def populate(self):
connection = sqlite3.connect(DATABASE_FILE_PATH)
connection.row_factory = sqlite3.Row
cursor = connection.cursor()
cursor.execute(SQL_SELECT_PARTS)
rows = cursor.fetchall()
parts = []
for row in rows:
parts.append(Part(row["name"], row["brand"], row["retail_price"]))
connection.close()
return parts
Metodissa tehdään montaa asiaa:
- Luodaan yhteys tietokantaan
- Tehdään tietokantakysely
- Käydään kyselyn tulosrivit läpi ja luodaan jokaista tulosriviä kohti
Part-olio - Suljetaan yhteys
Metodi toimii myös monella erilaisella abstraktiotasolla. Toisaalta käsitellään teknisiä tietokantatason asioita kuten tietokantayhteyden avaamista ja kyselyn tekemistä, toisaalta sovelluslogiikan tasolla mielekkäitä Part-olioita.
Metodin koheesion taso on siis erittäin huono.
Metodi on helppo refaktoroida pilkkomalla se pienempiin osiin, joiden kutsumista alkuperäinen metodi koordinoi.
def populate(self):
connection = self.get_database_connection()
rows = self.get_rows(connection)
parts = self.get_parts_by_rows(rows)
connection.close()
return parts
def get_database_connection(self):
connection = sqlite3.connect(DATABASE_FILE_PATH)
connection.row_factory = sqlite3.Row
return connection
def get_rows(self, connection):
cursor = connection.cursor()
cursor.execute(SQL_SELECT_PARTS)
return cursor.fetchall()
def get_parts_by_rows(self, rows):
parts = []
for row in rows:
parts.append(Part(row["name"], row["brand"], row["retail_price"]))
return parts
Yksittäiset metodit ovat nyt kaikki samalla abstraktiotasolla toimivia ja kuvaavasti nimettyjä.
Koheesio luokkatasolla
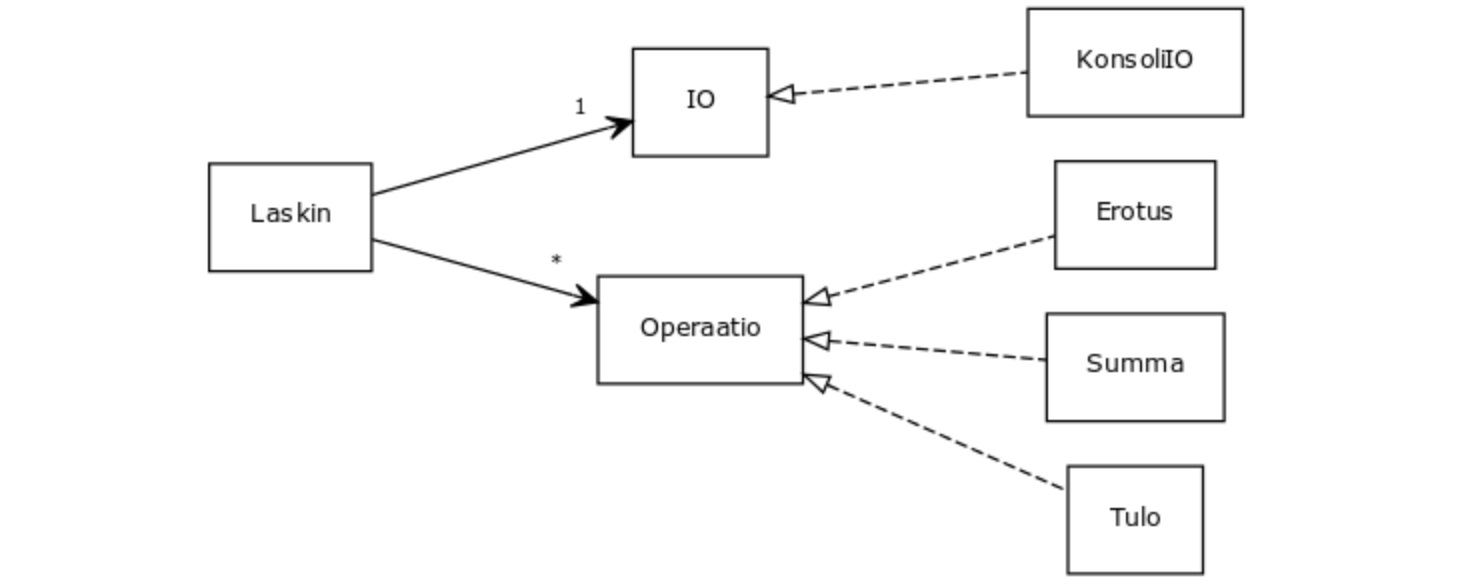
Luokkatason koheesiossa pyrkimyksenä on, että luokan vastuulla on vain yksi asia, tämä tunnetaan myös nimellä single responsibility -periaate (SRP). Robert Martin määrittelee, että luokalla on yksi vastuu jos sillä on vain yksi syy muuttua.
Kurssin ensimmäisissä laskareissa tarkasteltiin yksinkertaista laskinta:
class Laskin:
def __init__(self):
self.lue = input
self.kirjoita = print
def suorita(self):
while True:
luku1 = int(self.lue("Luku 1:"))
if luku1 == -9999:
return
luku2 = int(self.lue("Luku 2:"))
if luku2 == -9999:
return
vastaus = self.laske_summa(luku1, luku2)
self.kirjoita(f"Summa: {vastaus}")
def laske_summa(self, luku1, luku2):
return luku1 + luku2
Luokka rikkoo single responsibility -periaatetta. Miksi? Periaate sanoo, että luokalla saa olla vain yksi vastuu eli syy muuttua. Nyt luokalla on kuitenkin useita syitä muuttua:
- Luokalle halutaan toteuttaa uusia laskutoimituksia
- Kommunikointi käyttäjän kanssa halutaan hoitaa jotenkin muuten kuin konsolin välityksellä
Käyttäjän kanssa kommunikointi voidaan eriyttää omaan luokkaansa, jonka olio io injektoidaan laskimelle konstruktorin parametrina. Näin saadaan vähennettyä Laskin-luokan vastuita:
class Laskin:
def __init__(self, io):
self.io = io
def suorita(self):
while True:
luku1 = int(self.io.lue("Luku 1:"))
if luku1 == -9999:
return
luku2 = int(self.io.lue("Luku 2:"))
if luku2 == -9999:
return
vastaus = self.laske_summa(luku1, luku2)
self.io.kirjoita(f"Summa: {vastaus}")
def laske_summa(self, luku1, luku2):
return luku1 + luku2
Nyt kommunikointitavan muutos ei edellytä luokkaan Laskin mitään muutoksia edellyttäen, että uusi kommunikointitapa toteuttaa saman metodirajapinnan, jonka kautta Laskin-luokka hoitaa kommunikoinnin, eli metodit lue- ja kirjoita.
Vaikka luokka Laskin siis toteuttaakin edelleen käyttäjänsä näkökulmasta samat asiat kuin aiemmin, ei se hoida kaikkea itse vaan delegoi osan vastuistaan muualle.
Kommunikointi voidaan toteuttaa esim. seuraavasti:
class KonsoliIO:
def lue(self, teksti):
return input(teksti)
def kirjoita(self, teksti):
print(teksti)
Laskin konfiguroidaan injektoimalla siihen olio, joka toteuttaa lue- ja kirjoita-metodit. Injektointi tapahtuu konstruktorin parametrin kautta:
def main():
io = KonsoliIO()
laskin = Laskin(io)
laskin.suorita()
Testausta varten voidaan toteuttaa stub eli valekomponentti, jonka avulla testi voi hallita “käyttäjän” syötteitä ja lukea ohjelman tulostukset:
class StubIO:
def __init__(self, inputs):
self.inputs = inputs
self.outputs = []
def lue(self, teksti):
return self.inputs.pop(0)
def kirjoita(self, teksti):
self.outputs.append(teksti)
Parannellun laskimen rakenne luokkakaaviona:

Luokka ei ole vielä kaikin osin laajennettavuuden kannalta optimaalinen. Palaamme asiaan hetken kuluttua.
Koheesio komponenttitasolla
Koheesio ja single responsibility -periaate eivät ole pelkästään olio-ohjelmointiin liittyviä käsitteitä vaan universaaleja hyvän koodin periaatteita. Jos ajatellaan kurssilla Full stack -websovelluskehitys käytettävää React-kirjastoa, on siinäkin periaatteena koostaa käyttöliittymä pienistä komponenteista, joista kukin keskittyy yhteen asiaan, esim. yksittäisen napin HTML-koodin renderöintiin. Web-sovelluksen tilan käsittely taas pyritään kapseloimaan Redux-storeen, jonka ainoa vastuu on tilasta ja sen muutoksista huolehtiminen.
Koheesion periaate näkyy myös sovelluksen arkkitehtuurien tasolla. Kerrosarkkitehtuurissa kukin sovelluksen kerros keskittyy oman abstraktiotason asioihin, esim. sovelluslogiikka ei ota kantaa käyttöliittymään tai tiedon tallentamisen tapaan. Mikropalveluarkkitehtuureissa koheesio taas näkyy hieman eri tavalla, yksittäinen mikropalvelu keskittyy toteuttamaan yksittäisen liiketoiminnan tason toiminnallisuuden, esim. verkkokaupan suosittelualgoritmin tai laskutuksen.
Riippuvuuksien vähäisyys
Single responsibility -periaatteen hengessä tehty ohjelma koostuu suuresta määrästä oliota/komponentteja, joilla on suuri määrä pieniä metodeja.
Olioiden on oltava vuorovaikutuksessa toistensa kanssa saadakseen toteutettua ohjelman toiminnallisuuden. Riippuvuuksien vähäisyyden (engl. low coupling) periaate pyrkii eliminoimaan luokkien ja olioiden välisiä riippuvuuksia.
Koska korkean koheesion periaatteen nojalla olioita on paljon, tulee riippuvuuksia pakostakin. Miten riippuvuudet sitten saadaan eliminoitua? Ideana on eliminoida tarpeettomat riippuvuudet ja välttää riippuvuuksia konkreettisiin asioihin.
Riippuvuuden kannattaa kohdistua asiaan, joka ei muutu herkästi, eli rajapintaan. Sama idea kulkee parilla eri nimellä:
- Program to an interface, not to an implementation
- Depend on abstractions, not on concrete implementation
Toisin kuin Javassa ja monessa muussa stattisesti tyypitetyssä kielessä, ei Pythonissa ole selkeää rajapinnan käsitettä. Sama ajattelu voidaan laajentaa myös Pythoniin, olettamalla että rajapinnalla tarkoitetaan ainoastaan tietoa siitä minkälaisia metodeja riippuvuutena käytettävällä luokalla on.
Konkreettisen riippuvuuden eliminointi onnistuu antamalla oliolle riippuvuuksien toteutukset esimerkiksi konstruktorin, tai metodikutsun kautta. Olemme tehneet näin kurssilla usein, mm. Verkkokaupan konkreettiset riippuvuudet Varastoon, Pankkiin ja Viitegeneraattoriin korvattiin luokan konstruktorin kautta annetuilla olioilla. Riippuvuuksien injektointi -suunnittelumalli toimi usein apuvälineenä konkreettisen riippuvuuksien eliminoinnissa.
Osa luokkien välisistä riippuvuuksista on tarpeettomia ja ne kannattaa eliminoida muuttamalla luokan vastuita.
Favour composition over inheritance eli milloin ei kannata periä [viikko 6]
Perintä muodostaa riippuvuuden perivän ja perittävän luokan välille, ja tämä voi jossain tapauksissa olla ongelmallista. Eräs oliosuunnittelun kulmakivi onkin periaate Favour composition over inheritance eli suosi yhteistoiminnassa toimivia oliota perinnän sijaan.
Tarkastellaan tilannetta havainnollistavaa esimerkkiä.
Käytössämme luokka, joka mallintaa pankkitiliä:
class Tili:
def __init__(self, tilinumero, omistaja, korkoprosentti):
self.tilinumero = tilinumero
self.omistaja = omistaja
self.korkoprosentti = korkoprosentti
self.saldo = 0
def siirra_rahaa_tililta(self, tilille, summa):
if self.saldo < summa:
return False
self.saldo = self.saldo - summa
tilille.saldo = tilille.saldo + summa
return True
def maksa_korko(self):
self.saldo = self.saldo * (1 + self.korkoprosentti)
Asiakkaan vaatimukset muuttuvat ja tulee tarve tilille, jonka korko perustuu joko 1, 3, 6 tai 12 kuukauden Euribor-korkoon. Päätämme tehdä uuden luokan EuriborTili perimällä luokan Tili ja ylikirjoittamalla metodin maksa_korko siten, että Euribor-koron senhetkinen arvo haetaan verkosta:
class EuriborTili(Tili):
def __init__(self, tilinumero, omistaja, kuukauden):
super().__init__(tilinumero, omistaja, 0)
self.kuukauden = kuukauden
def get_korko(self):
data = urllib.request.urlopen(
"https://www.euribor-rates.eu/en/current-euribor-rates/"
).read()
rivi_pattern = re.compile(r"Euribor " + str(self.kuukauden) + " months[^%]+%")
rivi_match = rivi_pattern.search(str(data))
if rivi_match is None:
return 0
sarake_pattern = re.compile(r"\-?([0-9]|\.)+ %")
sarake_match = sarake_pattern.search(rivi_match.group(0))
if sarake_match is None:
return 0
return float(sarake_match.group(0).replace("%", "").strip())
def maksa_korko(self):
self.saldo = self.saldo * (1 + self.get_korko())
Huomaamme, että EuriborTili-luokka rikkoo single responsibility -periaatetta, sillä luokka sisältää normaalin tiliin liittyvän toiminnan lisäksi koodia, joka hakee tietoa internetistä. Vastuut kannattaa selkeyttää ja korkoprosentin haku eriyttää omaan rajapinnan takana olevaan luokkaan:
class EuriborLukija:
def __init__(self, kuukauden):
self.kuukauden = kuukauden
def get_korko(self):
data = urllib.request.urlopen(
"https://www.euribor-rates.eu/en/current-euribor-rates/"
).read()
rivi_pattern = re.compile(r"Euribor " + str(self.kuukauden) + " months[^%]+%")
rivi_match = rivi_pattern.search(str(data))
if rivi_match is None:
return 0
sarake_pattern = re.compile(r"\-?([0-9]|\.)+ %")
sarake_match = sarake_pattern.search(rivi_match.group(0))
if sarake_match is None:
return 0
return float(sarake_match.group(0).replace("%", "").strip())
class EuriborTili(Tili):
def __init__(self, tilinumero, omistaja, kuukauden):
super().__init__(tilinumero, omistaja, 0)
self.euribor = EuriborLukija(kuukauden)
def maksa_korko(self):
self.saldo = self.saldo * (1 + self.euribor.get_korko())
EuriborTili-luokka alkaa olla nyt melko siisti, EuriborLukija-luokassa olisi paljon parantemisen varaa, mm. sen ainoan metodin koheesio on huono: metodi tekee aivan liian montaa asiaa.
Seuraavaksi huomaamme, että on tarvetta määräaikaistilille, joka on muuten samanlainen kuin Tili, mutta määräaikaistililtä ei voi siirtää rahaa muualle ennen kuin se on tehty tietyn ajan kuluttua mahdolliseksi. Perimme jälleen luokan Tili:
class MaaraaikaisTili(Tili):
def __init__(self, tilinumero, omistaja, korkoprosentti):
super().__init__(tilinumero, omistaja, korkoprosentti)
self.nostokielto = True
def salli_nosto():
self.nostokielto = False
def siirra_rahaa_tililta(self, tilille, summa):
if nostokielto:
return False
return super().siirra_rahaa_tililta(tilille, summa)
Ohjelman rakenne näyttää tässä vaiheessa seuraavalta:

Seuraavaksi tulee idea Euribor-korkoa käyttävistä määräaikaistileistä. Miten nyt kannattaisi tehdä? Osa toiminnallisuudesta on luokassa MaaraaikaisTili ja osa luokassa EuriborTili…
Koronmaksun hoitaminen perinnän avulla ei ollutkaan paras ratkaisu, parempi on noudattaa favor composition over inheritance -periaatetta. Eli erotetaan koronmaksu omiksi luokikseen, jotka toteuttavat metodin get_korko:
class TasaKorko:
def __init__(self, korko):
self.korko = korko
def get_korko(self):
return self.korko
class EuriborKorko:
def __init__(self, kuukausi):
self.lukija = EuriborLukija(kuukausi)
def get_korko(self):
return self.lukija.get_korko()
Tarve erilliselle EuriborTili-luokalle katoaa, ja pelkkä Tili hieman muutetussa muodossa riittää:
class Tili:
def __init__(self, tilinumero, omistaja, korko):
self.tilinumero = tilinumero
self.omistaja = omistaja
self.korko = korko
self.saldo = 0
def siirra_rahaa_tililta(self, tilille, summa):
if self.saldo < summa:
return False
self.saldo = self.saldo - summa
tilille.saldo = tilille.saldo + summa
return True
def maksa_korko(self):
self.saldo = self.saldo * (1 + self.korko.get_korko())
Erilaisia tilejä luodaan seuraavasti:
normaali = Tili("1234-1234", "Jami Kousa", Tasakorko(0.04))
euribor12 = Tili("4422-3355", "Lea Kutvonen", EuriborKorko(12))
Ohjelman rakenne on nyt seuraava:

Muutetaan luokkaa Tili vielä siten, että tilejä voidaan luoda ilman konstruktoria:
class Tili:
def __init__(self, tilinumero, omistaja, korko):
self.tilinumero = tilinumero
self.omistaja = omistaja
self.korko = korko
self.saldo = 0
@staticmethod
def luo_euribor_tili(tilinumero, omistaja, kuukausia):
return Tili(tilinumero, omistaja, EuriborKorko(kuukausia))
@staticmethod
def luo_maaraaikais_tili(tilinumero, omistaja, korko):
return MaaraaikaisTili(tilinumero, omistaja, Tasakorko(korko))
@staticmethod
def luo_kaytto_tili(tilinumero, omistaja, korko):
return Tili(tilinumero, omistaja, Tasakorko(korko))
def vaihda_korkoa(self, korko):
self.korko = korko
# ...
Lisäsimme luokalle kolme staattista apumetodia helpottamaan tilien luomista. Tilejä voidaan nyt luoda seuraavasti:
maaraaikais = Tili.luo_maaraaikais_tili("1234-1234", "Jami Kousa", 0.025)
euribor12 = Tili.luo_euribor_tili("4422-3355", "Lea Kutvonen", 12)
fyrkka = Tili.luo_euribor_tili("7895-4571", "Indre Zliobaite", 1)
Suunnittelumalli: static factory method [viikko 6]
Käyttämämme periaate olioiden luomiseen staattisten metodien avulla on hyvin tunnettu suunnittelumalli staattinen tehdasmetodi (engl. static factory method).
Tili-esimerkissä käytetty static factory method on yksinkertaisin monista tehdas-suunnittelumallin varianteista. Periaatteena suunnittelumallissa on se, että luokalle tehdään staattinen tehdasmetodi tai metodeja, jotka käyttävät konstruktoria ja luovat luokan ilmentymät.
Tehdasmetodin avulla voidaan piilottaa olion luomiseen liittyviä yksityiskohtia, esimerkissä korko-olioiden luominen ja jopa olemassaolo oli tehdasmetodin avulla piilotettu tilin käyttäjältä.
Tehdasmetodin avulla voidaan myös piilottaa käyttäjältä luodun olion todellinen luokka, esimerkissä näin tehtiin määräaikaistilin suhteen.
Tehdasmetodi siis auttaa kapseloinnissa, olion luomiseen liittyvät detaljit ja jopa olion todellinen luonne piiloutuu olion käyttäjältä. Tämä taas mahdollistaa erittäin joustavan laajennettavuuden.
Staattinen tehdasmetodi ei ole testauksen kannalta erityisen hyvä ratkaisu, esimerkissämme olisi vaikea luoda tili, jolle annetaan korko-olion sijaan mock-olio. Nyt se tosin onnistuu koska konstruktoria ei ole täysin piilotettu.
Lisätietoa factory-suunnittelumallista esim. täältä ja täältä.
Tehdasmetodien avulla voimme siis kapseloida luokan todellisen tyypin. Jamin tilihän on määräaikaistili, se kuitenkin pyydetään Tili-luokassa sijaitsevalta tehdasmetodilta, olion oikea tyyppi on piilotettu tarkoituksella käyttäjältä. Määräaikaistilin käyttäjällä ei siis ole enää konkreettista riippuvuutta luokkaan MaaraaikaisTili.
Teimme myös metodin jonka avulla tilin korkoa voi muuttaa. Jamin tasakorkoinen määräaikaistili on helppo muuttaa lennossa kolmen kuukauden Euribor-tiliksi:
maaraaikais.vaihda_korkoa(EuriborKorko(3))
Eli luopumalla perinnästä oliorakenne selkeytyy huomattavasti ja saavutetaan suoritusaikaista joustavuutta (koronlaskutapa), joka perintää käyttämällä ei onnistu.
Suunnittelumalli: strategy [viikko 6]
Tekniikka, jolla koronmaksu hoidetaan on myöskin suunnittelumalli, nimeltään strategia (engl. strategy).
Strategyn avulla voidaan hoitaa tilanne, jossa eri olioiden käyttäytyminen on muuten sama, mutta tietyissä kohdissa on käytössä eri “algoritmi”. Esimerkissämme tämä algoritmi oli korkoprosentin määrittely. Sama tilanne voidaan hoitaa usein myös perinnän avulla käyttämättä erillisiä olioita, strategy kuitenkin mahdollistaa huomattavasti dynaamisemman ratkaisun, sillä strategia-olioa on mahdollista vaihtaa ajoaikana. Strategyn käyttö ilmentää hienosti “favour composition over inheritance”-periaatetta
Lisätietoa strategia-suunnittelumallista täällä ja täällä.
Vastuiden eriyttäminen: tilin luominen pankissa [viikko 6]
Loimme äsken luokalle Tili staattiset apumetodit tilien luomista varten. Voisi kuitenkin olla järkevämpää siirtää vastuu tilien luomisesta erillisen luokan, Pankki vastuulle. Pankki voi helposti hallinnoida myös tilinumeroiden generointia:
class Pankki:
def __init__(self):
self.numero = 0
def generoi_tilinumero(self):
self.numero = self.numero + 1
return f"12345-{self.numero}"
def kayttotili(self, omistaja, korko):
return Tili(self.generoi_tilinumero(), omistaja, Tasakorko(korko))
def maaraaikaistili(self, omistaja, korko):
return MaaraaikaisTili(self.generoi_tilinumero(), omistaja, Tasakorko(korko))
def euribortili(self, omistaja, kuukauden):
return Tili(self.generoi_tilinumero(), omistaja, EriborKorko(kuukauden))
def maaraaikais_euribortili(self, omistaja, kuukauden):
return MaaraaikaisTili(self.generoi_tilinumero(), omistaja, EuriborKorko(kuukauden))
Tilejä luodaan pankin avulla seuraavasti:
spankki = Pankki()
euriborTili = spankki.euribortili("Lea Kutvonen", 6)
maaraaikaistili = spankki.maaraaikaistili("Arto Hellas", 0.15)
Eli tilin luojan ei enää tarvitse huolehtia tilinumeroiden generoinnista.
Jokaisesta tehdasmetodista on siis tehty luokan oman staattisen metodin sijaan toiseen luokkaan sijoitettu oliometodi.
Luokkien vastuut ovat selkeytyneet, Tili vastaa yhteen tiliin liittyvistä asioista, kuten saldosta. Tili myös tuntee olion, jonka hallinnassa on tieto tiliin liittyvästä korosta. Pankki taas hallinnoi kaikkia tilejään, sen avulla myös generoidaan tilinumerot tilien luomisen yhteydessä.
Toiminnallisuuden kapselointi: laskin ja strategia [viikko 6]
Olemme laajentaneet Laskin-luokkaa osaamaan myös muita laskuoperaatioita:
class Laskin:
def __init__(self, io):
self.io = io
def suorita(self):
while True:
komento = self.io.lue("Komento:")
if komento == "lopetus":
return
luku1 = int(self.io.lue("Luku 1:"))
luku2 = int(self.io.lue("Luku 2:"))
vastaus = 0
if komento == "summa":
vastaus = self.laske_summa(luku1, luku2)
elif komento == "tulo":
vastaus = self.laske_tulo(luku1, luku2)
elif komento == "erotus":
vastaus = self.laske_erotus()
self.io.kirjoita(f"Tulos: {vastaus}")
def laske_summa(self, luku1, luku2):
return luku1 + luku2
def laske_tulo(self, luku1, luku2):
return luku1 * luku2
def laske_erotus(self, luku1, luku2):
return luku1 - luku2
Ratkaisu ei ole kaikin puolin tyydyttävä. Entä jos haluamme muitakin operaatioita kuin summan, tulon ja erotuksen? If-hässäkkä tulee kasvamaan.
Päätämme siirtyä strategia-suunnittelumallin käyttöön, eli hoidetaan laskuoperaatio omassa luokassaan. Toteutetaan luokka Operaatiotehdas, jolla on staattinen tehdasmetodi luo:
class Operaatiotehdas:
@staticmethod
def luo(operaatio):
if operaatio == "summa":
return Summa()
elif operaatio == "tulo":
return Tulo()
return Erotus()
Staattisen tehdasmetodin luo avulla voidaan luoda laskuoperaatioita vastaavia olioita. Laskuoperaatioista vastaavien luokkien tulee toteuttaa metodi laske, jolla kaksi parametria. Laskuoperaatioita vastaavat luokat on määritelty seuraavasti:
class Summa:
def laske(self, luku1, luku2):
return luku1 + luku2
class Tulo:
def laske(self, luku1, luku2):
return luku1 * luku2
class Erotus:
def laske(self, luku1, luku2):
return luku1 - luku2
Laskin-luokka yksinkertaistuu huomattavasti:
class Laskin:
def __init__(self, io):
self.io = io
def suorita(self):
while True:
komento = self.io.lue("Komento:")
if komento == "lopetus":
return
luku1 = int(self.io.lue("Luku 1:"))
luku2 = int(self.io.lue("Luku 2:"))
operaatio = Operaatiotehdas.luo(komento)
self.io.kirjoita(f"Tulos: {operaatio.laske(luku1, luku2)}")
Hienona puolena laskimessa on nyt se, että voimme lisätä operaatioita ja luokkaa Laskin ei tarvitse muuttaa millään tavalla, ainoa muutosta edellyttävä kohta olemassaolevassa koodissa on luokan Operaatiotehdas metodi luo.
Sovelluksen rakenne näyttää seuraavalta:
Laskin ja komento-olio [viikko 6]
Entä jos haluamme laskimelle muunkinlaisia, kuin 2 parametria ottavia operaatioita, esim. neliöjuuren? Muutetaan laskuoperaatiot toteuttavien luokkien olemusta siten, että siirretään myös käyttäjän kanssa tapahtuva kommunikointi niiden huolehdittavaksi.
Tämän muutoksen myötä siirrymme käyttämään Strategy-suunnittelumallin lähisukulaista command-suunnittelumallia. Komennon toteuttavat luokat ovat äärimmäisen yksinkertaisia. Niille annetaan konstruktorin kautta IO-olio, ja ne toteuttavat metodin suorita. Komennon voi ainoastaan suorittaa eikä se edes palauta mitään!
Erillisten komento-olioiden luominen siirretään uudelle luokalle Komentotehdas:
class Komentotehdas:
def __init__(self, io):
self.io = io
def hae(self, komento):
if komento == "summa":
return Summa(self.io)
elif komento == "tulo":
return Tulo(self.io)
elif komento == "nelio":
return Nelio(self.io)
elif komento == "lopeta":
return Lopeta(self.io)
return Tuntematon(self.io)
Komentotehdas palauttaa hae-metodilla merkkijonoparametria vastaavan komento-olion. Koska vastuu käyttäjän kanssa kommunikoinnista on siirretty Komento-olioille, annetaan niille IO-olio konstruktorin parametrina.
If-hässäkkä näyttää hieman ikävältä. Siitä pääsee kuitenkin helposti eroon tallentamalla erilliset komennon dictionaryyn:
class Komentotehdas:
def __init__(self, io):
self.io = io
self.komennot = {
"summa": Summa(self.io),
"tulo": Tulo(self.io),
"nelio": Nelio(self.io),
"lopeta": Lopeta(self.io)
}
def hae(self, komento):
if komento in self.komennot:
return self.komennot[komento]
return Tuntematon(self.io)
Yksittäiset komennot ovat erittäin yksinkertaisia:
class Summa:
def __init__(self, io):
self.io = io
def suorita(self):
luku1 = int(self.io.lue("Luku 1:"))
luku2 = int(self.io.lue("Luku 2:"))
self.io.kirjoita(f"Vastaus: {luku1 + luku2}")
class Nelio:
def __init__(self, io):
self.io = io
def suorita(self):
luku = int(self.io.lue("Luku 1:"))
self.io.kirjoita(f"Vastaus: {luku * luku}")
class Tuntematon:
def __init__(self, io):
self.io = io
def suorita(self):
self.io.kirjoita("Sallitut komennot: summa, tulo, nelio, lopeta")
class Lopeta:
def __init__(self, io):
self.io = io
def suorita(self):
self.io.kirjoita("Kiitos ja näkemiin!")
sys.exit(0)
Luokka Laskin yksinkertaistuu entisestään, se ei tee enää juuri mitään muuta kuin luo komentotehtaan sekä sisältää ikuisen loopin, minkä sisällä käyttäjän syötettä vastaavia komentoja suoritetaan:
class Laskin:
def __init__(self, io):
self.io = io
self.komennot = Komentotehdas(io)
def suorita(self):
while True:
komento = self.io.lue("Komento:")
self.komennot.hae(komento).suorita()
Ohjelman rakenne tässä vaiheessa:
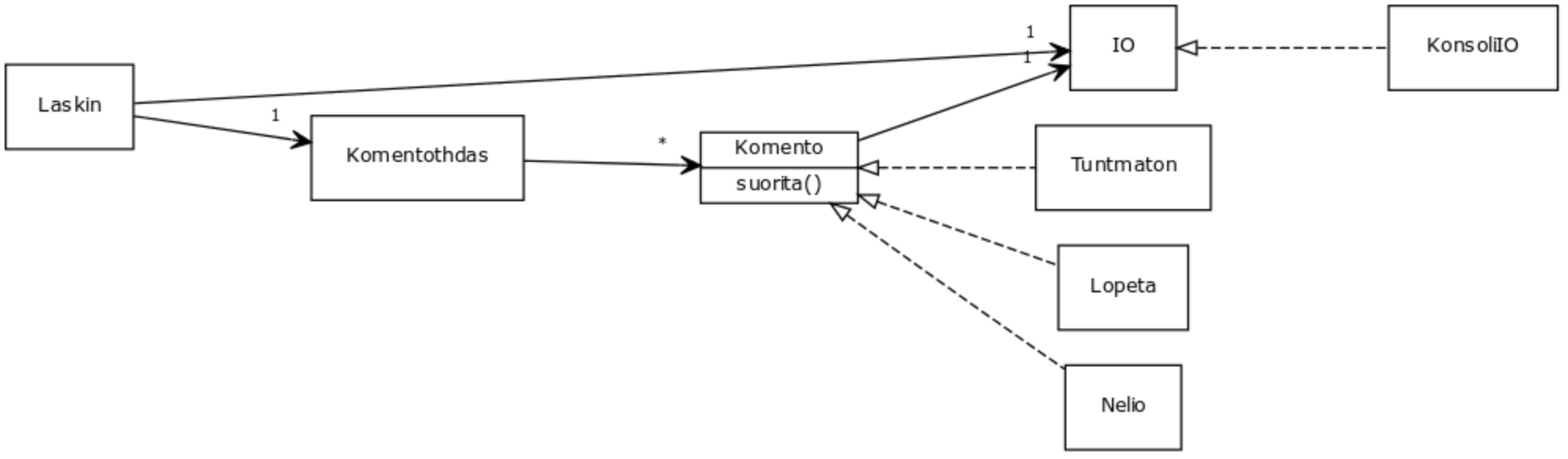
Suunnittelumalli: command [viikko 6]
Eristimme siis jokaiseen erilliseen laskuoperaatioon liittyvän toiminnallisuuden omaksi oliokseen command-suunnittelumallin ideaa noudattaen, eli siten, että kaikki operaatiot toteuttavat yksinkertaisen rajapinnan, jolla on ainoastaan metodi suorita.
Ohjelman edellisessä versiossa sovelsimme strategia-suunnittelumallia, missä erilliset laskuoperaatiot oli toteutettu omina olioinaan. Command-suunnittelumalli eroaa siinä, että olemme nyt kapseloineet koko komennon suorituksen, myös käyttäjän kanssa käytävän kommunikoinnin omiin olioihin. Komento-olioiden rajapinta on yksinkertainen, niillä on ainoastaan yksi metodi, suorita. Strategia-suunnittelumallissa taas strategia-olioiden rajapinta vaihtelee tilanteen mukaan.
Esimerkissä komennot luotiin tehdasmetodin tarjoavan olion avulla, if:it piilotettiin tehtaan sisälle. Komento-olioiden suorita-metodi suoritettiin esimerkissä välittömästi, näin ei välttämättä ole, komentoja voitaisiin laittaa esim. jonoon ja suorittaa myöhemmin.
Lisää command-suunnittelumallista esim. täällä ja täällä.
Yhteisen koodin eriyttäminen yliluokkaan [viikko 6]
Koska kaksi parametria käyttäjältä kysyvillä komennoilla, kuten summa, tulo ja erotus on paljon yhteistä, luodaan niitä varten abstrakti yliluokka (eli luokka mikä on ainoastaan perintää varten tehty, luokasta itsestään ei voi tehdä olioita):
from abc import ABC, abstractmethod
class BinaariOperaatio(ABC):
def __init__(self, io):
self.io = io
self.luku1 = 0
self.luku2 = 0
def suorita(self):
self.luku1 = int(self.io.lue("Luku 1:"))
self.luku2 = int(self.io.lue("Luku 2:"))
tulos = self.laske()
self.io.kirjoita(f"Vastaus: {tulos}")
@abstractmethod
def laske(self):
pass
Summaa ja tuloa vastaavat komennot yksinkertaistuvat entisestään:
class Summa(BinaariOperaatio):
def __init__(self, io):
super().__init__(io)
def laske(self):
return self.luku1 + self.luku2
class Tulo(BinaariOperaatio):
def __init__(self, io):
super().__init__(io)
def laske(self):
return self.luku1 * self.luku2
Jos sovellukseen haluttaisiin toteuttaa lisää kaksiparametrisia operaatioita, esimerkiksi erotus, riittäisi erittäin yksinkertainen lisäys:
class Erotus(BinaariOperaatio):
def __init__(self, io):
super().__init__(io)
def laske(self):
return self.luku1 - self.luku2
Ja mikä parasta, ainoa muu luokka, jota on koskettava on komentoja luova Komentotehdas-luokka.
Ohjelmasta on näin ollen saatu laajennettavuuden kannalta varsin joustava. Uusia operaatioita on helppo lisätä ja lisäys ei aiheuta muutoksia moneen kohtaan koodia. Laskin-luokallahan ei ole riippuvuuksia muualle kuin Komentotehdas-luokkaan sekä konstruktorin kautta injektoituun KonsoliIO-luokkaan.
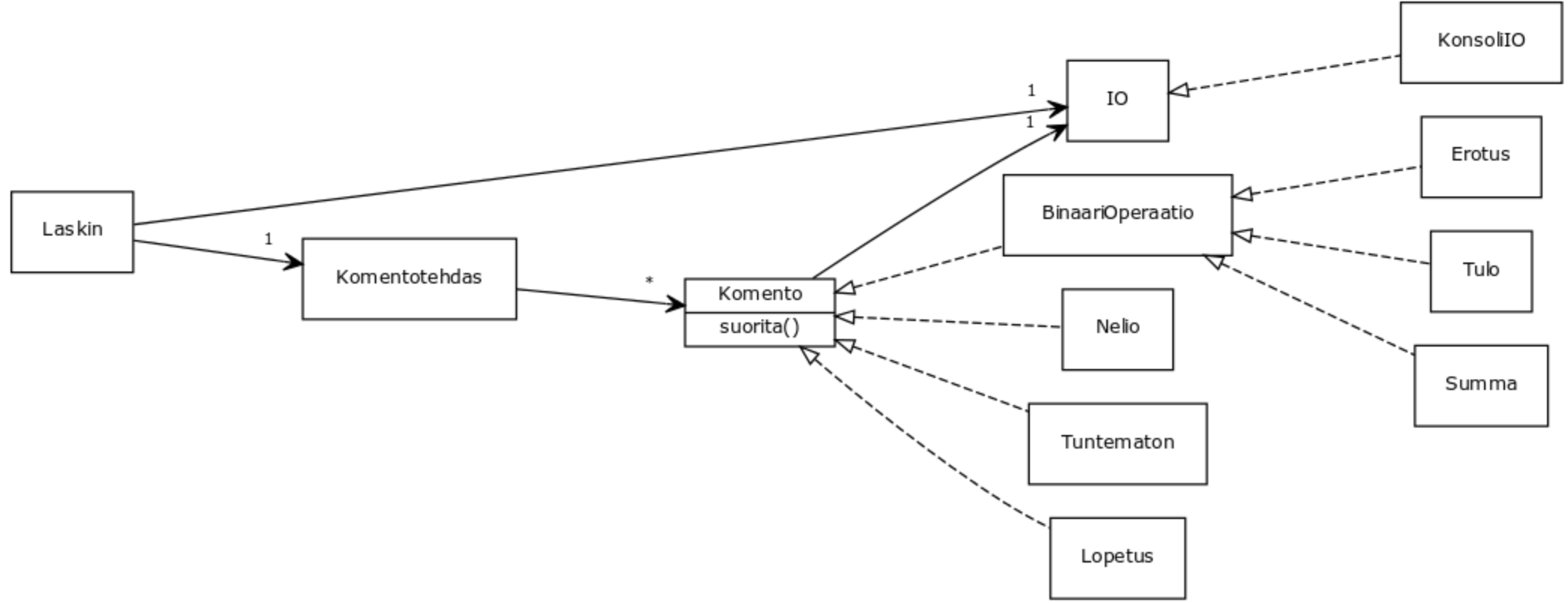
Hintana joustavuudelle on luokkien määrän kasvu. Nopealla vilkaisulla saattaakin olla vaikea havaita miten ohjelma toimii, varsinkaan jos ei ole vastaavaan tyyliin tottunut, mukaan on nimittäin piilotettu factory- ja command-suunnittelumallien lisäksi suunnittelumalli template method (kaksiparametrisen komennon toteutukseen).
Suunnittelumalli: template method [viikko 6]
Template method -suunnittelumalli sopii tilanteisiin, missä kahden tai useamman operaation suoritus on hyvin samankaltainen ja poikkeaa ainoastaan yhden tai muutaman operaatioon liittyvän askeleen kohdalla.
Summa- ja Tulo-komentojen suoritus on oleellisesti samanlainen:
- Lue luku1 käyttäjältä
- Lue luku2 käyttäjältä
- Laske operaation tulos
- Tulosta operaation tulos
Ainoastaan kolmas vaihe eli operaation tuloksen laskeminen eroaa summaa ja tuloa selvitettäessä.
Template methodin hengessä asia hoidetaan tekemällä abstrakti yliluokka, jonka metodi suorita toteuttaa koko komennon suorituslogiikan:
class BinaariOperaatio(ABC):
# ...
def suorita(self):
self.luku1 = int(self.io.lue("Luku 1:"))
self.luku2 = int(self.io.lue("Luku 2:"))
tulos = self.laske()
self.io.kirjoita(f"Vastaus: {tulos}")
@abstractmethod
def laske(self):
pass
Suorituslogiikan vaihtuva osa eli operaation laskun tulos on määritelty metodina laske, jota metodi suorita kutsuu.
Konkreettiset toteutukset Summa ja Tulo ylikirjoittavat metodin laske, määrittelemällä miten laskenta tietyssä konkreettisessa tilanteessa tapahtuu:
class Summa(BinaariOperaatio):
# ...
def laske(self):
return self.luku1 + self.luku2
Luokan metodi suorita on template-metodi, joka määrittelee suorituksen siten, että suorituksen eroava osa määritellään yliluokan metodina, jonka aliluokat ylikirjoittavat. Template-metodin avulla siis saadaan määriteltyä “geneerinen algoritmirunko”, jota voidaan aliluokissa erikoistaa sopivalla tavalla.
Strategy-suunnittelumalli on osittain samaa sukua template-metodin kanssa, siinä kokonainen algoritmi tai algoritmin osa korvataan erillisessä luokassa toteutetulla toteutuksella. Strategioita voidaan vaihtaa suorituksen aikana, template-metodissa tietty olio toimii samalla tavalla koko elinaikansa.
Lisää template method -suunnittelumallista täällä.
Toisteettomuus
Olemme käsitelleet koodin laatuattribuuteista kapselointia, koheesiota ja riippuvuuksien vähäisyyttä. Seuraavana vuorossa redundanssi eli toisteisuus.
Aloittelevaa ohjelmoijaa pelotellaan toisteisuuden vaaroista uran ensiaskelista alkaen, varmaan jokainen on kuullut varoituksen: älä copypastea koodia!
Alan piireissä toisteisuudesta varoittava periaate kuuluu don’t repeat yourself, ja siihen viitataan usein lyhenteellä DRY.
Ilmeisin toiston muoto koodissa on juuri copypaste ja se on usein helppo eliminoida esimerkiksi funktioiden tai metodien avulla. Kaikki toisteisuus ei ole yhtä ilmeistä ja monissa suunnittelumalleissa on kyse juuri hienovaraisempien toisteisuuden muotojen eliminoinnista, edellisessä esimerkissä template method -suunnittelumallia käyttävän luokan BinaariOperaatio motivaationa oli oikeastaan se, että sama käyttäjän interaktion hoitava koodi toistui luokissa Summa ja Tulo.
Moneen paikkaan kopioidun koodinpätkän ilmeisin ongelma on siinä, että jos kopioidusta koodista löytyy bugi tai sen toiminnallisuuden logiikkaa tulee muuttaa, on työlästä tehdä muutos moneen kohtaan. Yleensä moneen kohtaan kopioitu koodinpätkä on myös viite siitä että esim. koodin koheesiossa olisi parantamisen varaa.
DRY-periaate menee oikeastaan vielä paljon pelkkää koodissa olevaa toiston eliminointia pidemmälle. Kirjan Pragmatic programmer määritelmä every piece of knowledge must have a single, unambiguous, authoritative representation within a system viittaa siihen, että koodin lisäksi periaate tulisi ulottaa koskemaan järjestelmän muitakin osia, kuten tietokantaskeemaa, testejä, build-skriptejä ym.
Pragmatic programmerin määritelmän henkeä ei välttämättä pysty tavoittamaan täysin ilman konkreettista esimerkkiä. Oletetaan, että kehittämämme verkkokauppa otettaisiin käyttöön myös sellaisissa maissa, joissa ei käytetä rahayksikkönä euroa. Jos sovellus ei noudata DRY-periaatetta valuutan käsittelyn suhteen, on oletettavaa, että muutos vaatisi muutoksia useisiin eri kohtiin sovellusta. Jos taas valuutan käsittelyllä olisi single authoritive representation, esim. se olisi kapseloitu riittävän hyvin luokan Money vastuulle, niin muiden valuuttojen tuen lisääminen ei ehkä edellyttäisi muuta kuin yksittäisen luokan koodin modifiointia.
Hyvä vs. paha copypaste
Vaikka koodin, konfiguraatioiden, tietokantaskeeman yms. toisteettomuus on yleisesti ottaen hyvä asia, voi ajoittain olla järkevää ainakin ensin tehdä nopea copypasteen perustuva ratkaisu ja refaktoroida koodi tarvittaessa myöhemmin siistimmäksi.
Monissa tilanteissa nimittäin copypasten poistamisella on hinta, se saattaa muuttaa sovellusta monimutkaisemmaksi. Gutenberg-lukijan kohdalla alkuperäinen versio saattaisi olla täysin riittävä käyttöön, ja refaktorointi ei välttämättä olisi vaivan arvoinen. Mutta jos sovellukseen tulisi tarve useimpiin ehtoihin, ei sovelluksen alkuperäinen design siihen kunnolla taipuisi ja copypastea tulisi yhä suuremmat määrät.
Melko hyvä periaate onkin three strikes and you refactor, eli samankaltainen koodilogiikka kahdessa kohtaa on kutakuinkin ok, mutta jos se tulee kopioida vielä kolmanteen kohtaan, on parempi refaktoroida koodia siten, että copypaste saadaan eliminoitua.
Epätriviaalin copypasten poistaminen Strategy-patternin avulla [viikko 6]
Tarkastellaan Project Gutenbergistä löytyvien kirjojen sisällön analysointiin tarkoitettua luokkaa GutenbergLukija:
class GutenbergLukija:
def __init__(self, osoite):
self.rivit = []
data = request.urlopen(osoite)
for rivi in data:
self.rivit.append(rivi.decode("utf-8").strip())
def rivit(self):
palautettavat = []
for rivi in self.rivit:
palautettavat.append(rivi)
return palautettavat
def rivit_jotka_paattyvat_huutomerkkiin(self):
ehdot_tayttavat = []
for rivi in self.rivit:
if rivi.endswith("!"):
ehdot_tayttavat.append(rivi)
return ehdot_tayttavat
def rivit_joilla_sana(self, sana):
ehdot_tayttavat = []
for rivi in self.rivit:
if sana in rivi:
ehdot_tayttavat.append(rivi)
return ehdot_tayttavat
Luokalla on kolme metodia, kaikki kirjan rivit palauttava rivit sekä rivit_jotka_paattyvat_huutomerkkiin ja rivit_joilla_sana jotka toimivat kuten metodin nimi antaa ymmärtää.
Luokkaa käytetään seuraavasti:
def main():
osoite = "https://www.gutenberg.org/files/2554/2554-0.txt"
kirja = GutenbergLukija(osoite)
for rivi in kirja.rivit_joilla_sana("olut"):
print(rivi)
if __name__ == "__main__":
main()
Luokka on ohjelmoitu “perinteisellä” imperatiivisella tyylillä, kirjan rivejä käydään läpi for-lauseella ja kunkin rivin kohdalla tarkastetaan ehtolauseella onko rivi kyseisen metodin kriteerit täyttävä, esim. huutomerkkiin loppuva.
Luokan GutenbergLukija tarjoamat kolme kirjan sisällön hakemiseen tarkoitettua metodia ovat selvästi rakenteeltaan hyvin samantapaisia. Kaikki käyvät läpi jokaisen kirjan rivin ja palauttavat niistä osan (tai kaikki) metodin kutsujalle. Metodit eroavat sen suhteen, mitä kirjan riveistä ne palauttavat. Metodit ovat siis lähes copypastea, ne kuitenkin eroavat sen verran toisistaan, että copypasten eliminoiminen ei ole täysin suoraviivaista.
Jos mietitään metodien toimintaa, niin voidaan ajatella, että jokaisessa metodissa on oma strategiansa rivien palauttamiseen, ja strategiaa lukuunottamatta kaikki muu on samaa. Tämä onkin erinomainen paikka strategy-suunnittelumallin soveltamiseen. Jos eriytämme rivien valintastrategia omaksi luokakseen, voidaan selvitä ainoastaan yhdellä rivien läpikäynnin hoitavalla metodilla.
Toteutetaan valintastrategiasta vastaavat luokat niin, että ne toteuttavat metodin test. Metodin tulee palauttaa True, jos parametrina saatu rivi vastaa ehtoa, muutoin False. Aloitetaan toteuttamalla SisaltaaSanan-luokka:
class SisaltaaSanan:
def __init__(self, sana):
self.sana = sana
def test(self, rivi):
return self.sana in rivi
Ideana on luoda jokaista kirjojen erilaista hakuehtoa kohti oma ehdon tarkistava luokkansa. SisaltaaSanan-luokasta voi luoda olion seuraavasti:
ehto = SisaltaaSanan("olut")
Olion avulla voidaan tarkastella, sisältävätkö merkkijonot sanan olut:
ehto = SisaltaaSanan("olut")
ehto.test("internetin paras suomenkielinen olutsivusto on olutopas.info")
ehto.test("Python 3.9 julkaistiin 05.10.2020")
Ensimmäinen metodikutsuista palauttaisi True ja jälkimmäinen False.
Kirjasta voidaan palauttaa oikean ehdon täyttävät sanat lisäämällä luokalle GutenbergLukija metodi:
def rivit_jotka_tayttavat_ehdon(self, ehto):
palautettavat_rivit = []
for rivi in self.rivit:
if ehto.test(rivi):
palautettavat_rivit.append(rivi)
return palautettavat_rivit
ja sanan olut sisältävät rivit saadaan tulostettua seuraavasti:
for rivi in kirja.rivit_jotka_tayttavat_ehdon(SisaltaaSanan("olut")):
print(rivi)
Pääsemmekin sopivien ehto-luokkien määrittelyllä eroon alkuperäisistä rivien hakumetodeista. Sovellus tulee sikälikin huomattavasti joustavammaksi, että uusia hakuehtoja voidaan helposti lisätä määrittelemällä uusia luokkia, jotka toteuttavat test-metodin.
Ehdot voidaan esittää luokkien sijaan myös yksinkertaisemmassa muodossa, esimerkiksi funktioina tai lambdoina. Tutustutaan seuraavaksi hieman funktionaaliseen ohjelmointiin, jonka kulmakivenä on juuri funktioiden hyödyntäminen. Muokataan rivit_jotka_tayttavat_ehdon-metodia niin, että parametrina saatu ehto on kutsuttava arvo:
def rivit_jotka_tayttavat_ehdon(self, ehto):
palautettavat_rivit = []
for rivi in self.rivit:
if ehto(rivi):
palautettavat_rivit.append(rivi)
return palautettavat_rivit
Huomaa, kuinka ehto.test(rivi) muuttui muotoon ehto(rivi). Voimme nyt hyödyntää lambdaa ehdon antamiseen:
for rivi in kirja.rivit_jotka_tayttavat_ehdon(lambda rivi: "olut" in rivi):
print(rivi)
Lambda on ikään kuin funktion kompaktimpi esitys. Kuten funktiolla, myös lambdalla voi olla parametreja. Esimerkissä lambdalla on parametri rivi. Toisin kuin funktio, lambda määritellään aina yhdellä rivillä. Määritelty rivi suoritetaan ja sen arvo palautetaan ilman erilistä return-lausetta.
Lambdojen avulla on helppoa määritellä mielivaltaisia ehtoja. Seuraavassa tulostetaan kaikki rivit, joilla esiintyy jompi kumpi sanoista olut tai maito. Ehdon ilmaiseva lambda-lauseke on nyt määritelty selvyyden vuoksi omalla rivillään:
ehto = lambda rivi: "olut" in rivi or "maito" in rivi
for rivi in kirja.rivit_jotka_tayttavat_ehdon(ehto):
print(rivi)
Voimme myös toteuttaa funktioita, jotka palauttavat lambdoja:
def sisaltaa_sanan(sana):
return lambda rivi: sana in rivi
for rivi in kirja.rivit_jotka_tayttavat_ehdon(sisaltaa_sanan("olut")):
print(rivi)
Huomaa, kuinka kyseissä esimerkissä funktio sisaltaa_sanan muistuttaa tehdas-suunnittelumallin mukaisia tehdasmetodeja.
Refaktoroidaan vielä GutenbergLukija-luokkaa hyödyntämällä Pythonin funktionaalisen ohjelmoinnin työkalupakkia. Koska luokan metodeissa käsitellään paljon listoja, voimme hyödyntää funktiota map ja filter.
Funktiota map voi hyödyntää listan (tai minkä tahansa muun iteraattorin) alkioiden muokkaamiseen. Funktiolla on kaksi parametria. Ensimmäinen parametri on lambda (tai vastaava kutsuttavissa oleva arvo), joka saa parametriksi iteraattorin alkion ja palauttaa alkion uuden arvon. Toinen parametri on iteraattori, jonka alkioista muodostetaan lambdan avulla uusi iteraattori. map-funktio ei siis muuta parametrina saatua iteraattoria, vaan palauttaa uuden iteraattorin, johon on tehty halutut muokkaukset.
Voimme hyödyntää map-funktiota esimerkiksi GutenbergLukija-luokan konstruktorissa:
def __init__(self, osoite):
rivit_iterator = map(
lambda rivi: rivi.decode("utf-8").strip(),
request.urlopen(osoite)
)
self.rivit = list(rivit_iterator)
Huomaa, ettei map-funktio palauta listaa, vaan iteraattorin. Iteraattorin voi muuttaa listaksi helposti, list-funktion avulla.
Toinen hyödyllinen funktio listojen käsittelyyn on filter-funktio, jonka avulla listan (tai minkä tahansa muun iteraattorin) alkioita voidaan suodattaa. Funktiolla on kaksi parametria. Ensimmäinen paramateri on lambda (tai vastaava kutsuttavissa oleva arvo), joka saa parametriksi iteraattorin alkion ja palauttaa True, jos alkiota halutaan sisällyttää suodatettuun iteraattoriin, muutoin False. Toinen parametri on iteraattori, jonka alkioita suodatetaan. Kuten map-funktio, filter-funktio ei muuta parametrina saatua iteraattoria vaan palauttaa uuden iteraation, jonka alkiot on suodatettu annetulla ehdolla.
Hyvä käyttökohde filter-funktiolle on GutenbergLukija-luokan metodi rivit_jotka_tayttavat_ehdon:
def rivit_jotka_tayttavat_ehdon(self, ehto):
palautettavat_rivit_iterator = filter(ehto, self.rivit)
return list(palautettavat_rivit_iterator)
Voimme antaa filter-funktiolle suoraan parametrina saaduun ehdon.
Testattavuus
Tärkeä piirre hyvällä koodilla on sen testattavuus, eli koodi on helppo testata kattavasti yksikkö- ja integraatiotestein. Helppo testattavuus seuraa yleensä siitä, että koodi koostuu löyhästi kytketyistä, selkeän vastuun omaavista komponenteista.
Kääntäen, jos koodin kattava testaaminen on vaikeaa, on se usein seurausta siitä, että komponenttien vastuut eivät ole selkeät, ja niillä on liikaa riippuvuuksia.
Olemme pyrkineet jo kurssin ensimmäiseltä viikolta asti koodin hyvään testattavuuteen esim. purkamalla turhia riippuvuuksia riippuvuuksien injektoinnin avulla.
Selkeys
Perinteisesti ohjelmakoodin on ajateltu olevan väkisinkin kryptistä ja vaikeasti luettavaa. Esim. C-kielessä on tapana ollut kirjoittaa todella tiivistä koodia, jossa yhdellä rivillä on ollut tarkoitus tehdä mahdollisimman monta asiaa, metodikutsuja on vältetty tehokkuussyistä, muistinkäyttöä on optimoitu uusiokäyttämällä muuttujia ja “koodaamalla” dataa bittitasolla.
Ajat ovat muuttuneet ja nykyisen trendin mukaista on pyrkiä kirjoittamaan koodia, joka jo nimeämiskäytänteiden sekä rakenteen kautta ilmaisee mahdollisimman hyvin sen, mitä koodi tekee.
Selkeän nimennän lisäksi muita luettavan eli “puhtaan” koodin (engl. clean code) tunnusmerkkejä ovat jo monet meille entuudestaan tutut asiat, joita on listattu esim. täällä.
Miksi selkeän koodin kirjoittaminen on niin tärkeää, eikö riitä että koodari ymmärtää itse mistä koodissa on kyse? Tämä ei todellakaan riitä, sillä suurin osa, joidenkin arvioiden mukaan jopa 90% “ohjelmointiin” kuluvasta ajasta menee olemassa olevan koodin lukemiseen. Koodia, joko itsensä tai jonkun muun kirjoittamaa, on luettava debuggauksen yhteydessä sekä sovellusta laajennettaessa. On kovin tyypillistä että se oma aikoinaan niin selkeä koodi, ei sitten olekaan yhtä selkeää parin kuukauden kuluttua:

Code smell
Koodissa olevista epäilyttävistä piirteistä on ruvettu käyttämään nimitystä code smell eli koodihaju.
Martin Fowlerin määritelmää mukaillen koodihaju on helpohkosti huomattava merkki siitä että koodissa on jotain pielessä. Vaikka jopa aloitteleva ohjelmoija saattaa pystyä havaitsemaan koodihajun, sen takana oleva todellinen syy voi olla jossain syvemmällä, jopa ohjelman designissa. Koodihaju siis kertoo sen, että syystä tai toisesta koodin sisäinen laatu ei ole parhaalla mahdollisella tasolla.
Koodihajuja on hyvin monenlaisia ja monentasoisia. Muutamia esimerkkejä helposti tunnistettavista hajuista:
- Toisteinen koodi
- Liian pitkät metodit ja funktiot
- Luokat joissa on liikaa oliomuuttujia
- Luokat joissa on liikaa koodia
- Metodien liian pitkät parametrilistat
- Epäselkeät muuttujien, metodien tai luokkien nimet
- Kommentit
Oikeastaan kaikki näistä ovat merkkejä edellä listaamiemme hyvän koodin laatuattribuutteja heikentävistä ilmiöistä, esim. erittäin pitkä metodi todennäköisesti tarkoittaa, että metodin koheesio on huono, samoin luokka jossa on paljon koodia tai oliomuuttujia tarkoittaa suurella todennäköisyydellä että single responsibility -periaatetta ei noudateta. Jos luokan metodeilla on paljon parametreja, voi se kieliä siitä, että osa tiedoista on väärän luokan vastuulla, tai että metodin kuuluisi mielummin olla jossain toisessa luokassa.
Nykyään koodin kommentointia on hieman yllättäen alettu pitämään koodihajuna. Kyse on oikeastaan siitä, että koodi pitäisi lähtökohtaisesti kirjoittaa niin selkeäksi ja nimeämiskäytäntöjen osalta kommunikoivaksi, että kommentteja ei tarvita. Eli kommentit tulee säästää vain sellaisiin kohtiin, jossa samaa asiaa ole mahdollista ilmaista koodin muotoilulla ja paremmalla nimeämisellä.
Otetaan pari esimerkkiä hieman vähemmän ilmeisistä koodihajuista.
Primitive obsession tarkoittaa tilannetta, missä jossa jokin konkreettinen käsite esim. osoite tai rahamäärä esitetään primitiivityyppisten muuttujien (esim. merkkijono tai kokonaisluku) avulla, sen sijaan että määriteltäisiin luokka asian esittämiseen.
Nimellä shotgun surgery kuvataan tilannetta, missä yhden loogisen asian muuttaminen, laajentaminen tai siihen tehtävä bugikorjaus aiheuttaakin sarjan muutoksia myös todella moneen muuhun paikkaan koodia. Tämä on oire siitä, että toiminnallisuutta ei ole kapseloitu riittävän hyvin yhteen koodimoduuliin, eli kyseessä on DRY-periaatetta rikkova design.
Internetistä löytyy suuret määrät listoja koodihajuista, esim. seuraavat
Refaktorointi
Lääke sovelluksen koodin sisäisen laadun ongelmiin on refaktorointi eli muutos koodin, esimerkiksi luokan rakenteeseen, joka kuitenkin pitää sen toiminnallisuuden ennallaan.
Refaktoroinnin systemaattisena koodin sisäisen laadun parannuskeinona toi suurten massojen tietoisuuteen Martin Fowlerin vuonna 2000 julkaisema kirja Refactoring. Kirjan toinen, kokonaan uudelleenkirjoitettu painos ilmestyi 2018.
Fowlerin kirja listaa lukuisia koodin rakennetta parantavia, tiettyihin tilanteisiin sopivia refaktorointioperaatioita. Kirjan listaamat refaktoroinnit löytyvät myös internetistä. Seuraavassa muutamia esimerkkejä
- Rename variable/method/class, uudelleennimetään huonosti nimetty asia
- Extract method, jaetaan liian pitkä metodi erottamalla siitä pienempiä metodeja
- Move field/method, siirretään oliomuuttuja tai metodi toiseen luokkaan
- Extract superclass, luodaan yliluokka, johon siirretään osa luokan toiminnallisuudesta
Melko monissa ei niin suoraviivaisissa refaktorointioperaatioissa, epäoptimaalinen koodi refaktoroidaan paremmaksi soveltamalla jotain suunnittelumallia. Joshua Kerievsky on kirjoittanut aiheesta mainion kirjan Refactoring to patterns.
Aiemmissa esimerkeissä näimme tämän kaltaisia refaktorointeja, esim.
- Tilien koronmaksustrategia, replace conditional with polymorfism
- Tilien luominen, replace constructor with factory method
- Laskimen komennot, replace method with method object
- Laskimen binäärioperaatiot, form template method.
Refaktoroinnin melkein ehdoton edellytys (poislukien yksinkertaiset automaattisesti suoritettavat refaktoroinnit, kuten rename variable) on kattavien testien olemassaolo. Refaktoroinnissa on tarkoitus ainoastaan parantaa luokan tai komponentin sisäistä rakennetta, ulospäin näkyvän toiminnallisuuden pitäisi pysyä muuttumattomana, ja tästä varmistuminen ilman testejä on työlästä.
Refaktoroinnissa kannattaa ehdottomasti edetä pienin askelin eli yksi hallittu muutos kerrallaan. Testit on syytä suorittaa jokaisen refaktorointioperaation jälkeen, jotta mahdollinen regressio, eli aiemmin toimineen koodin hajoaminen huomataan mahdollisimman nopeasti.
Refaktorointia kannattaa tehdä lähes koko ajan. Kun koodin sisäinen laatu säilyy siistinä, on koodin laajentaminen miellyttävää ja pienien refaktorointioperaatioiden tekeminen suhteellisen vaivatonta. Jos koodin sisäinen laatu pääsee rapistumaan, muuttuu sen laajentaminen hitaaksi ja myös refaktoroinnin suorittaminen muuttuu koko ajan työläämmäksi. Joillain ohjelmistokehitystiimeillä onkin definition of doneen kirjattu, että valmiin määritelmä sisältää sen, että koodi on refaktoroitu riittävän siistiksi. Siisteyttä saatetaan valvoa esim. pull requesteina tehtävänä katselmointina.
Osa refaktoroinneista, esim. metodien tai luokkien uudelleennimeäminen tai pitkien metodien jakaminen pienemmiksi on helppoa. Aina ei näin kuitenkaan ole. Joskus on tarve tehdä suurempien mittaluokkien refaktorointeja, joissa ohjelman rakenne eli arkkitehtuuri muuttuu. Tällaiset refaktoroinnit saattavat kestää päiviä tai jopa viikkoja ja niiden suorittaminen siten, että koodi säilyy koko ajan toimivana on jo kohtuullisen haastavaa.
Tekninen velka
Koodi ei ole aina sisäiseltä laadultaan optimaalista, ja joskus on jopa asiakkaan kannalta tarkoituksenmukaista tehdä vähemmän laadukasta koodia. Huonoa suunnittelua tai/ja ohjelmointia on ruvettu kuvaamaan käsitteellä tekninen velka (engl. technical debt).
Oikoteitä ottamalla tehdyllä ohjelmoinnilla saadaan ehkä nopeasti aikaan jotain toiminnallisuutta, mutta hätäinen ratkaisu tullaan maksamaan korkoineen takaisin myöhemmin jos ohjelmaa on tarkoitus laajentaa. Käytännössä käy siis niin, että koodiin kertyneet sisäisen laadun ongelmat, eli tekninen velka alkaa hidastamaan kehitystyön etenemistä, ja uusien ominaisuuksien toteuttamisesta tulee koko ajan hankalammaksi ja kalliimmaksi.
Toisaalta jos korkojen maksun aikaa ei koskaan tule, eli ohjelma on esimerkiksi pelkkä prototyyppi tai sitä ei koskaan oteta käyttöön, on teknisen velan ottaminen asiakkaan kannalta kannattava ratkaisu.
Osassa 2 käsiteltiin lean startup -ideologian mukaista tapaa ohjelmiston uusien ominaisuuden hyödyllisyyden validointiin rakentamalla ominaisuuden toteuttama minimal viable product (MVP), eli juuri ja juuri riittävä ratkaisu, jonka avulla ominaisuuden käyttökelpoisuutta voidaan testata. Kuten nimikin jo antaa ymmärtää, MVP on luonteeltaan sellainen rakennelma, jonka tekemisessä otetaan tietoisesti teknistä velkaa. Jos ominaisuus osoittautuu halutuksi, tekninen velka maksetaan pois tekemällä toiminnallisuudelle robustimpi toteutus.
Lyhytaikaisen teknisen velan ottaminen voi joskus olla jopa välttämätöntä. Esimerkiksi markkinatilanteen takia saattaa olla oleellista saada tuote kuluttajille mahdollisimman nopeasti, tai muuten tilaisuus saattaa mennä kokonaan ohi. Startup-yrityksillä tilanne voi olla sellainen, että firma joutuu valitsemaan teknisen velan ja varman rahojen loppumisen välillä. Tekemällä jotain nopeasti huonolla sisäisellä laadulla firma saattaa pystyä keräämään riittävästi rahoitusta jatkaakseen toimintaansa. Tämänkaltaisissa tilanteissa otetaan tietoisesti teknistä velkaa ja sovelluksen koodin huonosta laadusta ja testauksen puuttumisesta huolehditaan myöhemmin.
Tekninen velka ei siis ole pelkästään paha asia, vaan strategisesti käytettynä hyväkin väline, aivan kuten esim. asuntolaina - ilman lainaa kaikilla ei ole varaa omistusasuntoon. On kuitenkin oleellista mitoittaa lainan määrä oikein, muuten seurauksena saattaa olla luottokelpoisuuden menetys.
Teknisen velan takana voi siis olla monenlaisia syitä, esim. holtittomuus, osaamattomuus, tietämättömyys tai tarkoituksella tehty päätös. Martin Fowler jakaa teknisen velan neljään eri luokkaan:
- Reckless and deliberate: “we do not have time for design”
- Reckless and inadverent: “what is layering”?
- Prudent and inadverent: “now we know how we should have done it”
- Prudent and deliberate: “we must ship now and will deal with consequences”
Luokkien 1 ja 2, joista Fowler käyttää termiä reckless eli holtiton tai uhkarohkea, voidaan ajatella olevan huonoa teknistä velkaa. Toinen syntyy tarkoituksella, eli ajatellen että ei ole aikaa laadulle, toinen taas syntyy osaamattomuuden takia.
Luokat 3 ja 4 ovat harkinnan alla (engl. prudent) syntynyttä teknistä velkaa. Luokka 4 on juurikin tilanne, jossa ollaan esim. tekemässä MVP:tä, tai jonkun pakon takia koodi on saatava julkaistua heti ja seuraukset päätetään hoitaa myöhemmin. Luokka 3 on kovin yleinen tilanne, ohjelmistoa suunniteltiin ja rakennettiin parhaiden aikomusten mukaan, mutta vasta paljon myöhemmin, kun arkkitehtuuri ja design on jo lyöty lukkoon, opitaan sovelluksen luonteesta sen verran, että tiedetään kuinka sovellus olisi tullut suunnitella. Tälläinen tilanne saatetaan päätyä ratkaisemaan refaktoroimalla sovelluksen arkkitehtuuri paremmin tarpeita vastaavaksi.
Lisää suunnittelumalleja [viikko 6]
Tutustutaan osan lopuksi vielä muutamaan uuteen suunnittelumalliin.
Esimerkki Dekoroitu pino [viikko 6]
Olemme toteuttaneet asiakkaalle pinon:
class Pino:
def __init__(self):
self.alkiot = []
def push(self, alkio):
self.alkiot.append(alkio)
def pop(self):
return self.alkiot.pop()
def empty(self):
return len(self.alkiot) == 0
def main():
pino = Pino()
print("Pinotaan, tyhjä lopettaa:")
while True:
pinoon = input()
if not pinoon:
break
pino.push(pinoon)
while not pino.empty():
print(pino.pop())
if __name__ == "__main__":
main()
Asiakkaamme haluaa pinosta muutaman uuden version:
KryptattuPinojossa alkiot talletetaan pinoon kryptattuina, alkiot tulevat pinosta ulos normaalistiLokiPinojossa tieto pinoamisoperaatioista ja niiden parametreista ja paluuarvoista talletetaan lokiinPrepaidPinojoka lakkaa toimimasta kun sillä on suoritettu konstruktoriparametrina määritelty määrä operaatioita
On lisäksi toteutettava kaikki mahdolliset kombinaatiot:
KryptattuLokiPinoLokiKryptattuPino(erona edelliseen se että lokiin ei kirjata parametreja kryptattuna)KryptattuPrepaidPinoKryptattuLokiPrepaidPinoLokiPrepaidPino
Alkaa kuulostaa pahalta varsinkin kun Product Owner vihjaa, että seuraavassa sprintissä tullaan todennäköisesti vaatimaan lisää versioita pinosta, mm. ÄänimerkillinenPino, RajallisenkapasiteetinPino ja tietysti kaikki kombinaatiot tarvitaan myös…
Onneksi suunnittelumalli dekoraattori (engl. decorator) sopii juuri tilanteeseen! Luodaan pinon kolme uutta versiota dekoroituina pinoina. Tarkastellaan ensin PrepaidPinoa:
class PrepaidPino:
def __init__(self, pino, krediitteja):
self.pino = pino
self.krediitteja = krediitteja
def kuluta_krediitti(self):
if self.krediitteja == 0:
raise Exception("Pinossa ei ole enää käyttöoikeutta")
self.krediitteja = self.krediitteja - 1
def push(self, alkio):
self.kuluta_krediitti()
self.pino.push(alkio)
def pop(self):
self.kuluta_krediitti()
return self.pino.pop()
def empty(self):
self.kuluta_krediitti()
return self.pino.empty()
PrepaidPino-luokka sisältää pinon, jonka se saa konstruktorin parametrina. PrepaidPino-luokka käyttää sisältämäänsä pinoa tallettamaan kaikki alkionsa. Eli jokainen PrepaidPino-luokan operaatio delegoi operaation toiminnallisuuden toteuttamisen sisältämälleen pinolle.
PrepaidPino luodaan seuraavalla tavalla:
pino = PrepaidPino(Pino(), 5)
Eli luodaan normaali Pino ja annetaan se PrepaidPino-luokalle konstruktoriparametrina yhdessä pinon krediittien kanssa.
Kahden muun pinon toteutukset ovat seuraavanlaiset:
class KryptattuPino:
def __init__(self, pino):
self.pino = pino
def dekryptaa(self, alkio):
dekryptattu = ""
merkkijono_alkio = str(alkio)
for i in range(0, len(merkkijono_alkio)):
dekryptattu = dekryptattu + chr(ord(merkkijono_alkio[i]) - 1)
return dekryptattu
def kryptaa(self, alkio):
kryptattu = ""
merkkijono_alkio = str(alkio)
for i in range(0, len(merkkijono_alkio)):
kryptattu = kryptattu + chr(ord(merkkijono_alkio[i]) + 1)
return kryptattu
def push(self, alkio):
self.pino.push(self.kryptaa(alkio))
def pop(self):
return self.dekryptaa(self.pino.pop())
def empty(self):
return self.pino.empty()
class LokiPino:
def __init__(self, pino, loki):
self.pino = pino
self.loki = loki
def push(self, alkio):
self.loki.kirjoita(f"Push: {alkio}")
self.pino.push(alkio)
def pop(self):
alkio = self.pino.pop()
self.loki.kirjoita(f"Pop: {alkio}")
return alkio
def empty(self):
onko_tyhja = self.pino.empty()
self.loki.kirjoita(f"Empty: {onko_tyhja}")
return onko_tyhja
Periaate on sama, pinodekoraattorit LokiPino ja KryptattuPino delegoivat kaikki operaationsa sisältämilleen Pino-olioille. LokiPino kirjoittaa merkinnän jokaisesta pinoon kohdistuvasta operaatiosta. KryptattuPino taas kryptaa alkeellista algoritmia käyttäen jokaisen pinoon laitettavan merkkijonon ja dekryptaa pinosta otettavat merkkijonot takaisin selkokielisiksi.
Voimme muodostaa pinon, joka kirjoittaa merkinnän pinon operaatioista sekä kryptaa pinon alkiot seuraavasti:
class KonsoliLoki:
def kirjoita(self, viesti):
print(viesti)
loki = KonsoliLoki()
pino = KryptattuPino(LokiPino(Pino(), loki))
Dekoroinnin avulla saamme siis suhteellisen vähällä ohjelmoinnilla pinolle paljon erilaisia ominaisuuskombinaatioita. Jos olisimme yrittäneet hoitaa kaiken normaalilla perinnällä, olisi luokkien määrä kasvanut eksponentiaalisesti eri ominaisuuksien määrän suhteen ja uusiokäytöstäkään ei olisi tullut mitään.
Dekorointi siis ei oleellisesti ole perintää vaan delegointia, jälleen kerran oliosuunnitteun periaate “favour composition over inheritance” on näyttänyt voimansa.
Lisää dekoraattori-suunnittelumallista esim. täällä
Pinotehdas [viikko 6]
Eri ominaisuuksilla varustettujen pinojen luominen on käyttäjän kannalta hieman ikävää. Tehdään luomista helpottamaan pinotehdas:
class Pinotehdas:
def prepaid_pino(self, krediitit):
return PrepaidPino(Pino(), krediitit)
def loki_pino(self, loki):
return LokiPino(Pino(), loki)
def kryptattu_pino(self):
return KryptattuPino(Pino())
def kryptattu_prepaid_pino(self, krediitit):
return KryptattuPino(self.prepaid_pino(krediitit))
def kryptattu_loki_pino(self, loki):
return KryptattuPino(self.loki_pino(loki))
def prepaid_kryptattu_loki_pino(self, krediitit, loki):
return PrepaidPino(self.kryptattu_loki_pino(loki), krediitit)
# monta monta muuta rakentajaa...
Tehdasluokka on ikävä ja sisältää hirveän määrän metodeja. Jos pinoon lisätään vielä ominaisuuksia, tulee factory karkaamaan käsistä.
Pinon luominen on kuitenkin tehtaan ansiosta helppoa:
tehdas = Pinotehdas()
omapino = tehdas.kryptattu_prepaid_pino(100)
Kuten huomaamme, ei factory-suunnittelumalli ole tilanteeseen ideaali. Kokeillaan sen sijaan seuraavaksi rakentaja (engl. builder) -suunnittelumallia.
Pinorakentaja [viikko 6]
Rakentaja-suunnittelumalli sopii tilanteeseemme erittäin hyvin. Pyrkimyksenämme on mahdollistaa pinon luominen seuraavaan tyyliin:
rakenna = Pinorakentaja()
pino = rakenna.prepaid(10).kryptattu().pino()
Rakentajan metodinimet ja rakentajan muuttujan nimi on valittu mielenkiintoisella tavalla. On pyritty mahdollisimman luonnollista kieltä muistuttavaan ilmaisuun pinon luonnissa. Kyseessä onkin oikeastaan DSL (engl. domain specific language) pinojen luomiseen.
Luodaan ensin rakentajasta perusversio, joka soveltuu vasta normaalien pinojen luomiseen:
rakenna = Pinorakentaja()
pino = rakenna.pino()
Saamme rakentajan ensimmäisen version toimimaan seuraavasti:
class Pinorakentaja:
def __init__(self):
self.pino_olio = Pino()
def pino(self):
return self.pino_olio
Eli kun Pinorakentaja-olio luodaan, rakentaja luo pinon. Rakentajan “rakennusvaiheen alla” olevan pinon voi pyytää rakentajalta kutsumalla metodia pino.
Laajennetaan nyt rakentajaa siten, että voimme luoda prepaidpinoja seuraavasti:
rakenna = Pinorakentaja()
pino = rakenna.prepaid(10).pino()
Jotta edellinen ei aiheuttaisi syntaksivirhettä, tulee rakentajalle lisätä metodi, jonka signatuuri on prepaid(self, krediitit). Eli jotta metodin tuloksena olevalle oliolle voitaisiin kutsua metodia pino, on metodin prepaid palautettava rakentaja. Rakentajamme runko laajenee siis seuravasti:
class Pinorakentaja:
def __init__(self, pino = Pino()):
self.pino_olio = pino
def prepaid(self, krediitit):
# ???
def pino(self):
return self.pino_olio
Rakentaja siis pitää oliomuuttujassa rakentumassa olevaa pinoa. Kun kutsumme rakentajalle metodia prepaid ideana on, että rakentaja dekoroi rakennuksen alla olevan pinon prepaid-pinoksi. Metodi palauttaa uuden Pinorakentaja-olion, jolle se antaa konstruktorin parametrina dekoroidun pinon. Tämä mahdollistaa sen, että metodikutsun jälkeen päästään edelleen käsiksi työn alla olevaan pinoon. Koodi siis seuraavassa:
class Pinorakentaja:
def __init__(self, pino = Pino()):
self.pino_olio = pino
def prepaid(self, krediitit):
return Pinorakentaja(PrepaidPino(self.pino_olio, krediitit))
def pino(self):
return self.pino_olio
Samalla periaatteella lisätään rakentajalle metodit, joiden avulla työn alla oleva pino saadaan dekoroitua lokipinoksi tai kryptaavaksi pinoksi:
class Pinorakentaja:
def __init__(self, pino = Pino()):
self.pino_olio = pino
def prepaid(self, krediitit):
return Pinorakentaja(PrepaidPino(self.pino_olio, krediitit))
def kryptattu(self):
return Pinorakentaja(KryptattuPino(self.pino_olio))
def loggaava(self, loki):
return Pinorakentaja(LokiPino(self.pino_olio, loki))
def pino(self):
return self.pino_olio
Rakentajan koodi voi vaikuttaa aluksi hieman hämmentävältä.
Rakentajaa siis käytetään seuraavasti:
rakenna = Pinorakentaja()
pino = rakenna.kryptattu().prepaid(10).pino()
Tässä pyydettiin rakentajalta kryptattu prepaid-pino, jossa krediittejä on 10.
Vastaavalla tavalla voidaan luoda pinoja muillakin ominaisuuksilla:
rakentaja = Pinorakentaja()
pino1 = rakentaja.pino(); # luo normaalin pinon
pino2 = rakentaja.kryptattu().loggaava(loki).prepaid.pino() # luo sen mitä odottaa saattaa!
Huomaa, että rakentajan metodikutsut luovat aina uuden rakentajan, joten edellistä rakentajaa ei muokata. Tämä estää potentiaaliset bugit, jotka voisi syntyä esimerkiksi seuraavassa koodissa:
rakentaja = Pinorakentaja()
kryptattu_rakentaja = rakentaja.kryptattu()
kryptattu_loki_rakentaja = kryptattu_rakentaja.loggaava(loki)
kryptattu_pino = kryptattu_rakentaja.pino()
kryptattu_loki_pino = kryptattu_loki_rakentaja.pino()
Jos metodit eivät loisi aina uutta rakentajaa, vaan käyttäisivät samaa viitettä, esimerkin koodissa kryptattu_rakentaja rakentaisikin lokiin kirjoittavan kryptatun pinon. Tämä olisi erittäin hämmentävää ja synnyttäisi helposti hankalasti debugattavia bugeja. Kyseessä on erittäin hyödyllinen ja laajalti käytössä oleva periaate, josta käytetään englannin kielistä nimitystä immutability. Periaatteen perusajatus on se, että objekteja muokkaavien metodien ja funktioiden ei tulisi tehdä muokkauksia suoraan saatuun viitteeseen, vaan palauttaa viite uuteen objektiin, joka sisältää halutut muutokset. Esimerkiksi aina uuden iteraattorin palauttavat funktiot map ja filter noudattavat tätä periaatetta.
Rakentajan toteutus perustuu tekniikkaan nimeltään method chaining eli metodikutsujen ketjutukseen. Metodit, jotka ovat muuten luonteeltaan sellaisia että ne eivät palauta mitään arvoa, onkin laitettu palauttamaan rakentajaolio. Tämä taas mahdollistaa metodin kutsumisen toisen metodin palauttamalle rakentajalle, ja näin metodikutsuja voidaan ketjuttaa peräkkäin mielivaltainen määrä. Metodiketjutuksen motivaationa on yleensä saada olion rajapinta käytettävyydeltään mahdollisimman luonnollisen kielen kaltaiseksi DSL:ksi.
Ohjelmistolisenssit
Lue täältä Akira Taguchin ohjelmistolisenssejä käsittelevä teksti.